今天我们就结合官方技术报告,把v4的核心架构、基础设施、预训练和后训练的方法一次性梳理清楚。
这篇技术报告很坦诚:不仅把架构全盘公开,还如实写明 ——Kimi K2.6、GLM-5.1 部分结果为空是因为 API 繁忙调不通,GPT-5.4 没测 1M 上下文是因为 API 故障,甚至大方承认对比 GPT-5.4、Gemini-3.1-Pro 仍有 3–6 个月差距,不吹不掩,让人好感度拉满。
技术报告的最后,DeepSeek 也列出了接下来的三大未来方向,很有前瞻性:
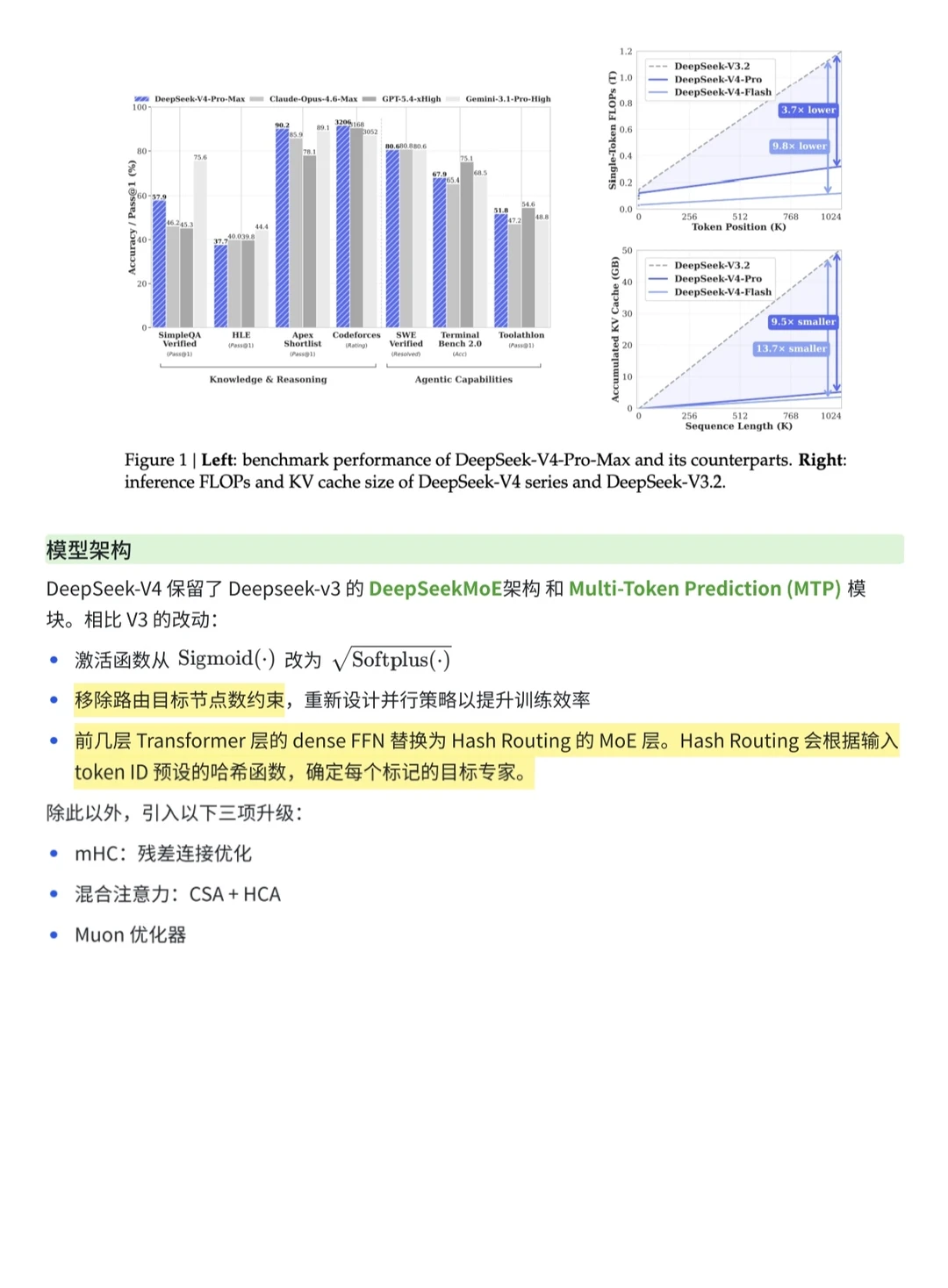
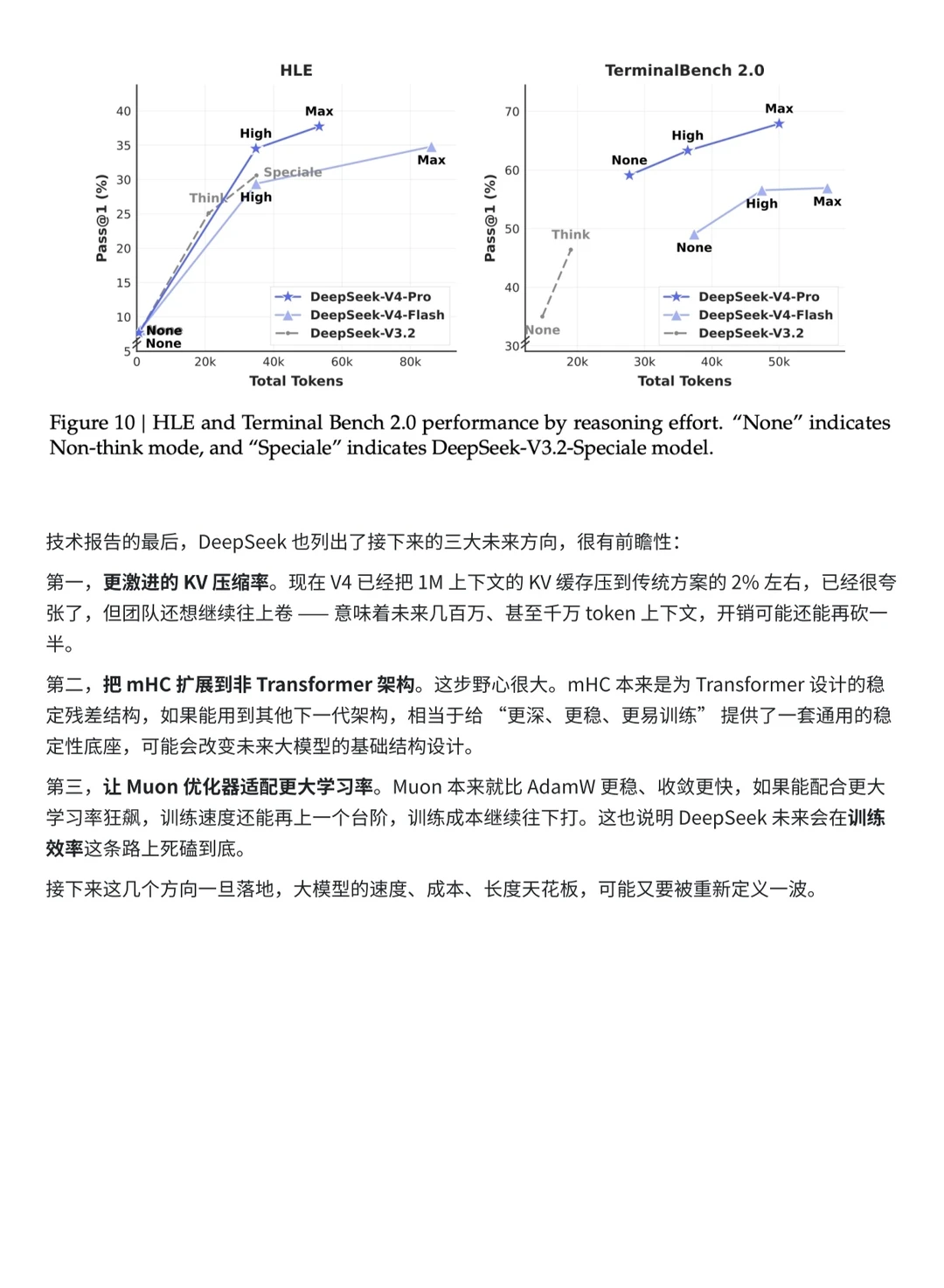
1️⃣更激进的 KV 压缩率。现在 V4 已经把 1M 上下文的 KV 缓存压到传统方案的 2% 左右,已经很夸张了,但团队还想继续往上卷 —— 