【拆解 AI Agent 安全架构:为什么 Harness 必须剥离出沙箱】
快速阅读:本文探讨了 AI Agent 运行架构的核心抉择:是将控制环(Harness)放在沙箱内,还是放在沙箱外。作者主张将 Harness 剥离至沙箱之外,通过虚拟化文件系统接口,在保持模型原有工具使用习惯的同时,实现凭证隔离与多用户记忆共享。
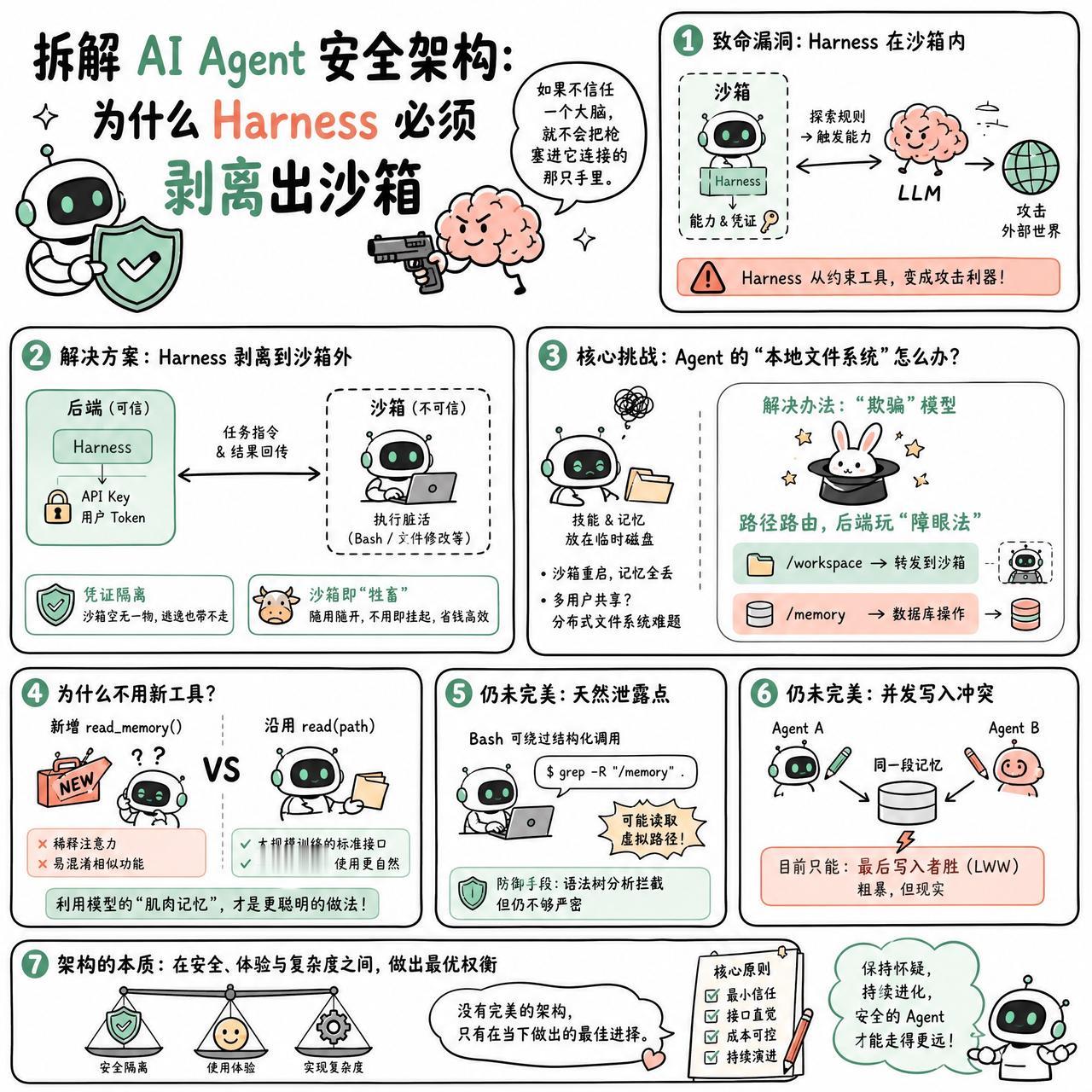
如果你不信任一个大脑,就不会把枪塞进它连接的那只手里。
在构建 Agent 时,很多人会把控制环(Harness)和它要操作的代码一起丢进沙箱。这听起来很安全,但其实逻辑上有个致命的漏洞:如果 Harness 拥有某些 LLM 无法直接实现的能力,而 LLM 又能通过特定条件触发这些能力,那么 LLM 迟早会摸清这些规则并执行它们。这时候,Harness 就不再是约束工具,反而成了 LLM 攻击外部世界的延伸。
有观点认为,即便 Harness 是你自己写的,也别指望它能完全免疫风险,毕竟代码总有 Bug,而 LLM 是天生的漏洞挖掘机。
所以,要把 Harness 挪到沙箱外面。
把控制环放在后端,沙箱只负责执行那些“脏活”——比如运行 Bash 命令或修改文件。这样做有两个好处。首先是凭证隔离,API Key 和用户 Token 留在后端,沙箱里空无一物,即便 Agent 逃逸了,也带不走任何东西。其次是沙箱可以变成“牲畜”,随用随开,不用时直接挂起,省钱且高效。
但问题来了,一旦 Harness 搬走了,Agent 赖以生存的“本地文件系统”怎么办?
Agent 习惯了通过 `read` 或 `write` 来处理技能(Skills)和记忆(Memories)。如果这些东西全在沙箱的临时磁盘里,沙箱一重启,记忆就全丢了。如果想让多个用户共享记忆,还得面对分布式文件系统那堆令人头秃的并发冲突问题。
解决办法是“欺骗”模型。
通过路径路由,让 Agent 觉得自己在操作文件系统,其实后端在玩“障眼法”。当路径指向 `/workspace`,请求被转发到沙箱;当路径指向 `/memory`,请求则变成了一次数据库操作。
这种做法比直接给 Agent 增加 `read_memory` 这种新工具要聪明得多。因为模型是在大规模的工具调用数据上训练出来的,它对 `read(path)` 这种标准接口有着极强的直觉。增加新工具会稀释模型的注意力,甚至让它在面对相似功能时产生困惑。
当然,这套架构还没到完美的地步。
比如 Bash 命令就是一个天然的泄露点。Agent 可能会绕过结构化的工具调用,直接在 Bash 里尝试 `grep` 那些虚拟出来的路径。虽然可以用语法树分析来拦截,但总归是不够严密的。
还有一个更难的问题:当两个 Agent 同时修改同一段记忆时,到底该听谁的?目前只能用“最后写入者胜”这种粗暴的方式。
这种权衡本身就是架构的本质。
mendral.com/blog/agent-harness-belongs-outside-sandbox