[CL]《Which Models Are Our Models Built On? Auditing Invisible Dependencies in Modern LLMs》S Adhikesaven, H Sun, S Min [UC Berkeley] (2026)
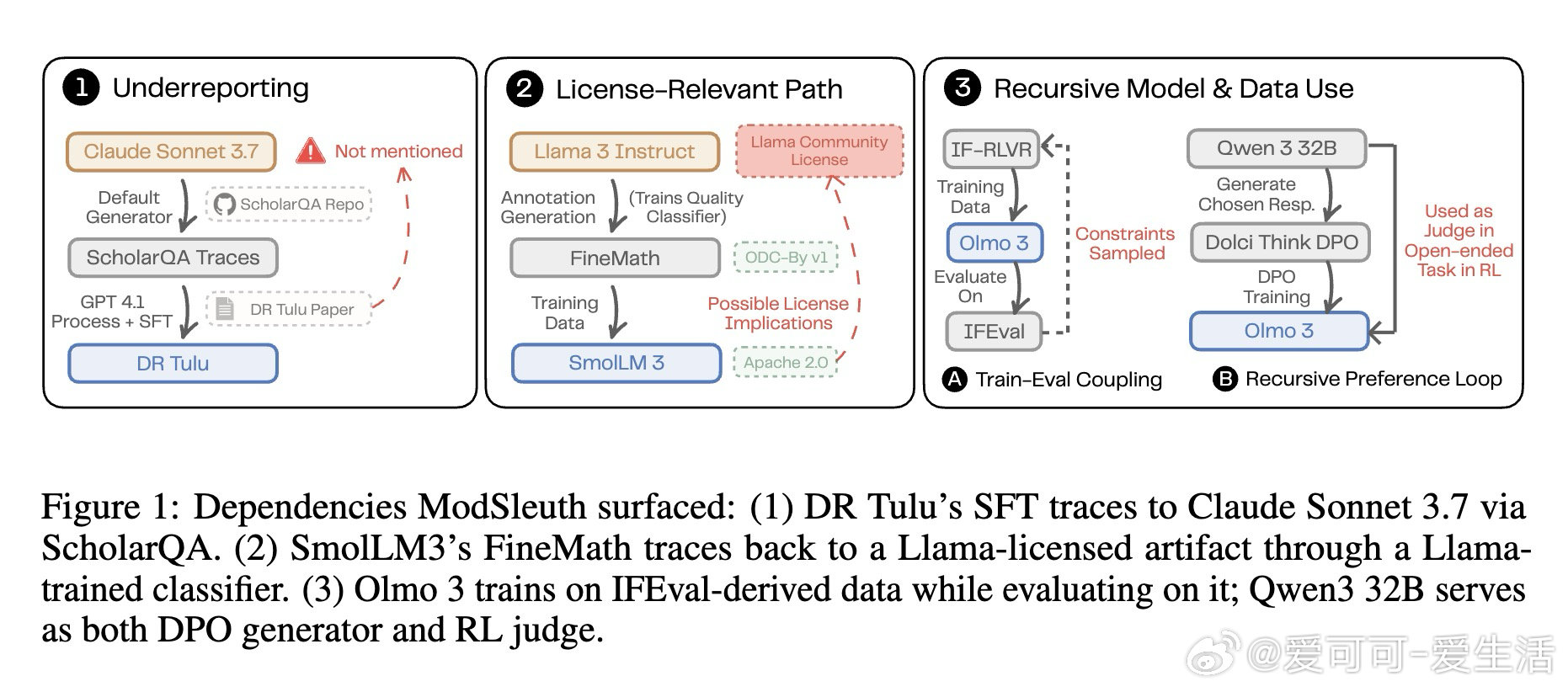
现代大语言模型的训练管道愈发依赖上游模型完成数据生成、过滤、标注、评估等多阶段任务,形成递归依赖链。这些依赖信息散落在技术报告、模型卡、代码仓库等异构文档中,深度和复杂度已远超人工追溯能力——即使是模型开发者自己,也难以完整梳理依赖全貌。缺乏透明的依赖结构,会导致许可证约束隐性传播、数据污染通过多跳路径扩散、评估循环性偏差等无法被发现的风险。
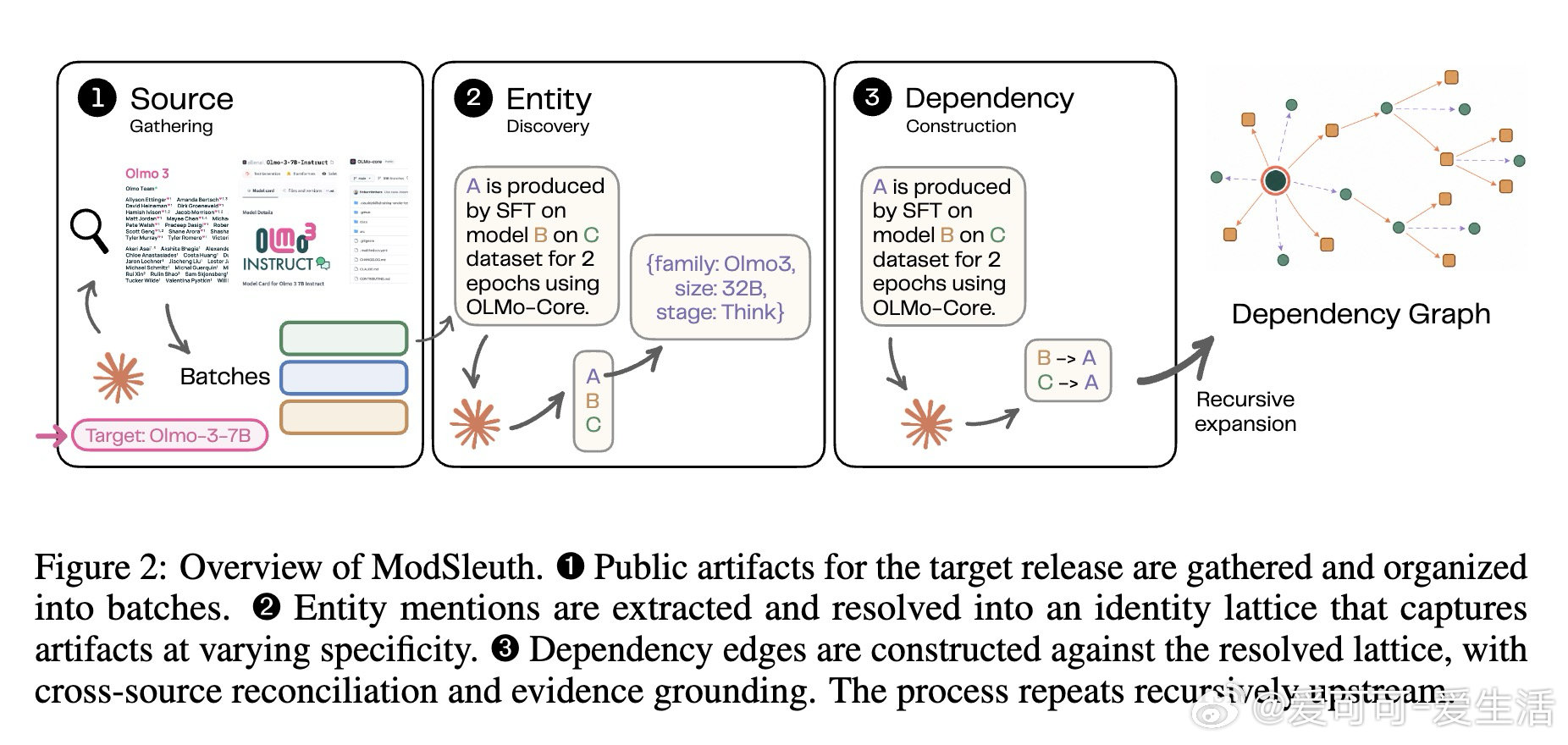
