【大语言模型训练与推理核心优化路径】
快速阅读:本文梳理了大语言模型在训练与推理阶段的核心优化路径。通过对内存管理、计算效率、并行策略及推理加速的系统性回顾,揭示了如何在有限的硬件资源下实现模型规模的极限扩张。
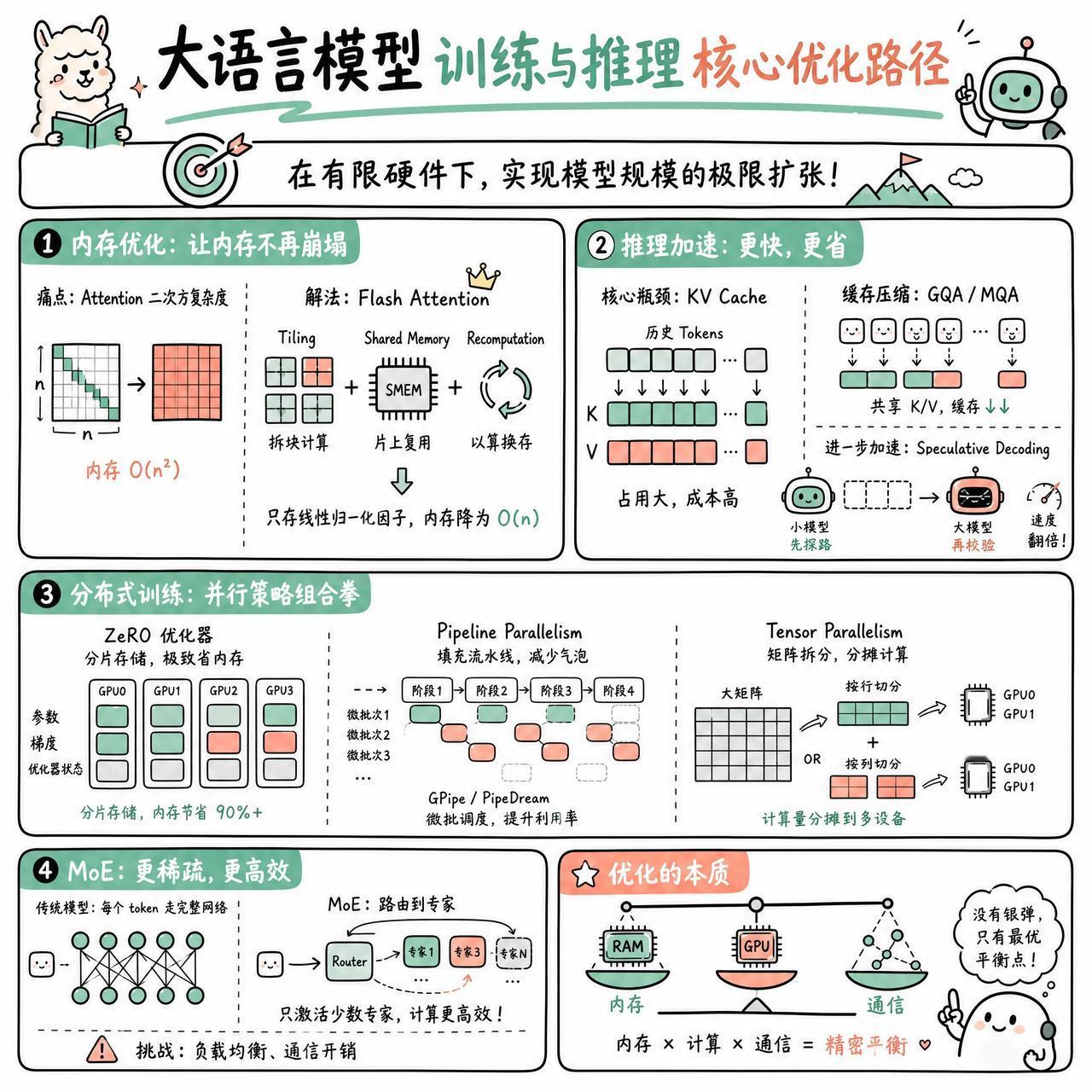
训练和部署大模型,本质上是在跟硬件的物理极限做交易。当参数量迈向千亿级,传统的管理方式会迅速崩溃。
内存是第一个崩塌的层级。Attention 机制的二次方复杂度像一个吞噬资源的黑洞。Flash Attention 的聪明之处在于它不再试图一次性吞下整个矩阵,而是通过 Tiling 技术把任务拆解成小块,利用 Shared Memory 进行局部计算;同时配合 Recomputation,用计算换空间,只存线性长度的归一化因子,把内存压力降了下来。
推理阶段的成本则主要卡在 KV Cache 上。为了不让模型在生成每个新 token 时都去重算一遍历史,我们必须把之前的 Key 和 Value 存起来。有网友提到,通过 GQA 或 MQA 这种共享机制,可以大幅削减缓存的体积。如果想更进一步,Speculative Decoding 这种“小模型先探路,大模型再校验”的策略,能让推理速度实现翻倍。
而在训练的分布式架构里,并行策略的组合拳才是核心。ZeRO 优化器通过对参数、梯度和优化器状态进行分片,把原本冗余的内存消耗降到了极低。Pipeline Parallelism 试图解决 GPU 闲置的“气泡”问题,像 GPipe 或 PipeDream 都在尝试通过微批次调度来填满流水线。至于 Tensor Parallelism,它通过行列拆分矩阵,把巨大的计算量分摊到不同设备上。
如果模型还是太大,MoE(混合专家模型)提供了一种思路:不再让每个 token 都经过整个网络,而是通过 Router 路由到特定的“专家”那里。这虽然带来了负载均衡的挑战,但确实让计算效率有了质的飞跃。
优化从来不是单一维度的胜利,而是内存、计算与通信之间的一场精密平衡。
x.com/gauri__gupta/status/2051882947758993815