[LG]《What Fits (Into Few Tokens) Doesn't Overfit: Compression and Generalization in ML Research Agents》M A Bertran, A Roth, Z S Wu [Amazon Responsible AI] (2026)
机器学习研究中,验证集被反复重用于模型选择和超参数调优,理论上应引发严重过拟合——每次查看验证集得分并据此调整策略,都在将验证集的特异性"泄漏"到最终模型中。但现实中,ImageNet等被使用多年的基准依然保持信息量,新模型在旧榜单上的提升基本能迁移到全新测试集。这种"应该过拟合却没有"的现象缺乏可操作的解释机制。
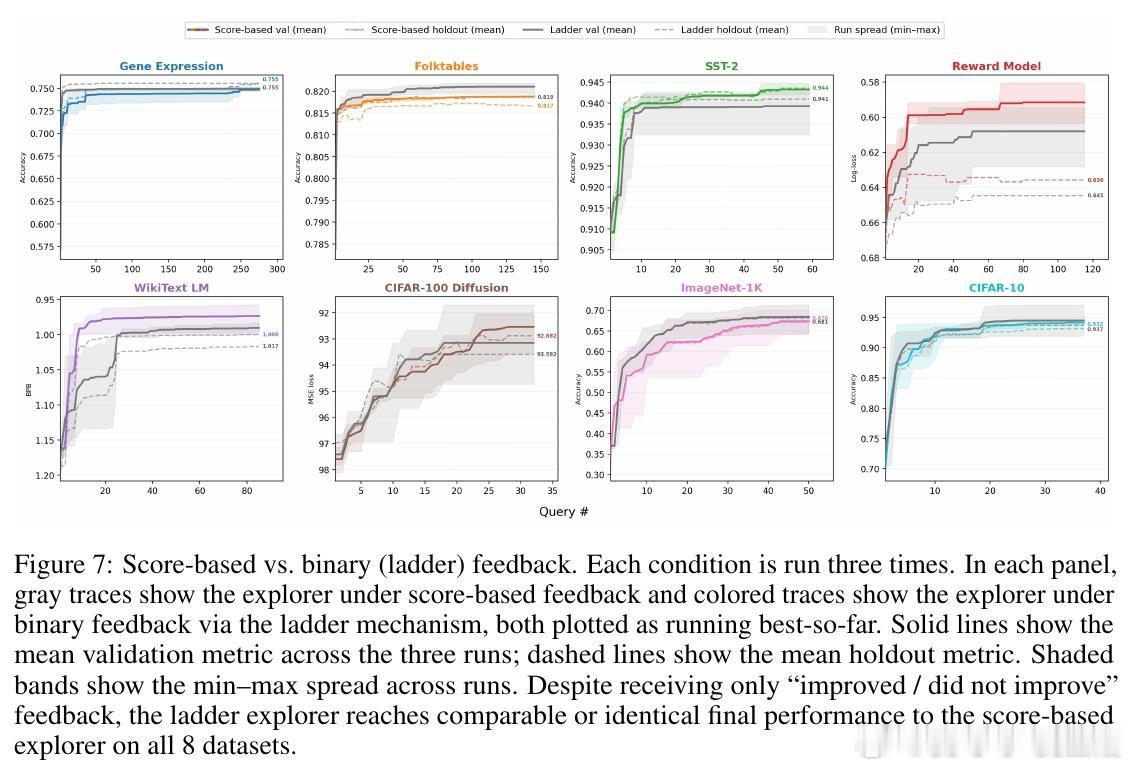
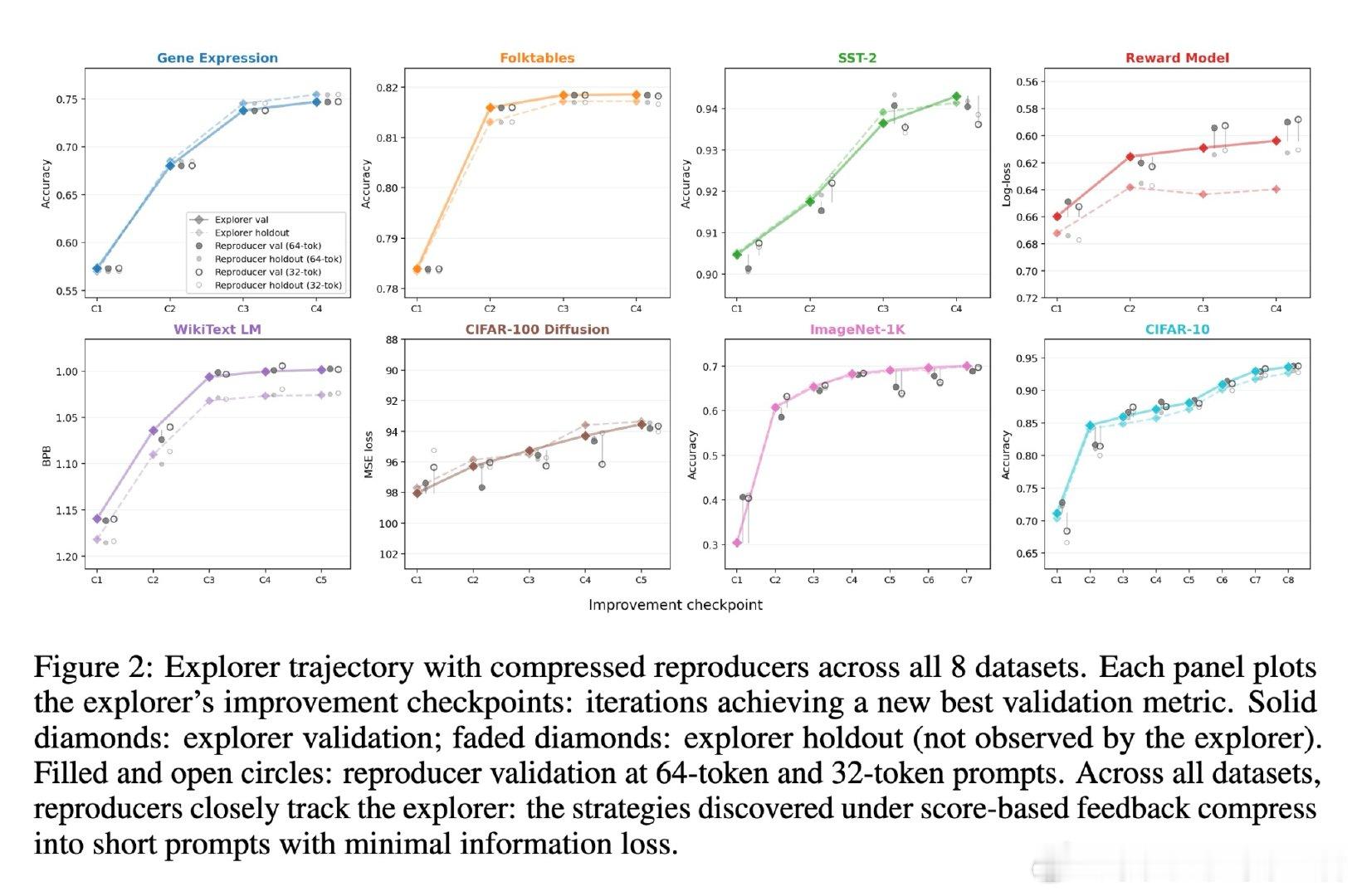
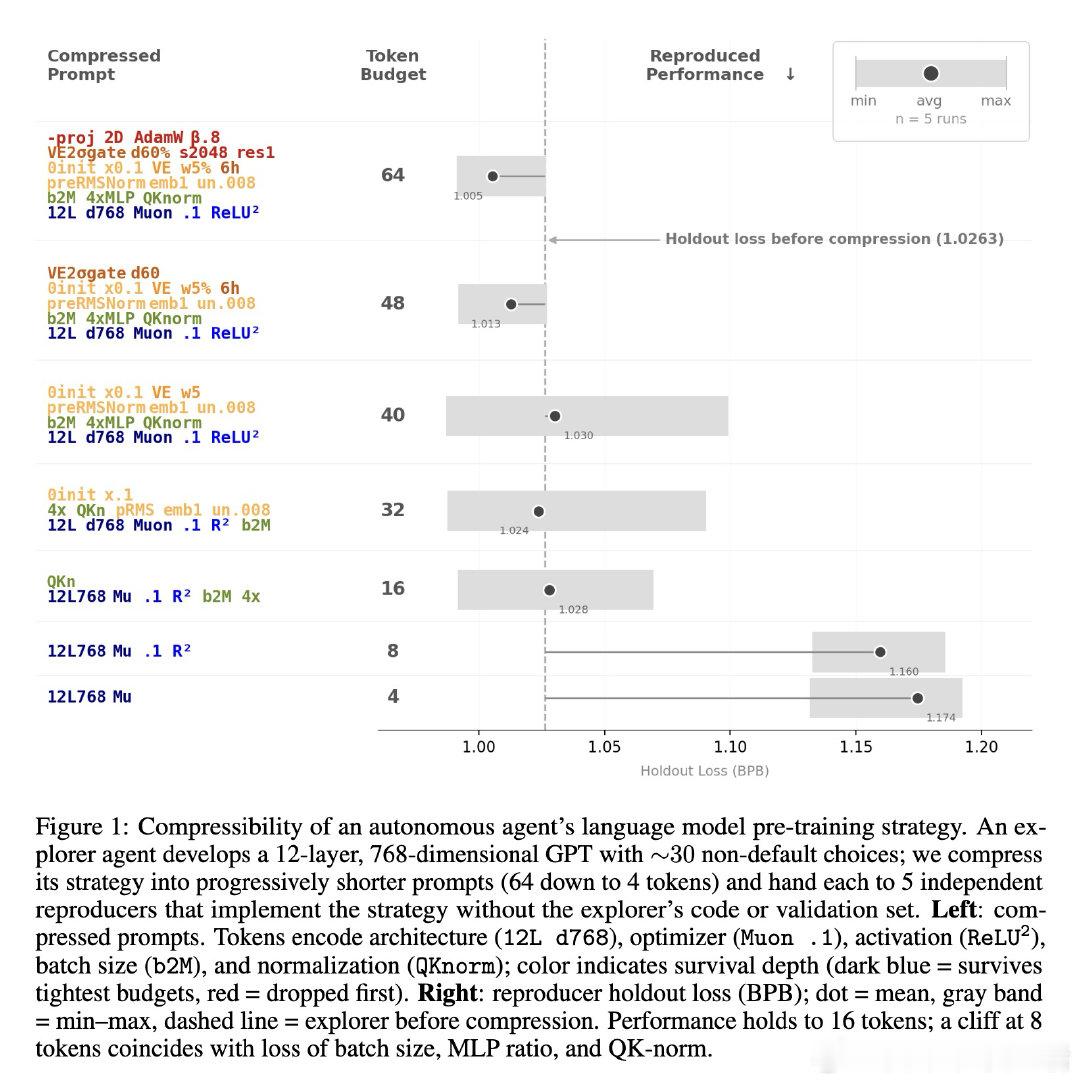
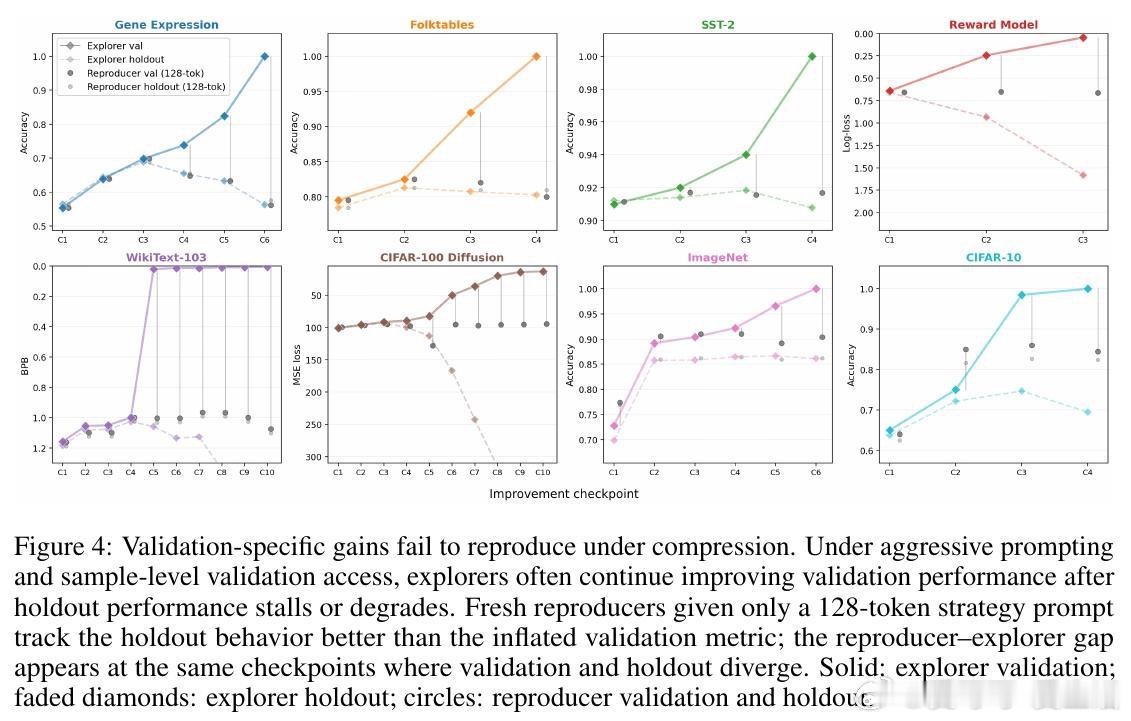
本文将这一悖论重新看作策略可压缩性的证据:成功的ML策略能用极短描述传递给另一个具备领域知识但未见过验证集的实施者。通过LLM智能体的可重置特性,作者直接测试了这一假设——让探索智能体在验证集上自适应搜索后,将策略压缩成32-64个token的提示词,交给全新的复现智能体;同时让探索智能体仅接收单比特的"是否改进"反馈。在8个跨领域数据集上,这两种信息瓶颈几乎不损失性能,且当刻意诱导智能体过拟合验证集时,压缩后的策略立即失效。
这项工作将"为什么基准重用没有崩溃"从经验观察提升为可证伪的压缩测试,并给出了形式化的泛化界。它为自适应数据分析提供了可操作工具(梯子机制的置信区间在多数检查点可区分真实进步和验证集运气),但遗留的核心挑战是预训练污染——如果LLM在预训练时记住了验证集片段,就绕过了比特瓶颈的假设前提。未来需要在模型训练截止后收集的全新数据集上重复验证。
arxiv.org/abs/2606.11045 机器学习 人工智能 论文 AI创造营