出品|虎嗅黄青春频道
作者|商业消费主笔黄青春
题图|视觉中国
一场舆论风暴正在吞噬豆包。
乍一看,豆包完成了撑杆跳,年费一跃从免费跨入千元区间,瞬间引爆全网舆论:“豆包笨还收费”、“免费版要变阉割版”等吐槽迅速登顶热搜。
随后,豆包官方回应称,豆包始终提供免费服务,也在探索推出更多增值服务,以满足不同用户的差异化需求。相关方案细节目前还在测试阶段,正式上线时会通过官方渠道发布完整信息。
据虎嗅了解,付费功能将聚焦在复杂任务和高算力生产力场景,如PPT生成、数据分析、影视制作等,此类任务需消耗更多算力与推理时间,因此豆包计划上线付费服务,以更好满足这部分复杂场景需求。
行业人士猜测,ChatGPT、Claude均采用基础免费+进阶付费模式,豆包核心逻辑也是用户分层+按需付费,背后考量不单单是满足差异化需求,更多是为分摊高算力任务带来的巨额成本压力。
豆包步子迈大了?
豆包此次公布的三档定价,是争议的焦点。
首先,横向对比竞品,豆包定价并不激进。海外头部AI产品中,ChatGPTPlus月费20美元、Pro版100-200美元;ClaudePro月费19美元、Max版100-200美元;GeminiPlus月费7.99美元、Ultra版249.99美元;国内竞品中,Kimi初级会员连续包月49元,智谱、MiniMax基础会员定价集中在30-60元区间,豆包初级会员仍以免费策略走全民普及路线。
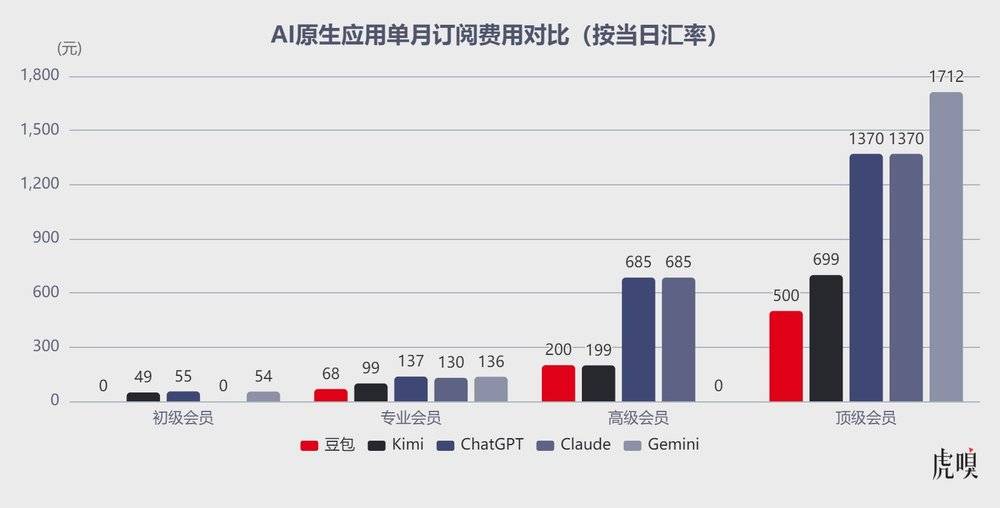
其次,豆包在专业会员到顶级会员的价格区间,玩起了“心智锚定”的定价策略:用68元专业会员对标海外头部AI产品,形成同档比价效应;用500元顶级会员的价格锚点,凸显中档200元的极致性价比。
然而,网上吐槽最多的却是定价与产品能力存在错配:若豆包付费能力仅覆盖PPT生成、数据分析、影视制作等基础生产力场景,核心权益不过是增加调用次数、提升响应速度就会显得缺乏诚意,因为这些功能通义千问免费版已全面开放。
即便对比同价位的Kimi高级会员,后者支持Office全格式深度处理、同花顺/天眼查实时数据接入,还开放了多Agent集群并行能力,可同时完成10个复杂任务,而豆包200元/月的加强版核心生产力能力落后一个代际。
唯一能拎出来当卖点的,是字节旗下Seed2.0文生视频模型。可问题在于,Seedance的高算力成本与豆包订阅价格之间存在难以调和的矛盾:生成100秒Seedance视频的成本约百元,若200元/月的加强版用户每月仅生成2分钟视频,单视频成本就已达120元,再叠加日常文本推理消耗,平台必然陷入“卖得越多亏得越多”的死局。
这意味着,即便用户付费,也很难获得无限制的视频生成额度,最终仍需按次购买点数,所谓会员权益会沦为有限额度的使用权。
更尴尬的是用户结构错配。
QuestMobile数据显示,2026年一季度AI应用新增用户呈现下沉+银发双向延伸趋势,豆包3.45亿月活中,学生、中老年群体占大头,使用场景集中在日常聊天、查资料,根本不需要付费的生产力功能;而真正有高频生产力需求的职场人、开发者、创作者,又普遍认为豆包的专业能力不足,更愿意选择ChatGPT、Claude或国内垂直模型。