本文将问题重构为证据溯源图构建任务:从公开文档中递归提取模型与数据集节点及其关系边,并通过身份格(identity lattice)解决跨文档的实体消歧问题。核心洞见是将依赖分为直接依赖(影响权重或训练数据)与间接依赖(影响开发决策),用操作中心的关系表示(如生成、过滤、重写、评估)替代固定分类法,用溯源证据锚点强制每条边可验证。ModSleuth 系统以此设计实现了分阶段代理流水线:先收集官方文档批次,再发现并解析实体提及,最后跨源对账构建依赖图并递归扩展上游。
这项工作将碎片化的公开证据转化为可审计的依赖图谱,揭示了现代大模型生态远比此前认知更加互联与递归。在四个公开文档丰富的模型发布中,ModSleuth 恢复了超过 1000 条经验证的依赖关系,暴露出多跳许可证传播路径、训练-评估耦合、发布文档与实际训练差异等单一文档无法浮现的问题。但该方法仅能追踪已公开声明的依赖,对未披露或闭源依赖无能为力;且评估依赖单一模型族,共享建模偏差的风险尚未充分量化。未来透明化工作需从平面文档转向显式表达依赖结构、证据和角色语义的披露机制。
arxiv.org/abs/2606.12385 机器学习 人工智能 论文 AI创造营