意味着未来几百万、甚至千万 token 上下文,开销可能还能再砍一半。
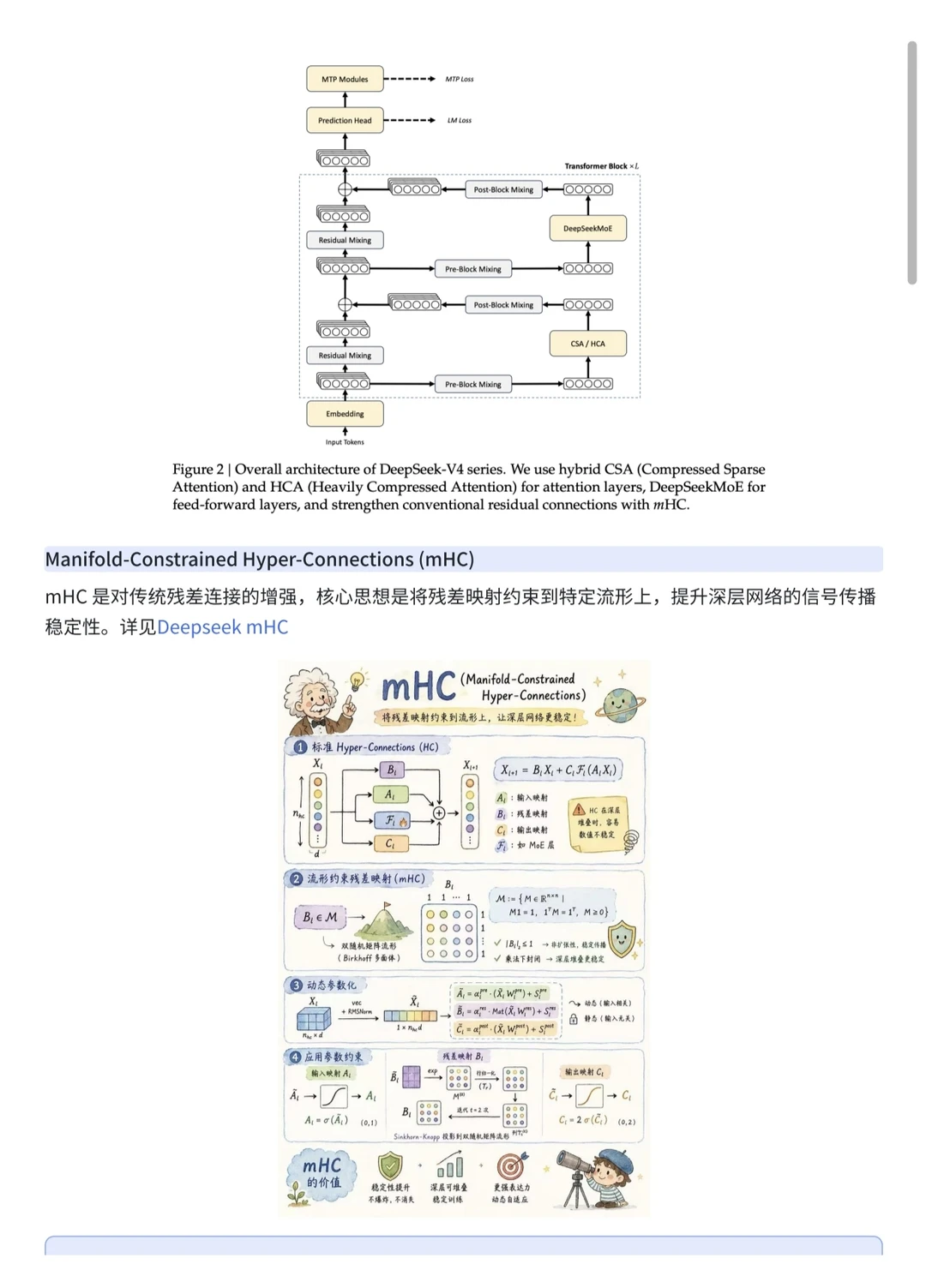
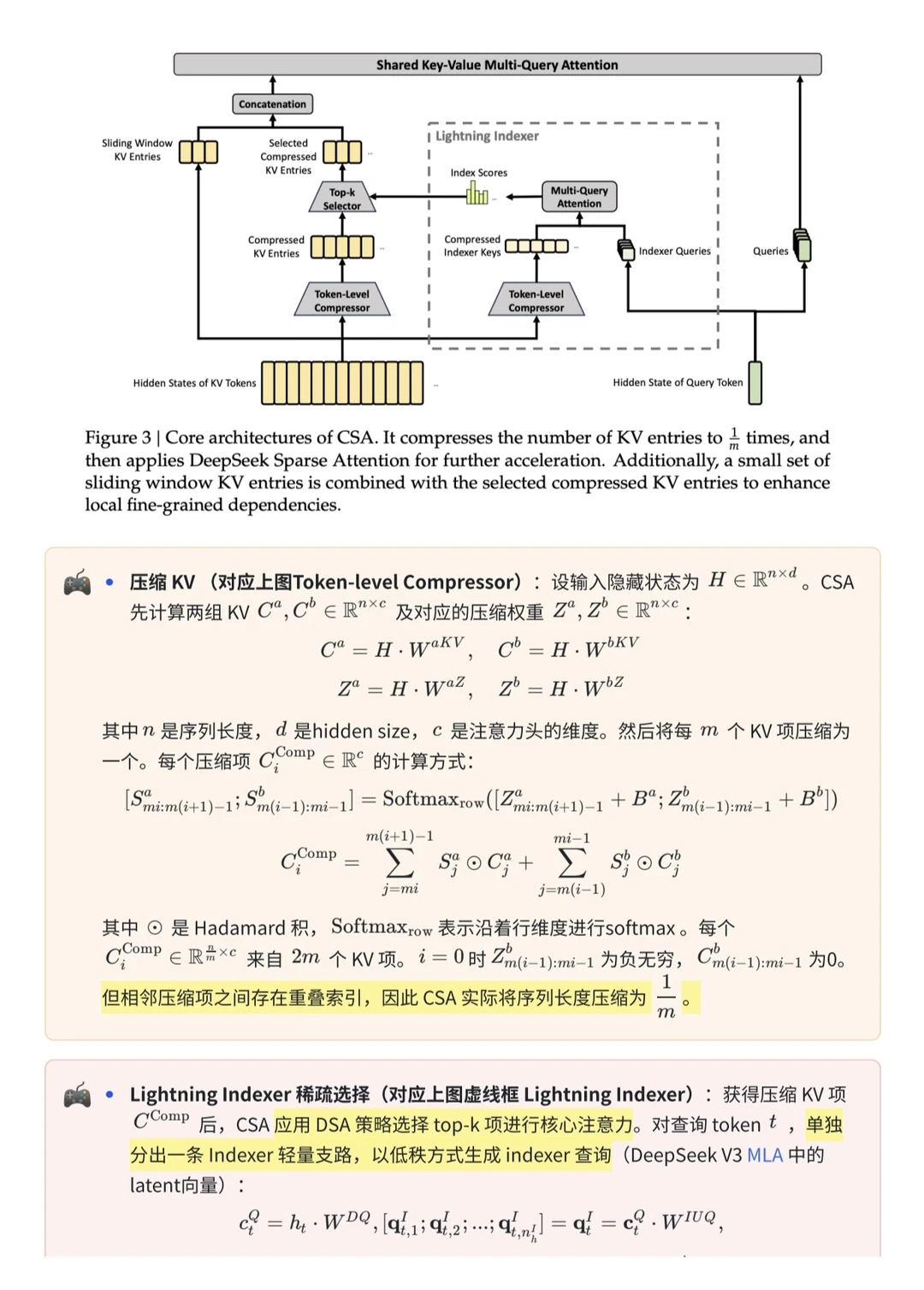
2️⃣把 mHC 扩展到非 Transformer 架构。这步野心很大。mHC 本来是为 Transformer 设计的稳定残差结构,如果能用到其他下一代架构,相当于给 “更深、更稳、更易训练” 提供了一套通用的稳定性底座,可能会改变未来大模型的基础结构设计。
3️⃣让 Muon 优化器适配更大学习率。Muon 本来就比 AdamW 更稳、收敛更快,如果能配合更大学习率狂飙,训练速度还能再上一个台阶,训练成本继续往下打。这也说明 DeepSeek 未来会在训练效率这条路上死磕到底。
接下来这几个方向一旦落地,大模型的速度、成本、长度天花板,可能又要被重新定义一波。