全面剖析 Linux 文件系统
Linux文件系统其实没那么玄,它就是一层一层套起来的。
我最近看内核源码、搭测试环境、跑`strace`跟踪`open()`调用,才真正摸到点门道。
不是靠背概念,是靠看它怎么一步步把`/home/user/a.txt`变成硬盘上几个扇区的。
普通人翻文档容易晕,因为一上来就讲VFS、inode、dentry,全是名词。
其实你只要记住一件事:Linux里所有“能打开的东西”,都得走同一套流程。
`cat /proc/cpuinfo`、`dd if=/dev/sda1 of=img`、`ls /sys/class/net/`,全靠那七个系统调用撑着。
`open()`返回一个数字,比如3。这个3不是随便编的,是当前进程里最小的空闲fd。
关掉0、1、2(标准输入输出错误),下次`open()`就一定返回3。
`read()`时内核先查page cache,有就直接拷贝;没有才发bio去读硬盘;读完还要更新`f_pos`,下一次继续从新位置读。
VFS不是包装层,是翻译官。
用户调`read(fd, buf, 1024)`,VFS找到对应的`struct file`,再找到它背后`struct inode`,再调`inode->i_fop->read_iter()`。
ext4就执行`ext4_file_read_iter()`,XFS就执行`xfs_file_read_iter()`,代码完全不同,但对上层完全透明。
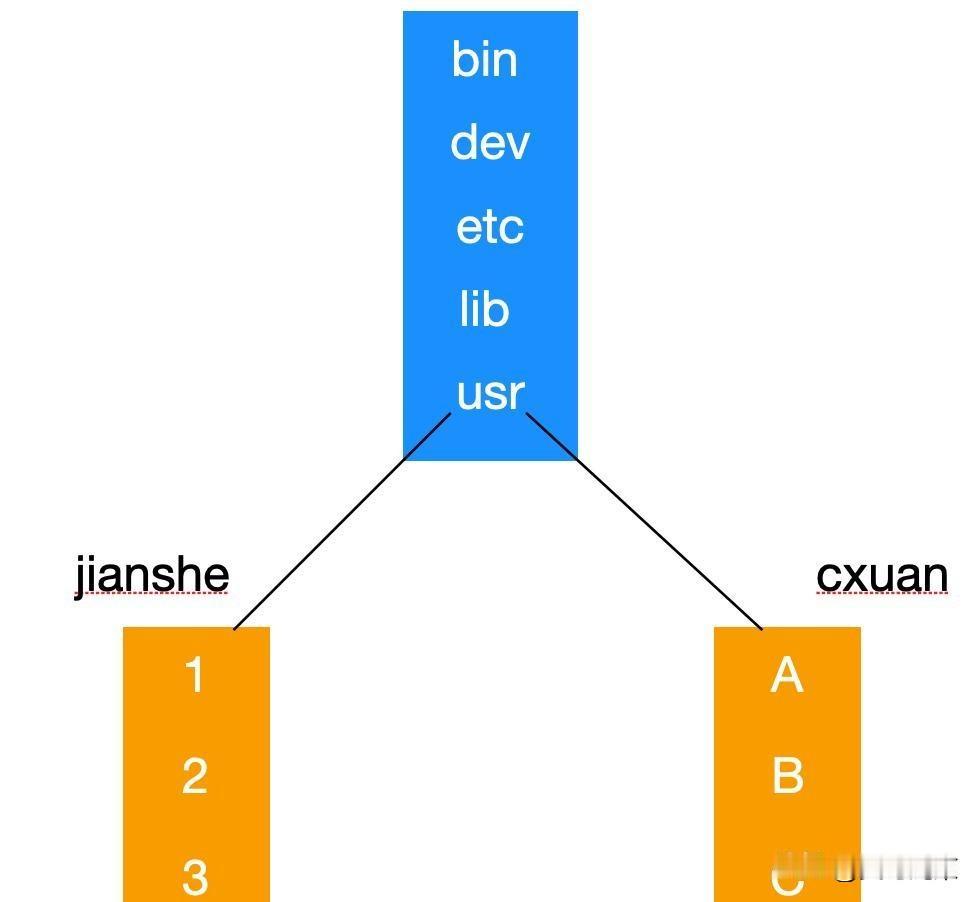
`dentry`听着绕,其实就是路径缓存。
`/usr/bin/ls`被拆成`usr`→`bin`→`ls`三级,每级查一次dentry hash表,O(1)找到下一级inode。
没这层,每次`ls`都得从磁盘上遍历整个`/usr`目录,慢到没法用。
`ls -l`还要读每个文件的inode,所以`stat()`快慢直接决定命令响应速度。
ext4和xfs真不是谁比谁好,是干活的场景不一样。
我用一块旧机械盘装系统,ext4默认格式化,`tune2fs -o journal_data_writeback`后,大日志文件写入快不少。
但要是拿一块8TB NVMe建备份库,`mkfs.xfs -d agcount=32`分32个分配组,并发刷目录就稳得多。
