不堆参数堆效率,阿里这款小模型编程能力有多强!
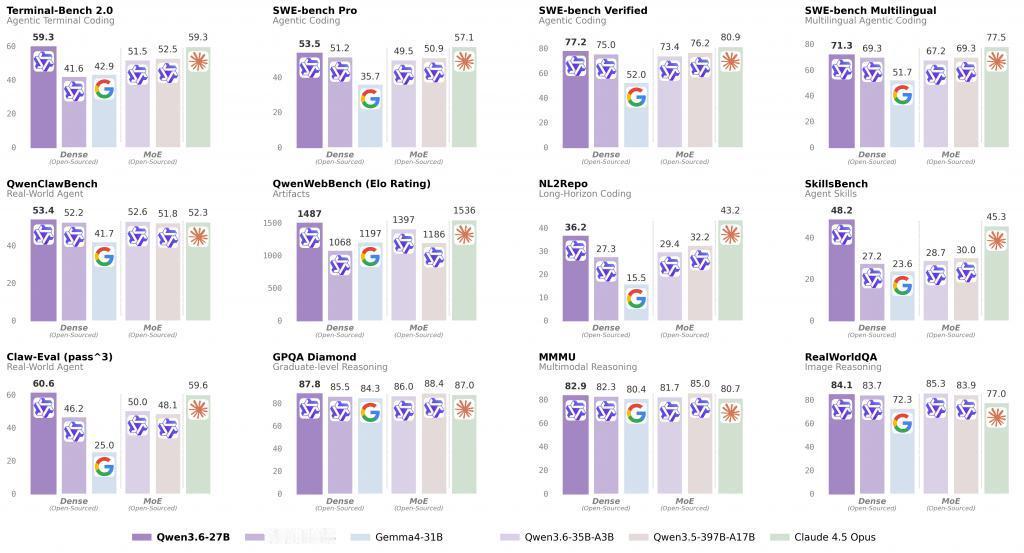
4月22日晚,阿里云通义千问正式开源Qwen3.6-27B,一款270亿参数的稠密多模态模型。别看它体量小,编程能力却相当能打——在SWE-bench Verified测试中拿到77.2分,全面超越总参数量高达3970亿的前代旗舰Qwen3.5-397B。参数规模小了15倍,性能反而更强,这在AI圈算得上罕见。
除了编程,它的多模态能力同样不含糊,原生支持图像、视频、文本混合输入。原生上下文26万token,可扩展至百万级别,足以装下整个大型代码仓库。
更关键的是,它采用稠密架构,不像MoE模型那样需要复杂的专家路由,部署门槛低得多,vLLM等主流框架直接就能跑,甚至一张4090显卡就能跑量化版。
权重已在Hugging Face和ModelScope上线,支持本地部署,同时可通过阿里云百炼API调用,用户也能在Qwen Studio上在线体验。
这次发布最大的看点,不是参数堆得多高,而是“效率”。以前大模型拼参数量,动辄千亿起步,本地跑不动,云端调用贵。Qwen3.6-27B用270亿的参数,做到了千亿级模型的编程能力,靠的不是运气,是架构优化——混合了线性注意力机制,长上下文场景下显存占用远低于纯注意力模型。这让本地部署真正落地,数据不用上传云端,开发者拿张4090就能跑,成本降了,隐私也保住了。同时,“思考保留”机制的加入,在多轮代码调试场景中,不用每轮重新推理,延迟和token消耗都明显降低。
当模型能力不再“越大越好”,开源生态才能真正繁荣起来。阿里这步棋,落得准。