这种“低端用户用不上,高端用户看不上”的局面,很容易让豆包付费版陷入两头不讨好的境地。
此外,花旗一项调研数据显示,45%受访者虽愿意为AI高级功能付费,但可接受的月均价格仅为48.3元,比豆包68元的起步价低30%。等于说,豆包订阅价格虚高于国内用户付费心理预期,但也没跳出文心一言、Kimi、讯飞星火等国内AI付费产品的主流基准线。
当然,抛开舆论争议,豆包选择此时收费,确实也有苦衷:海量用户规模带来的指数级算力成本,已经压得字节喘不过气。
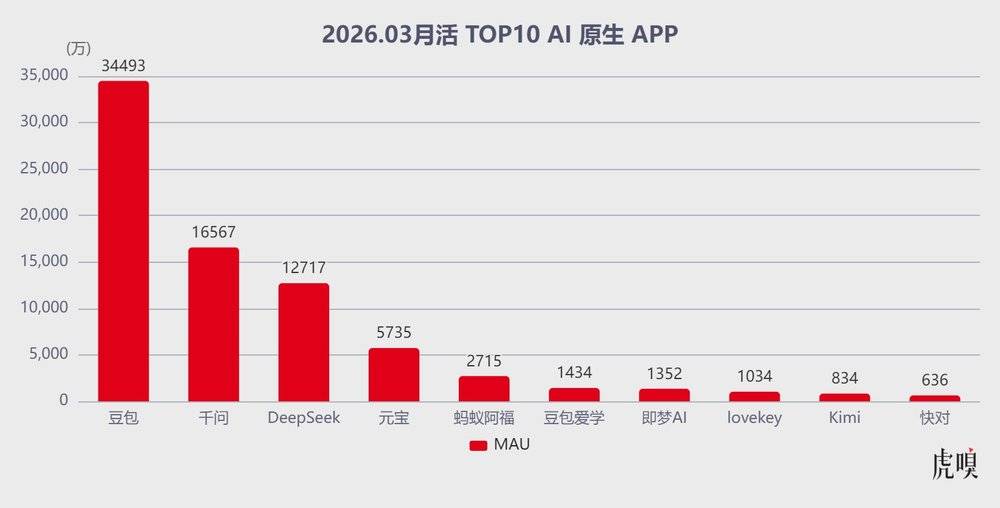
作为国内C端用户基数最大的AI原生应用,豆包的发育速度可谓一骑绝尘。
QuestMobile数据显示,截至2026年3月,豆包月活跃用户已达3.45亿,超过第二名千问(1.66亿)与第三名DeepSeek(1.27亿)的月活总和,日活峰值更是突破1.5亿;一季度月人均使用次数达54.8次,用户活跃率33.5%,两项指标均大幅领先行业竞品。
可支撑数据陡峭上扬的,是海量的算力消耗。据火山引擎披露,目前,在火山引擎上累计Token使用量超过一万亿的企业,已从去年底的100家增长到140家;截至2026年3月,豆包大模型日均Token使用量已突破120万亿,过去三个月增长一倍,较2024年5月发布时暴涨1000倍——相当于每秒钟,豆包就要处理超过138亿个词元的请求。
要知道,大模型的成本逻辑与传统互联网产品有着本质区别:微信、抖音这类产品用户越多,分摊的服务器成本越低,高基数下的单个用户边际成本可以趋近于零;但AI大模型的每一次交互都需要GPU集群实时算力支撑——用户使用越频繁、需求越复杂,总成本就越高,不存在规模效应带来的成本摊薄。
一份在CSDN上流传的成本拆解显示,豆包免费服务单次推理成本结构中,硬件折旧占58%,电力占29%。至于Token成本,虎嗅保守估算,每百万Token的普通对话综合成本在4元,快速/高并发综合成本在0.8~1.4元,以此推算,豆包日均120万亿Token的消耗,仅文本推理成本单日就高达数千万元,一年就是百亿量级;若再计入PPT生成、视频制作等高算力场景,这类复杂任务的算力消耗是日常对话的数百倍,整体成本也将飙升数倍。
基于此,字节在AI算力上的投入堪称疯狂。据多家券商测算,2025年字节跳动资本开支约1500亿元,其中大部分集中在AI板块;2026年,字节计划再投入850亿元用于AI芯片采购。
硬币的另一面,持续高投入直接拖累了公司利润。据知情人士透露,2025年字节跳动净利润同比下滑超过70%,内部已出现“豆包商业化路径不明,大DAU推理成本严重挤压利润”的声音。
回顾过去两年,豆包之所以能坚持全免费模式,是因为字节将其视为抢占AI入口的战略投资。2024年5月,豆包发布API定价时,直接比同行低99.3%,以“价格屠夫”的姿态掀起了国内大模型价格战。彼时,用户规模和数据比短期利润更重要,免费策略帮助字节快速完成了AI入口的战略卡位。
