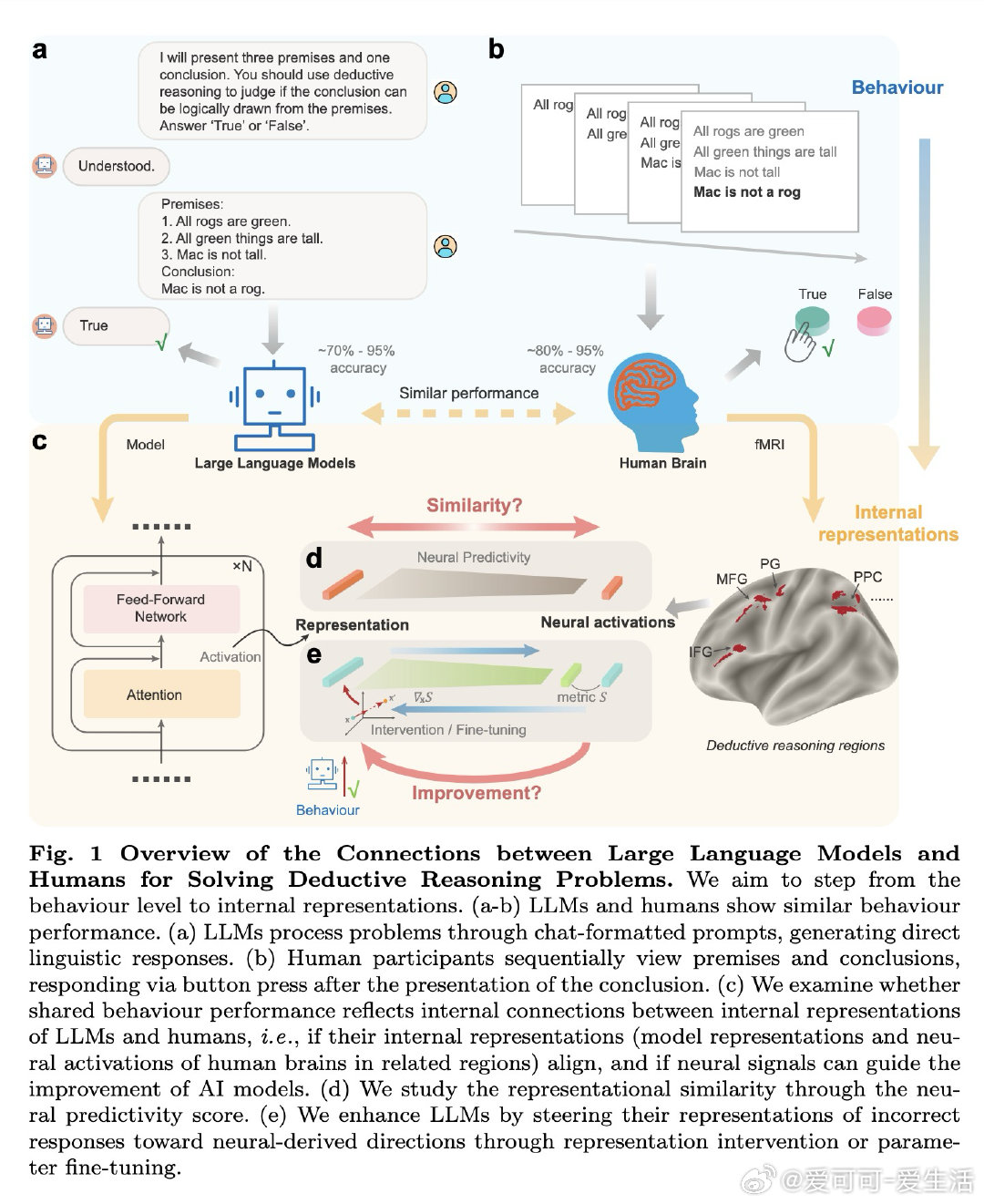
[LG]《Beyond representational alignment with brain-guided language