给大家分享个有意思的事儿。
昨天,也就是5月20日,阿里和谷歌在同一天各自发布了自己的新模型。两家公司发的两款模型,同时出现在了全球同一张评测榜单上。
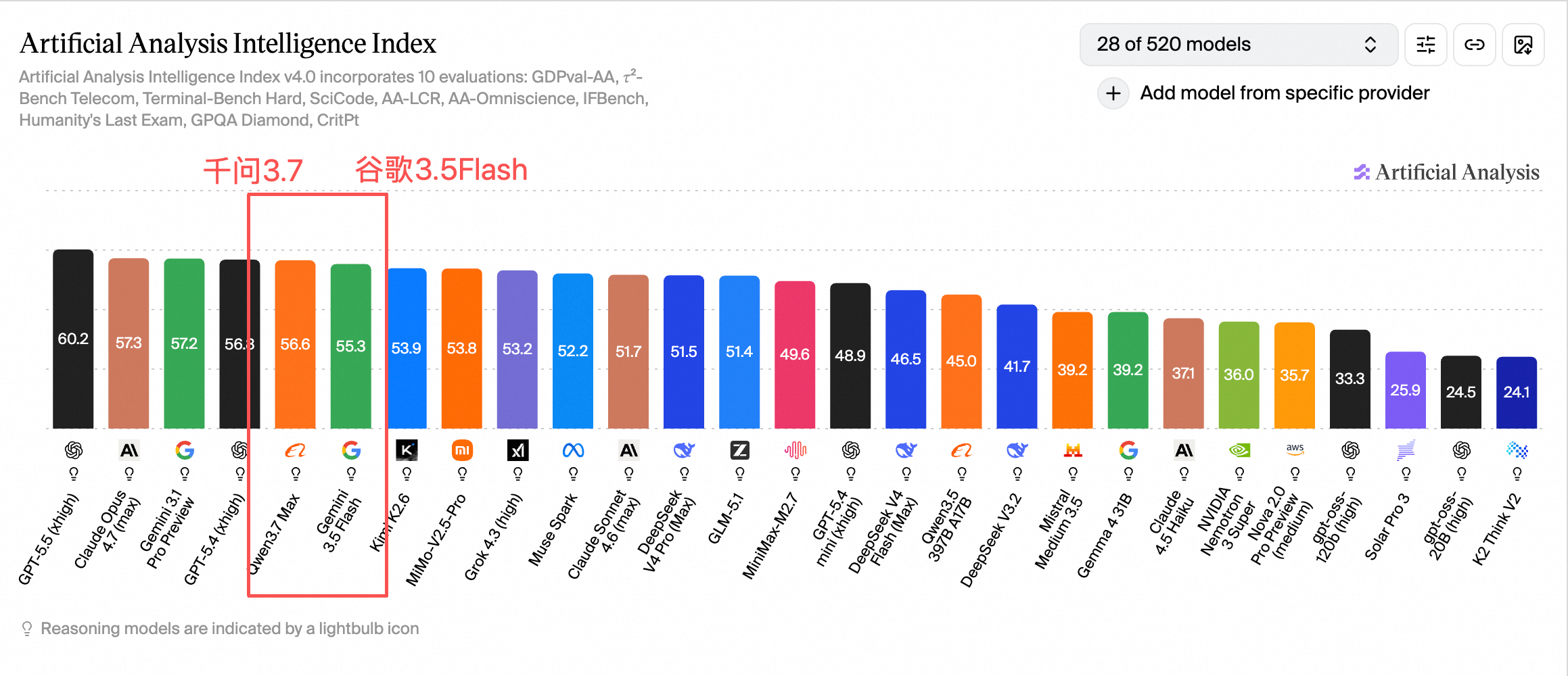
结果出来,阿里千问3.7 Max得了56.6分,谷歌Gemini 3.5 Flash得了55.3分。
差距虽然不算大,但是赢了。
1这次公布榜单成绩的机构叫Artificial Analysis,是一个独立的AI评测平台,专门对全球大模型做多维度的基准测试。
业内普遍认为它是含金量最高的第三方榜单之一。
而在这次评测里,Qwen3.7-Max拿到了全球第五、国产第一的位置。
千问3.7 Max的定位,用一句话来说,就是「为Agent而设计」的。
之前的大模型像一个顾问,你问什么它答什么;但Agent模式下的大模型更像一个执行者,你说要什么结果,它自己去搞定。
千问3.7 Max能完成的任务规模有多大?官方给出的数字是:单次任务可以持续运行35小时,工具调用次数超过1000次,最终交付的是生产级别的成果。
35小时、1000次工具调用,这是一个可以独立完成一个完整项目的量级。
2而且,迭代速度也很惊人。
一个月前,千问3.6 Max Preview刚刚创下了国产模型在Artificial Analysis榜单上的最高分纪录。
然后一个月后,这个纪录被千问自己打破了。且在同一天,谷歌Gemini 3.5 Flash发布,同一榜单得分55.3,低于千问3.7 Max。
而且目前全球前五的模型里,只有千问是国产的。
还有一点,千问3.7 Max即将上线阿里云百炼,开发者可以直接调用,和Claude Code、Hermes Agent、Qwen Code等主流Agent框架协同工作,让它可以嵌入各种开发者的工作流。
这个选择背后有一个清晰的判断:大模型最大的商业空间,是通用生产力,而不是封闭的产品矩阵。
3说到这里,可能有人想问:这些跑分数字,和普通用户有什么关系?
大模型的基础能力越强,你日常用到的那些AI工具,跑在上面时表现就越好。你感受不到底层模型在升级,但你会感受到工具越来越好用,任务完成得越来越干净利落。
更重要的是,Agent能力的提升,意味着未来会有越来越多的工具,可以帮你独立处理那些流程复杂、步骤繁多的事情。
当然,同天发布、同台竞技,阿里和谷歌选择的产品方向其实不太一样。
谷歌Gemini 3.5 Flash更强调快速响应和多模态能力,千问3.7 Max主打Agent场景下的编程、工具调用和长程任务。
这背后,是两家公司对大模型未来用途的不同判断。阿里押注的是:AI的核心价值在于能不能替人完成完整的工作,而不只是让对话更聪明一点。
至于这个判断对不对,可能还需要时间来验证。但至少在5月20日这一天,千问3.7 Max赢了谷歌一局。