就是那种,你知道它在做,但总觉得差点意思。每次看到文心又发新版本,反应都是"哦,又一个更新"。
但今天有点不一样!
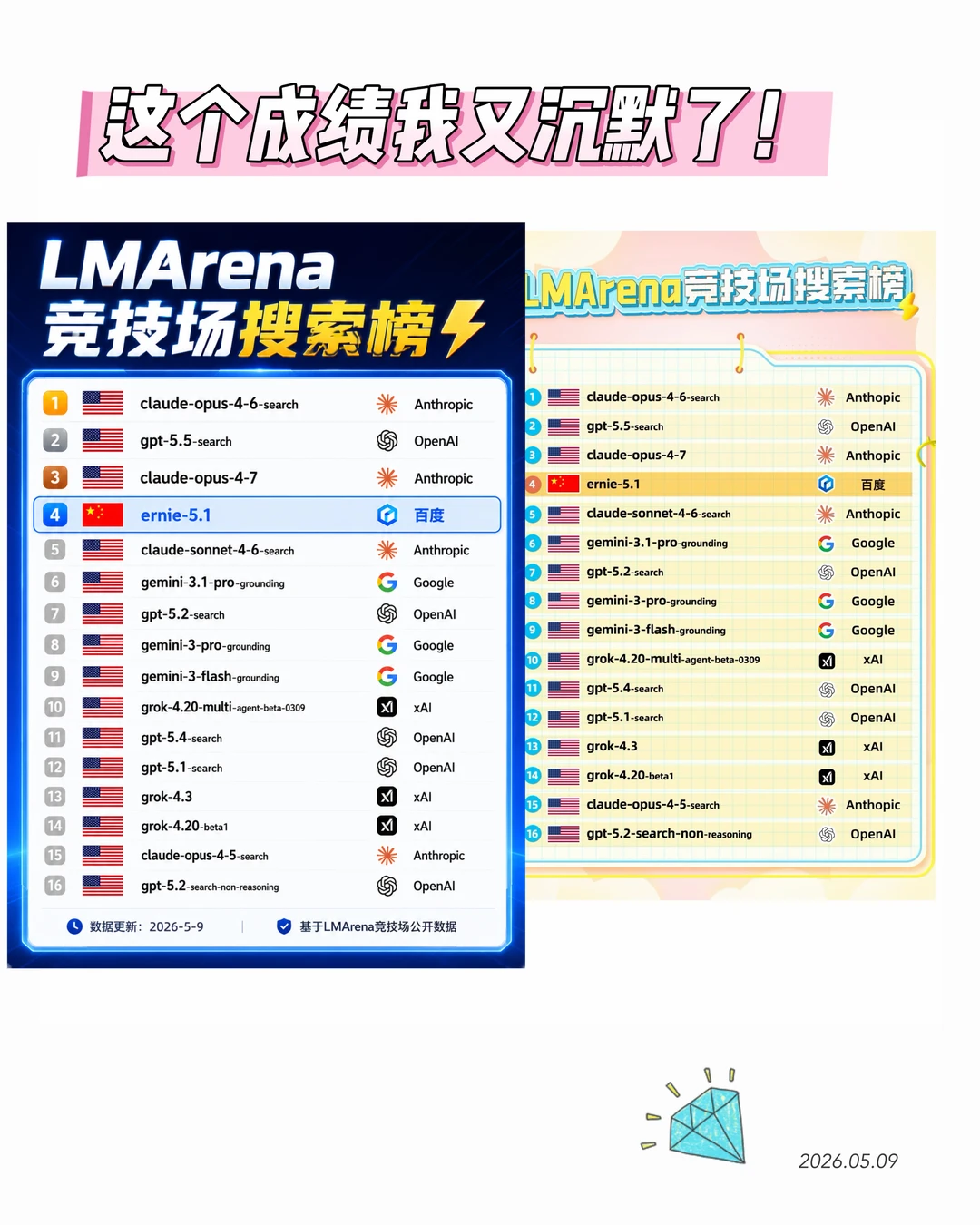
文心5.1发布,我认真看了一下数据,然后有点沉默了……
同规模模型,预训练成本只有业界的6%。
6%是什么概念?别人花100块训出来的东西,百度6块搞定了,效果还领先。这已经不是省钱性价比的事儿了,是在换算力经济的底层逻辑。
好奇是怎么做到的?我研究了下,有一种叫"多维弹性预训练"的技术,大概意思就是一次训练产出多种规模模型,不是传统路线从头训,而是调整深度、专家容量、路由稀疏度直接造新模型。参数压到1/3,激活参数压到1/2,能力还没掉,这就有点意思了。
我突然意识到一件事,AI行业这两年的叙事,基本被流量最大的声音占据。谁最会讲故事,谁就最被关注。但有些选手是在默默把基础设施的成本打下来的,这种事短期不惊艳,长期可能才是真正改变行业格局的东西。
就像做内容,短期正确的和长期正确的,往往是两件事,两个方向。
5月13号百度Create 2026大会,我看这前菜已经够惊艳了,好奇正菜端上来,那得是什么水平,跟学长一起蹲蹲吧!