工业级RAG检索增强生成完整技术拆解
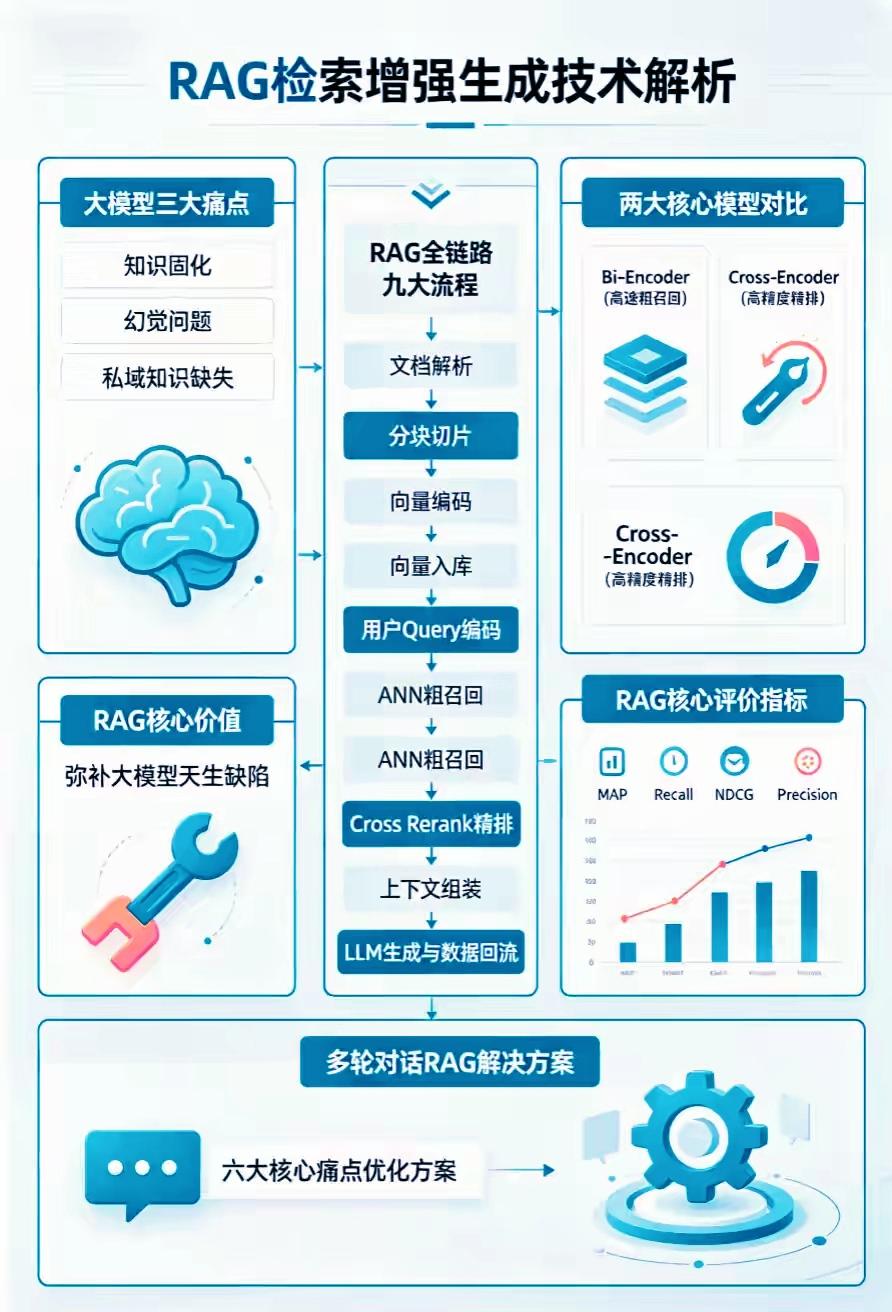
一、大模型原生三大短板(RAG的解决目标)
1. 知识固化:模型训练数据有时间截止点,无法自动获取最新业务、行业信息;
2. 幻觉问题:无依据编造事实、参数、流程,专业场景容易输出错误结论;
3. 私域知识缺失:企业内部合同、台账、工艺文档、内部制度无法内置进通用大模型。
RAG核心价值就是针对性补齐这三类天生缺陷。
二、RAG全链路九大标准流程
1. 文档解析:处理PDF、表格、扫描件、Word等多格式原始文件,提取干净结构化文本;
2. 分块切片:按语义/段落拆分长文本,平衡块大小,避免上下文断裂或信息碎片化;
3. 向量编码:用Embedding模型把文本块转为高密度数值向量;
4. 向量入库:存入Milvus、PGVector等向量数据库,建立索引;
5. 用户Query编码:把用户提问同步转换成同维度向量;
6. ANN粗召回:用Bi-Encoder快速批量筛选相似度靠前的文本块;
7. Cross Rerank精排:Cross-Encoder对粗召回结果做精细打分重排序,过滤低相关内容;
8. 上下文组装:把高分参考片段+用户问题拼接成完整Prompt送入大模型;
9. LLM生成与数据回流:模型输出答案,同时可把优质问答样本回灌知识库迭代优化。
三、两大编码器分工差异
1. Bi-Encoder(高速粗召回)
速度快、算力消耗低,负责十万级、百万级向量库的大范围初筛,优先保证召回率;
2. Cross-Encoder(高精度精排)
精度更高、推理速度慢,只对粗召回后的少量候选内容做深度语义匹配,大幅提升答案准确度。
四、RAG效果四大核心评估指标
- Recall(召回率):真正相关的参考片段被检索出来的比例;
- Precision(精确率):检索返回内容里有效相关片段的占比;
- MAP、NDCG:综合排序质量指标,衡量高相关内容是否排在前列位置。
五、多轮对话RAG优化体系
针对多轮问答上下文遗忘、历史意图偏移、重复检索、对话越长精度暴跌等行业通病,配套六大定向优化方案,适配客服、内部咨询、项目答疑这类持续交互场景。
AI大模型公司 大模型数据困境 ai免费大模型 大模型推荐系统 制造业AI改造 检索增强模型 智能制造大模型