[CL]《Mind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?》T Lv, D Zhang, J Ding, Y Jia… [Microsoft Research] (2026)
在办公自动化领域,当前LLM代理面临的核心难题是:它们能否可靠地完成真实专业级文档操作任务。尽管代码生成能力快速进步,但模型在处理Word、Excel、PowerPoint的复杂格式化、跨应用集成和长链条规划时,仍缺乏系统性评估。过去的基准要么依赖合成任务,要么只覆盖单一应用片段,无法反映实际工作场景中那种需要精确参数配置、多步骤依赖、视觉样式还原的真实压力。
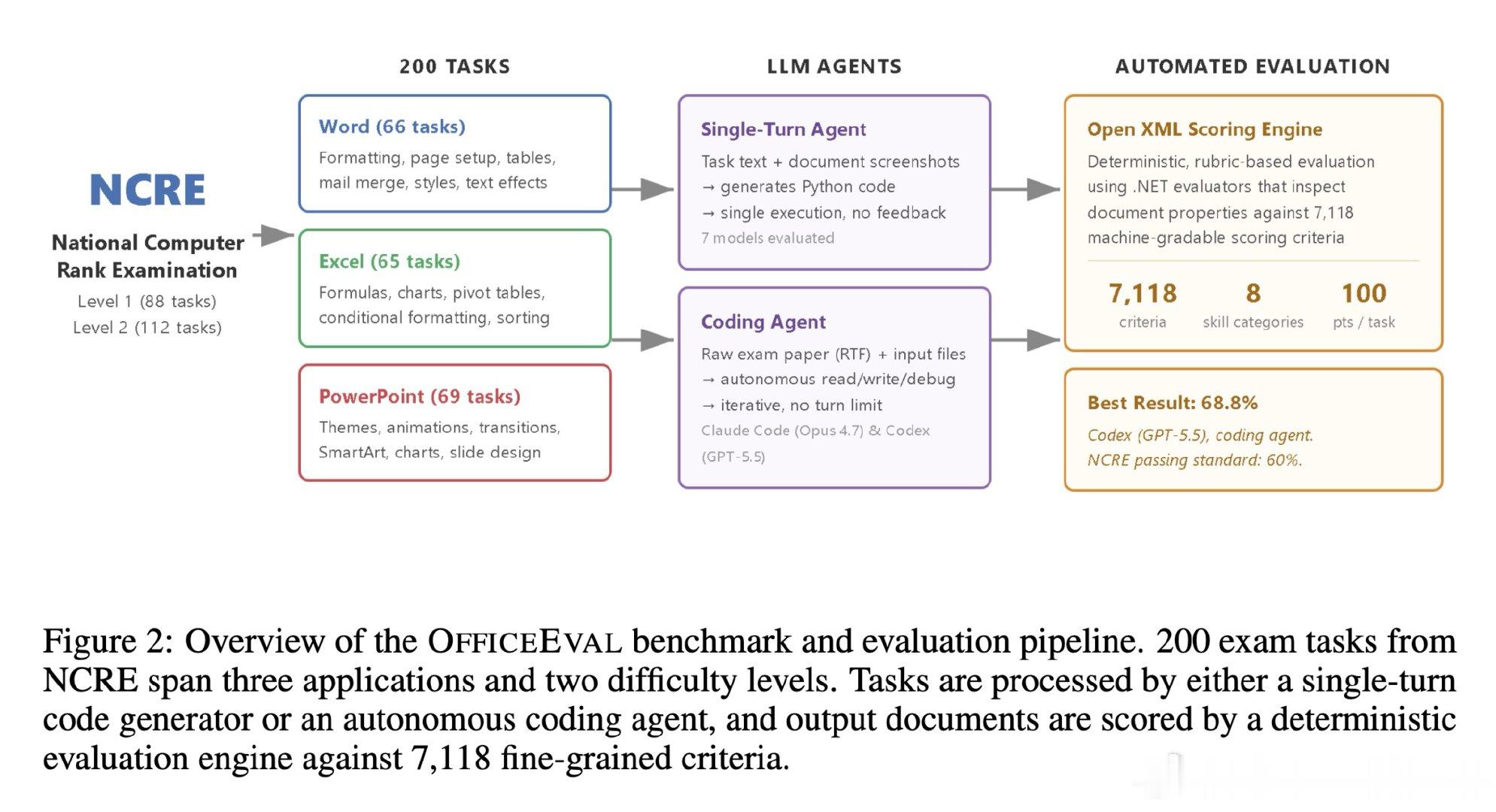
本文的核心洞见是:将人类职业资格考试直接作为AI能力基准。研究者从中国国家计算机等级考试(NCRE)中提取了200道实操题,构建出OFFICEEVAL基准——每道题包含20-70项机器可判的评分标准,总计7118个独立评估信号。