models for robust reasoning》M Xiao, K Du, Z Lin [Peking University & Tsinghua University] (2026)
在推理领域,大语言模型虽能完成某些逻辑任务,但在超出训练分布的简单问题上仍表现脆弱。更深层的争议在于:这些模型是否真正具备类人认知机制,还是仅在利用统计模式?已知人脑的语言区与推理区存在神经解剖学分离,而LLM仅从文本学习——这种训练范式能否孕育出与人类推理网络结构对齐的内部表征,尚无定论。
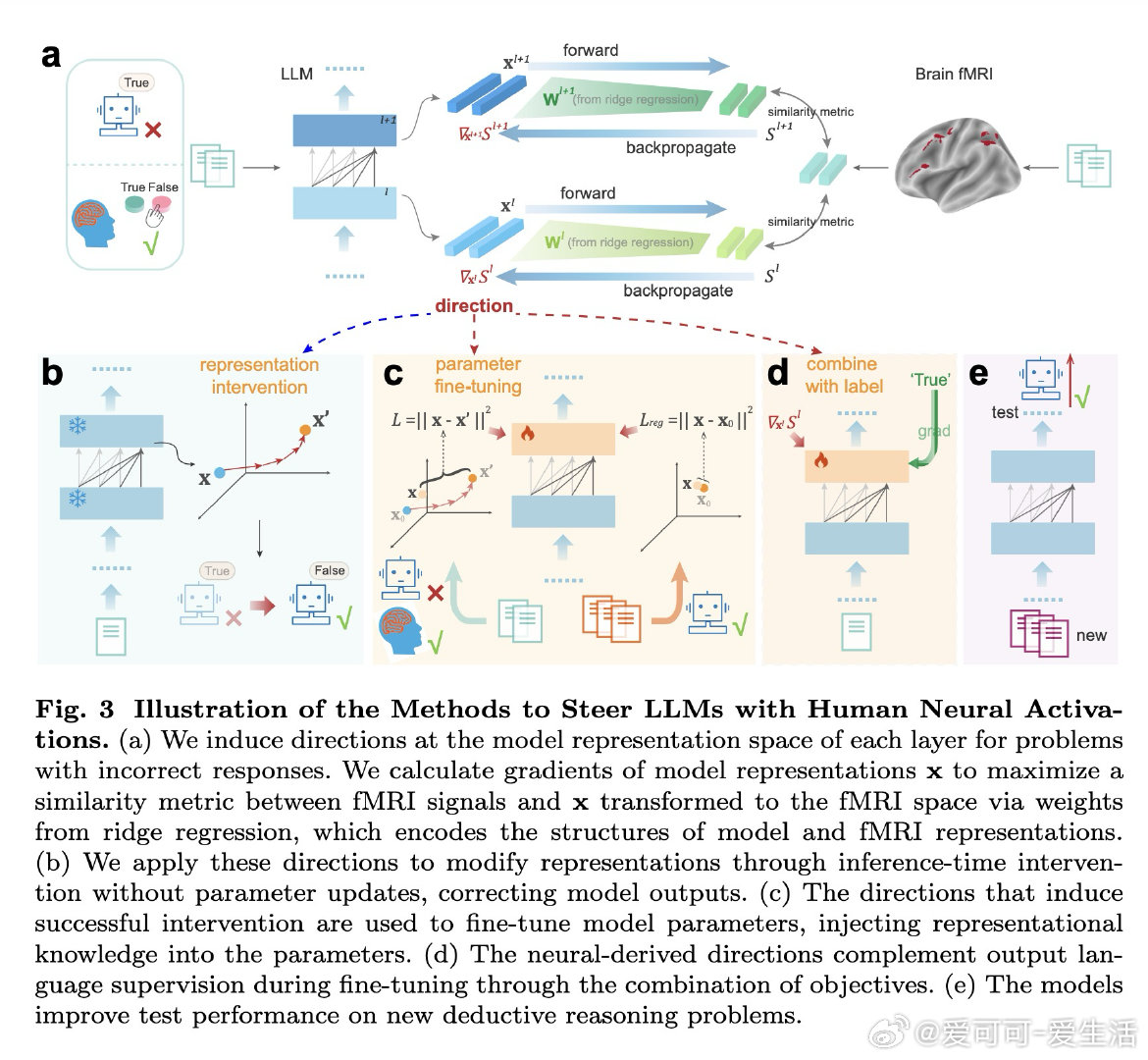