如今,市场跑马圈地基本完成,用户习惯已然养成。CNNIC数据显示,截至2025年12月,中国生成式AI用户规模已达6.02亿,普及率42.8%,AI已经从尝鲜工具变成日常生活助手,字节自然不愿再默默兜下全部成本,试图通过付费订阅,稀释部分深度用户的成本负担。
Token经济大跃进
很多人将豆包收费解读为“AI行业告别免费内卷的信号”,但事实上,国内大模型行业的竞争格局并未因此改变,反而呈现出更加明显的分化态势。
一方面,智谱、腾讯云等厂商正在跟进涨价。智谱年内已进行三次API价格上调,整体涨幅超过60%;腾讯云宣布自2026年5月9日起,AI算力、容器服务、EMR相关产品价格上调5%。这些厂商的用户主要是开发者与企业用户,对价格不敏感,更看重产品能力和服务质量。
另一方面,与豆包、智谱的涨价形成鲜明对比的是,DeepSeek在V4模型上线后反而大幅降价:API限时2.5折,输入缓存命中价格降至原价的1/10,最低仅0.02元/百万Tokens;阿里千问在去年11月公开表示,普通人可以随时用、免费用,目前不考虑收费,其还通过“请喝奶茶”、发补贴等手段疯狂获客。
这种截然相反的策略,源于AI厂商之间资源势能与市场定位的差异:智谱、MiniMax用户基数小,主要服务专业用户,ARPU值高,涨价对用户流失的影响较小;DeepSeek、千问仍处于用户增长阶段,需要通过免费策略抢占市场份额;而豆包稳居国内C端AI应用榜首,用户规模接近触顶,必然开始重视商业化变现。
问题在于,字节过往的商业化主要依赖广告、电商,擅长的是“免费+广告”的流量变现模式,而订阅模式需要长期的用户运营与服务能力,这恰恰是字节的短板。
再加上国内C端订阅市场环境本就“恶劣”——暂且不说多人共享优爱腾会员已是大家心照不宣的策略,年轻人白嫖的消费观念更在一轮轮互联网补贴大战中越发坚定。
百度文心一言就是最好的前车之鉴:2023年推出59.9元/月的订阅会员,仅坚持一年多就在2025年4月1日免费。滑铁卢的原因很简单:国内用户对AI产品付费意愿普遍偏低,甚至形成了“AI就该免费”的固有认知,这种情况下付费用户太少,还会严重影响用户增长。
眼下,豆包的用户规模远大于文心一言,但面临的困境如出一辙:若付费转化率达不到预期,收费反而会成为拖累。
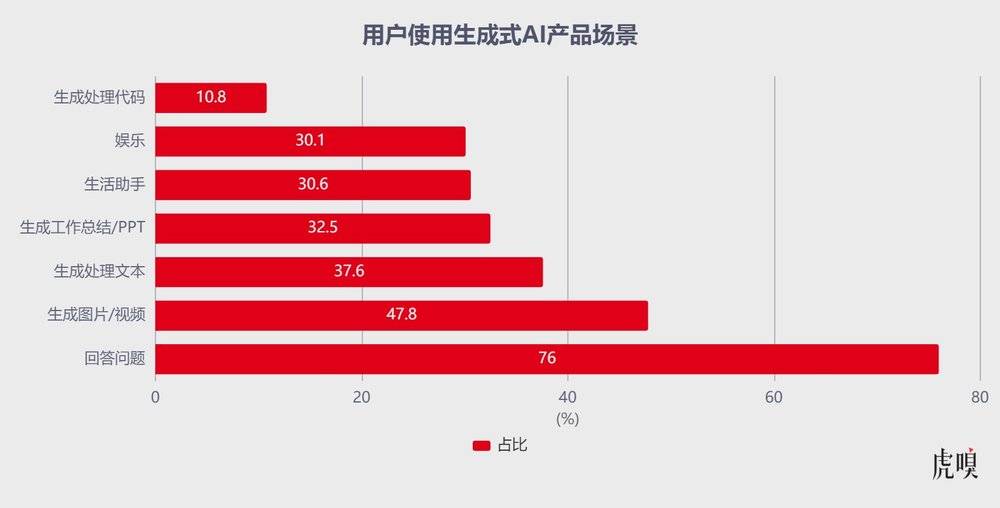
此外,AI付费产品核心卖点是生产力,ChatGPT、Claude的会员之所以抢手,很大程度上得益于AI编程能力;反观豆包,生活场景是基本盘,Trae、扣子(Coze)等编程工具又未深度整合,导致其无法真正胜任专业办公场景,连DeepSeek免费版在代码编写、深度推理等核心场景的表现都全面超越豆包当前版本。
与此同时,在字节系庞大的用户规模及影响力加持下,豆包收费一度被解读为“国内Token经济跃进”的标志性事件。
火山引擎总裁谭待曾表示:“Token的价格差异,本质是其承载的能力差异。下一代模型能力更强,单Token成本会有所上升,能创造的经济价值也会同步提升”;黄仁勋更是直言:“Token是新的商品,更多的容量就能生成更多的Token,收入就会增加。”