由此,模型的得分率(SR)首次锚定在外部权威的百分制标准上,而非仅在系统间比较。实验揭示了一个残酷事实:单轮生成的最强模型(Claude Opus 4.7)得分率仅36.6%,远低于60分及格线;即使引入执行反馈和迭代修复的代理系统,最佳表现(Codex 68.8%)仍未达到社区参考答案的95.5%。
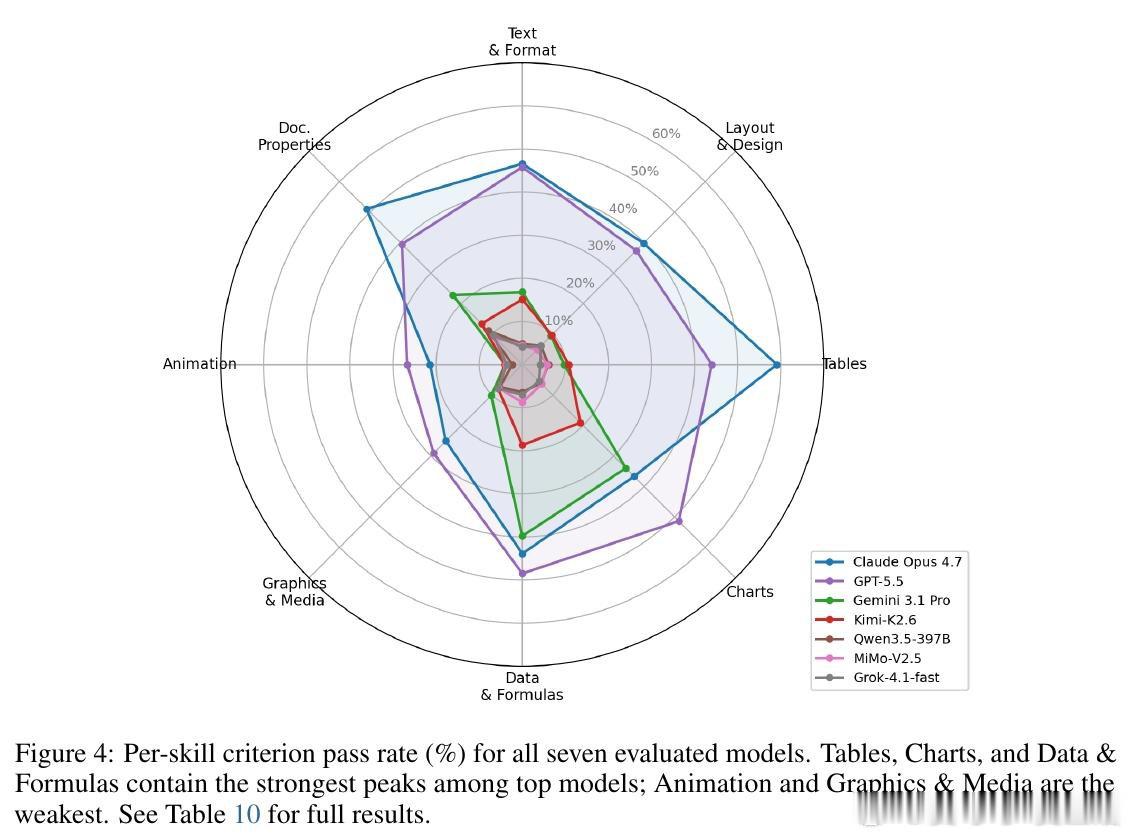
这项工作真正留下的遗产是为办公自动化能力建立了一个可复现、有外部锚点的评估体系,并通过标准化考题暴露了当前LLM在实现知识(API常量、样式名称、颜色编码)上的系统性缺口。它为后来者打开的新门是:将职业资格考试转化为AI基准的方法论,以及通过细粒度标准分类诊断失败模式的技术路径。但尚未跨过的门槛是:即使执行成功率提升至98%,操作准确率仍然受困于那些任务描述中未明确、需从模型内部知识召回的底层Office对象模型细节——这是当前代码生成范式难以逾越的鸿沟,也预示着技能库增强型代理架构可能成为下一个突破方向。
arxiv.org/abs/2606.10956 机器学习 人工智能 论文 AI创造营