xfs删大目录不卡,ext4删几千个小文件得等半天。
块设备层其实很实在。`/dev/sda`对应`major=8, minor=0`,内核靠这个找`struct block_device`。
I/O请求最后打包成`struct bio`,带上LBA地址、数据页指针、读写标志,扔进`request_queue`。
SSD支持TRIM,`fstrim /`会触发`blkdev_issue_discard()`,告诉固态盘“这串LBA不用了”,不然GC压力大,写几次就变慢。
崩溃恢复这事,机械盘时代靠journal救命。
`write()`调用返回成功,只代表数据进了page cache,journal里元数据也落盘了,但文件内容可能还在内存。
突然断电,ext4靠`e2fsck`重放journal里的事务,把inode、块位图这些拉回一致状态。
xfs不用journal,靠B+树本身的日志结构,`xfs_repair`扫描AG(allocation group)就能重建。
`/proc`和`/sys`根本没硬盘,`ls /proc`看到的全是内核现编的。
读`/proc/1234/status`,内核把task_struct里字段格式化成字符串塞进page cache,再返回给用户。
这不是“假装是文件”,是真把它当文件处理:能`open`、能`lseek`、能`mmap`,连`inotify`都能监听变化。
权限也分两层。
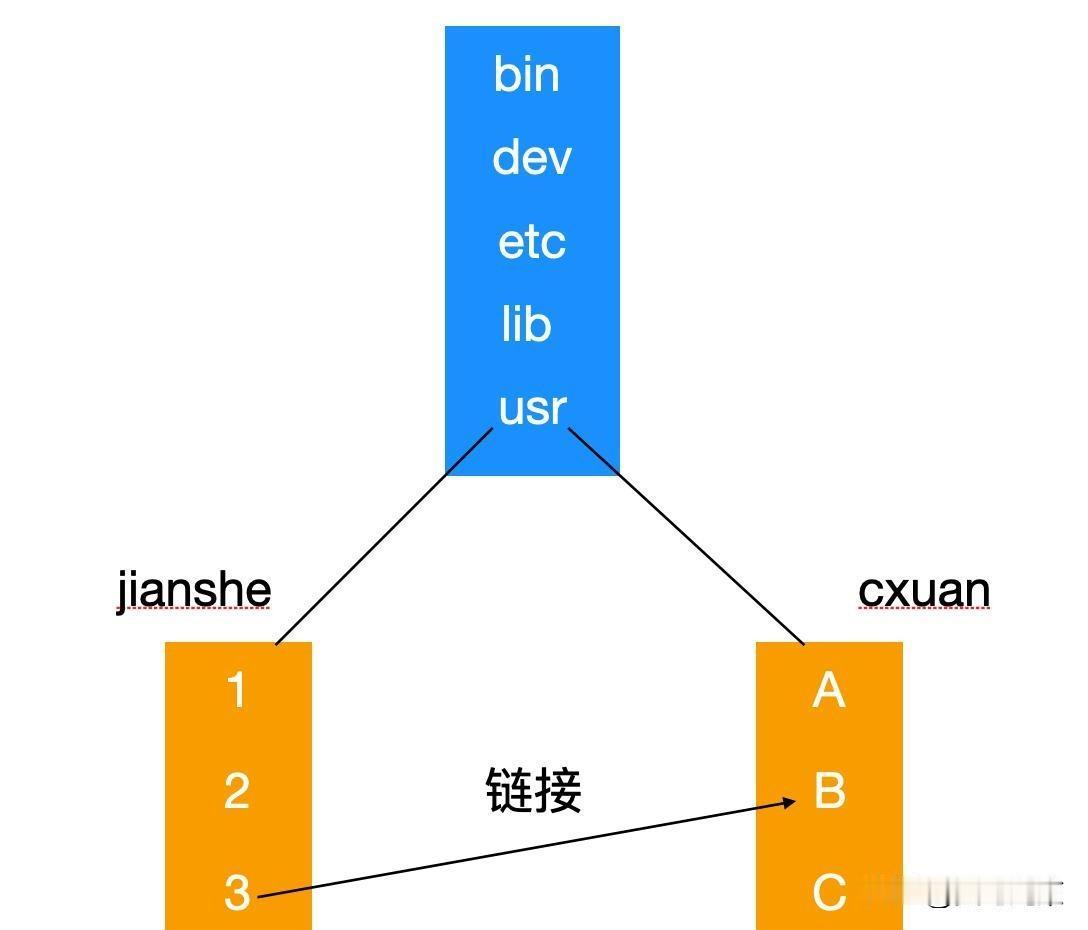
`chmod 600 a.txt`改的是inode里的`i_mode`,所有硬链接共享同一权限。
`ln a.txt b.txt`只是新建一个dentry指向同一个inode,`b.txt`的权限跟`a.txt`完全一样。
所以删文件不是删内容,是`unlink()`减一次inode的`nlink`,等所有dentry都消失、`nlink==0`才真正回收磁盘块。
挂载点才是Linux最狠的设计。
`mount -t proc proc /proc`不是启动一个服务,是把内核内存映射进文件树;
`mount -t tmpfs tmpfs /run`是直接用物理内存当硬盘用;
`mount -t cifs //nas/share /mnt`让Windows共享也变成本地路径。