但剥开层层包装,所谓的Token经济更像AI厂商发明的成本转嫁话术——它把AI变成了按流量计费的“算力水电煤”,只算自己烧了多少GPU和电费,却绝口不提用户为模型迭代贡献的核心价值。
首先,Token经济混淆了成本与价值的边界。传统软件按功能收费,用户购买的是确定性服务;而Token经济按算力消耗收费,内容越长、步骤越多、模型越复杂,收费就越高。尴尬之处在于,原本AI服务的价值,应该体现在为用户解决问题、创造收益的能力上,现在却直接将算力消耗等同于价值。
其次,Token经济存在严重的信息不对称。对于普通用户而言,没有人能准确说出生成一份PPT需要消耗多少Token、1元钱能稳定买多少Token。平台掌握着Token的定价权、计量权和解释权,可以随时调整价格、调高功能的Token消耗,也可以在不通知用户的情况下限制会员额度,这无疑会让用户处于弱势地位,既看不到花费明细,也无法监督平台是否存在虚标Token消耗的行为。
更重要的是,Token经济完全忽略了用户数据的价值。大模型的迭代依赖海量真实交互数据,用户既是消费者,更是免费的数据劳工。
据行业测算,一次优质的对话数据,其价值远高于一次推理的算力成本。但在Token经济体系下,用户不仅没有获得数据贡献的回报,反而要为模型的进步付费。这种用户提供数据、平台提供算力、用户最终买单的模式,本质上是平台对用户的双重剥削。
还有一个被刻意回避的叩问:Token经济如何真正实现盈利?
从海外经验来看,答案并不乐观。OpenAI2024年运营亏损超过50亿美元,即便拥有数千万付费用户,订阅收入仍无法覆盖研发和算力成本。原因很简单:愿意付费的用户,往往也是算力消耗最高的重度用户,他们的使用成本很容易超过订阅费用。

豆包亦无法跳出这个死循环:如果付费用户都是每天生成视频、做数据分析的算力大户,订阅收入不仅无法覆盖成本,反而会让亏损进一步扩大;如果平台限制付费用户的使用额度,又会引发用户不满,导致续费率下降。
更深的隐忧在于,付费体系上线会让免费版变阉割版。即便豆包官方反复强调基础功能永久免费,试图以此打消普通用户的顾虑,但过往互联网产品的发展历史告诉我们:当付费体系建立后,免费版的权益不可避免会被逐步降配,这是互联网行业的普遍商业逻辑,无关道德评判。
此前已有从业者透露,豆包已在免费版的模型版本、上下文长度、推理深度、响应速度上做了严格限制:高峰期免费用户长文档解析会出现截断,复杂逻辑推理的准确率低于内部测试版本。
可以预见,豆包付费体系上线后,有限的GPU算力必然会优先分配给付费用户,免费用户遭遇高峰期排队、响应速度慢、模型变笨等现象会更加突出,甚至不排除一些原本免费的功能会逐步移入付费专区。
比如,现在免费的基础图片生成,未来可能会限制每日次数;现在免费的长文档总结,未来可能会限制文档长度。毕竟,这种“温水煮青蛙”式的权益缩水,在视频网站、网盘等行业早已屡见不鲜,AI行业也不会例外。
更值得警惕的是,用户分层正在一定程度上造成生产资料的分层。
当AI从信息工具升级为核心生产力助手,算力正在成为新时代的“石油”:付费用户可以获得AI赋能的效率杠杆,免费用户则被挡在高阶AI的门槛之外——两者差距不止于信息获取,更在于思考能力与生产效率。