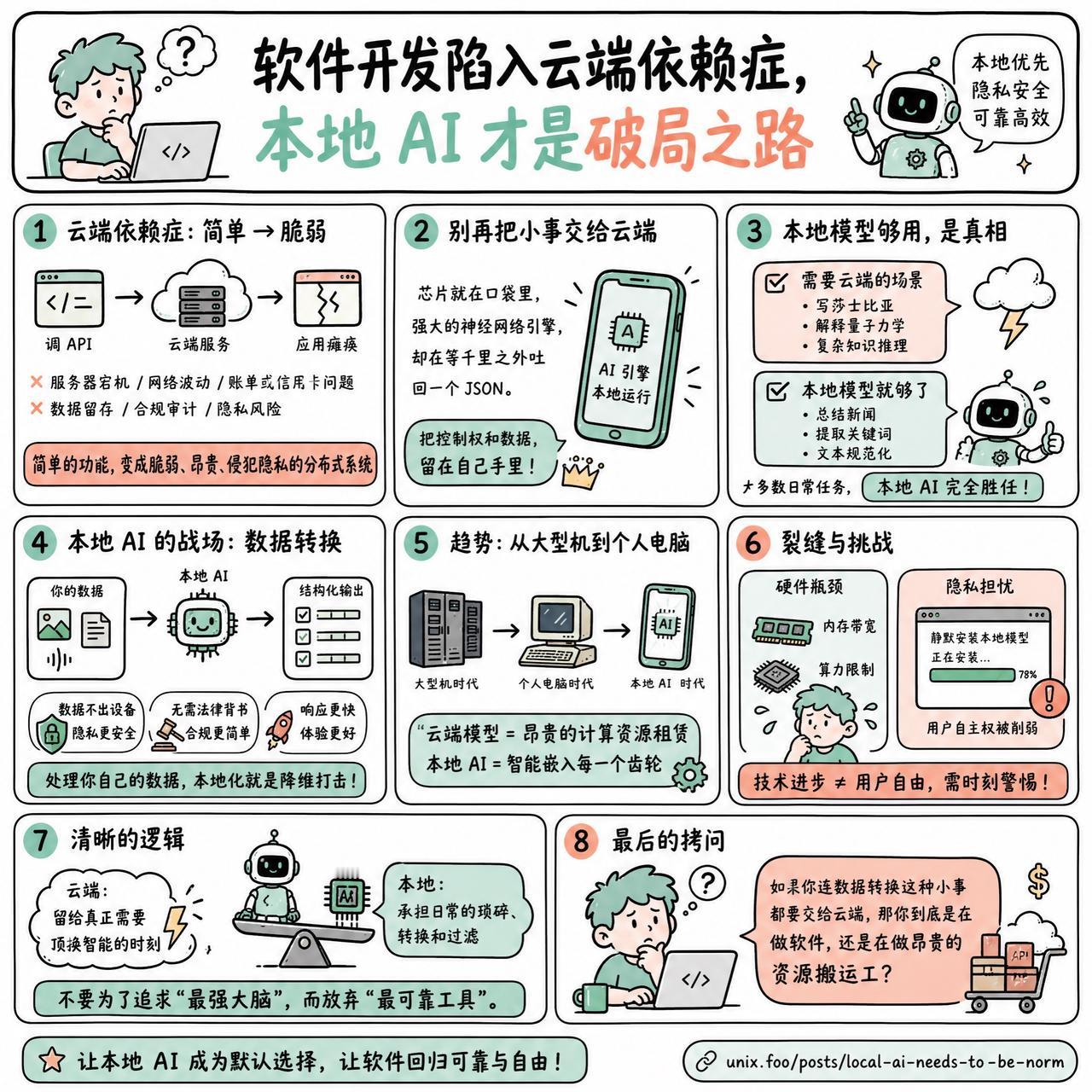
【软件开发陷入云端依赖症,本地 AI 才是破局之路】
快速阅读:目前的软件开发正陷入一种“云端依赖症”,开发者习惯于通过调用 API 简单粗暴地实现 AI 功能。这种做法将简单的交互变成了脆弱、昂贵且侵犯隐私的分布式系统。真正的进步在于将 AI 视为一种本地化的数据转换工具,而非仅仅是昂贵的云端大脑。
现在的开发者似乎有一种偷懒的惯性:想加个功能?直接调个 OpenAI 的 API 就行。
这看起来很高效,但实际上是在亲手把一个简单的功能,变成一个脆弱的分布式系统。一旦服务器宕机、信用卡过期或网络波动,你的应用就瘫痪了。更别提你还得为了这一个功能,去处理数据留存、合规审计和各种隐私协议。
这种做法太笨了。
你手里的芯片明明就在口袋里,拥有强大的神经网络引擎,却在等着千里之外某个数据中心吐回一个 JSON。
有意思的是,很多人在争论“本地模型不够聪明”。
这其实是个伪命题。如果你的目标是让 AI 写莎士比亚或者解释量子力学,那确实得找云端。但如果只是想总结一段新闻、提取几个关键词、或者把一段非结构化的文本规范化,本地模型完全够用。
本地 AI 的真正战场,不在于“知识检索”,而在于“数据转换”。
当模型的工作是处理用户已经拥有的数据时,本地化就是降维打击。数据不需要离开设备,隐私不需要通过长篇累牍的法律条款来背书,因为数据压根没出门。
有网友提到,这种趋势就像当年的个人电脑取代大型机。现在的云端模型更像是昂贵的计算资源租赁,而本地 AI 则是把智能嵌入到工具的每一个齿轮里。
当然,这中间也有裂缝。
硬件成本和内存带宽依然是硬伤。想要流畅运行像 DeepSeek 这样级别的模型,普通消费级硬件还在挣扎。而且,当厂商开始在浏览器里“静默安装”本地模型时,那种对用户自主权的剥夺感,会让原本美好的愿景变得有些令人不安。
但逻辑很清晰:不要为了追求“最强大脑”而放弃“最可靠工具”。
把云端模型留给那些真正需要顶级智能的时刻,把日常的琐碎、转换和过滤,还给本地的芯片。
如果你连数据转换这种小事都要交给云端,那你到底是在做软件,还是在做昂贵的资源搬运工?
unix.foo/posts/local-ai-needs-to-be-norm