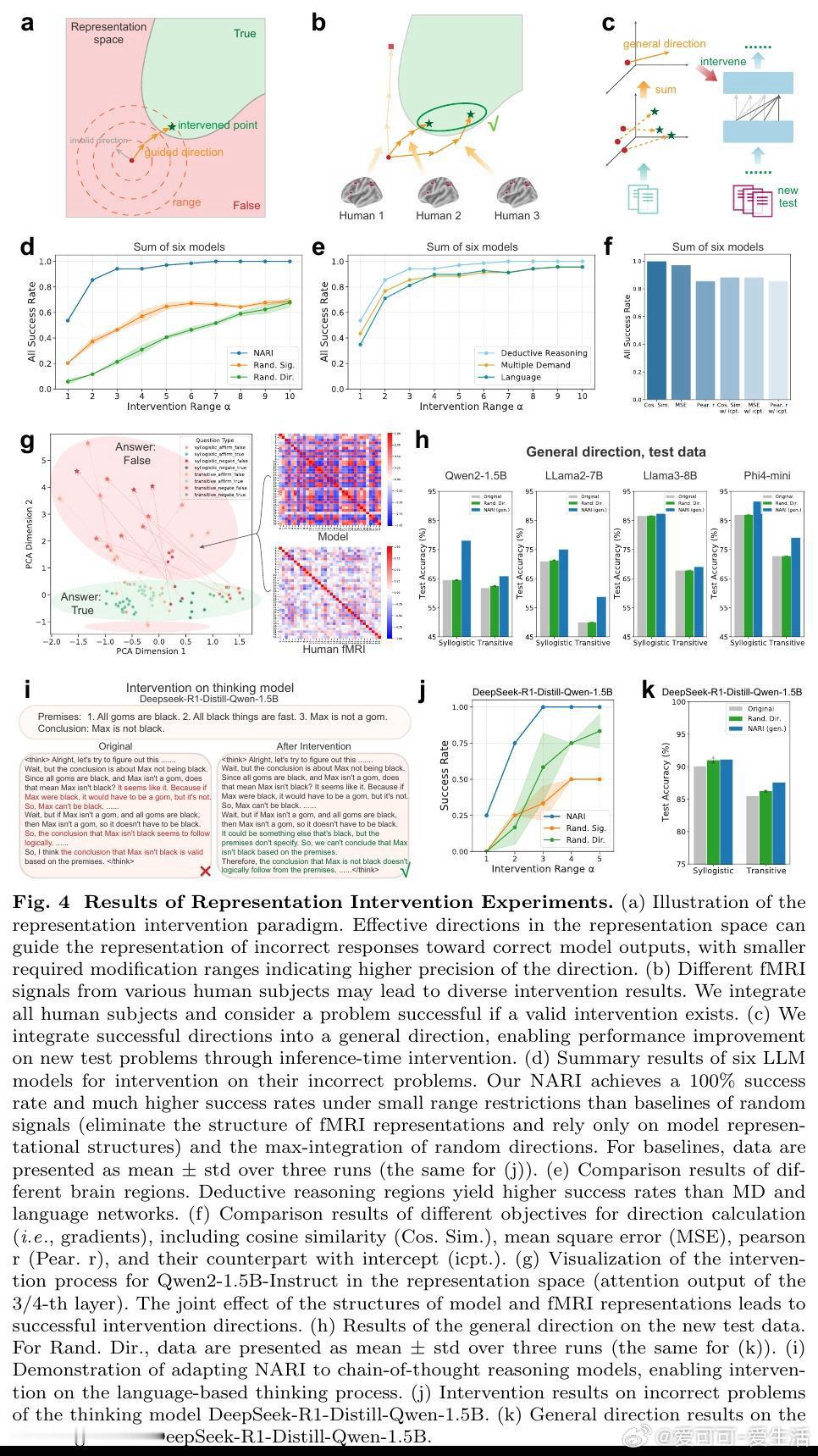
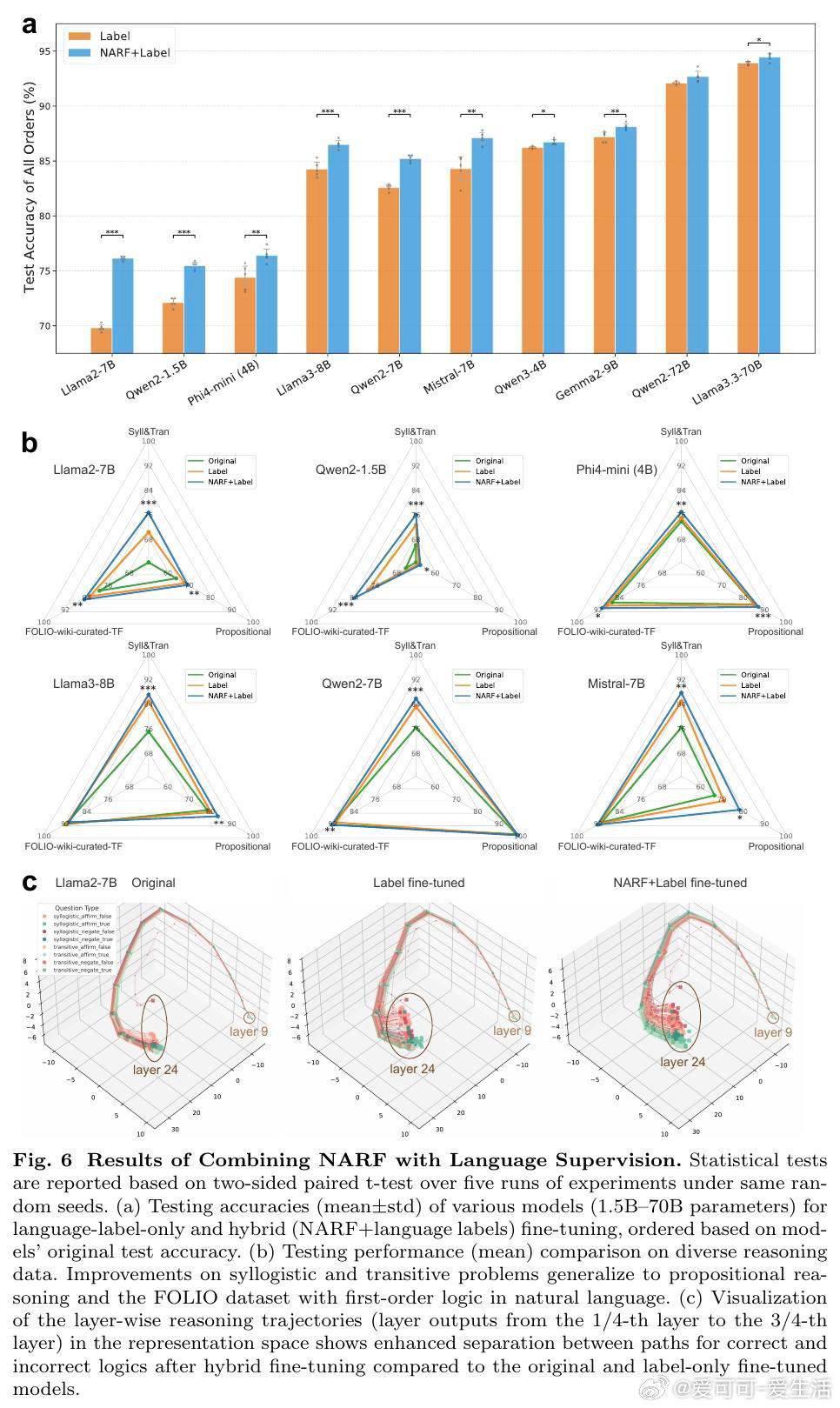
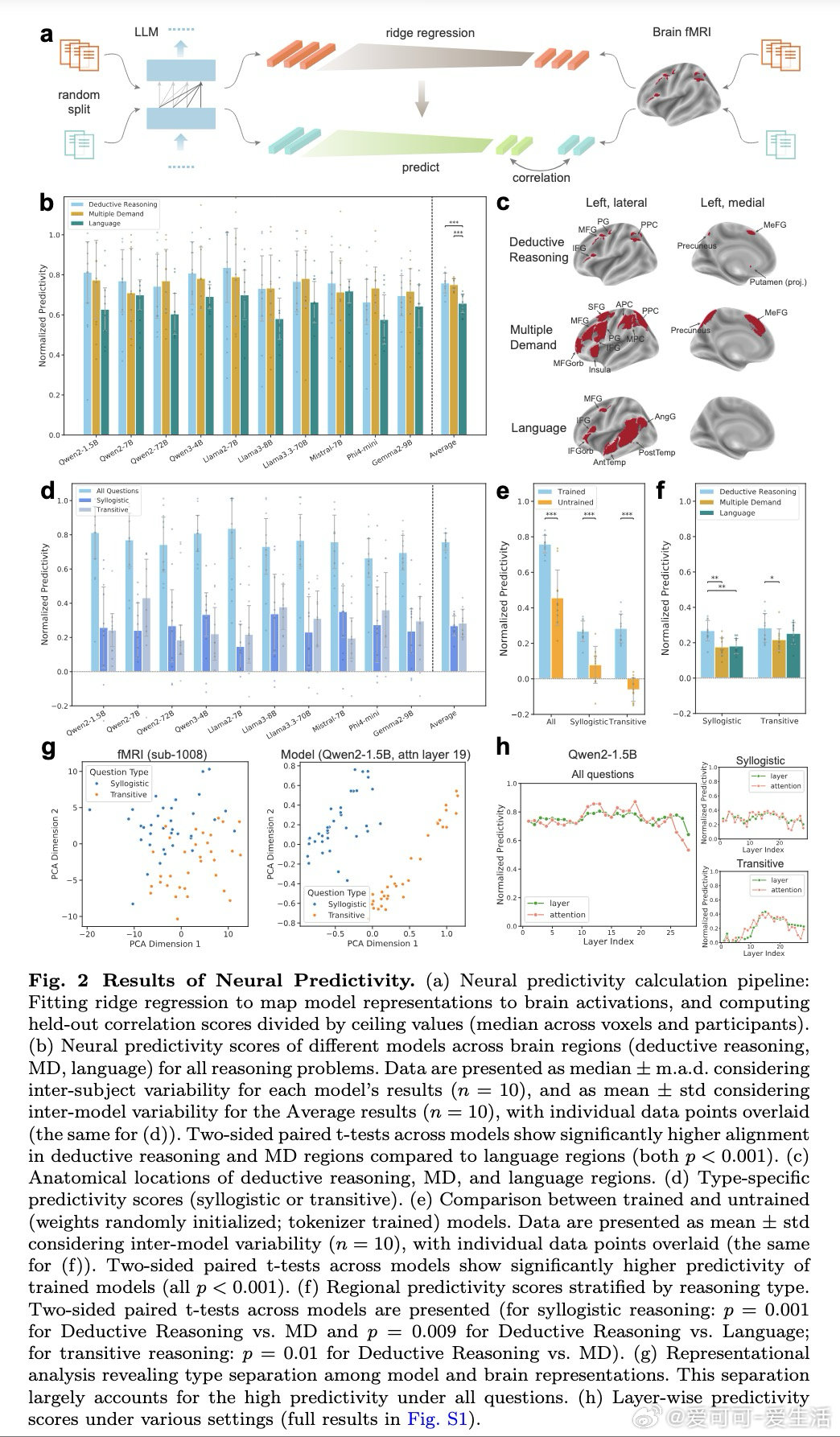
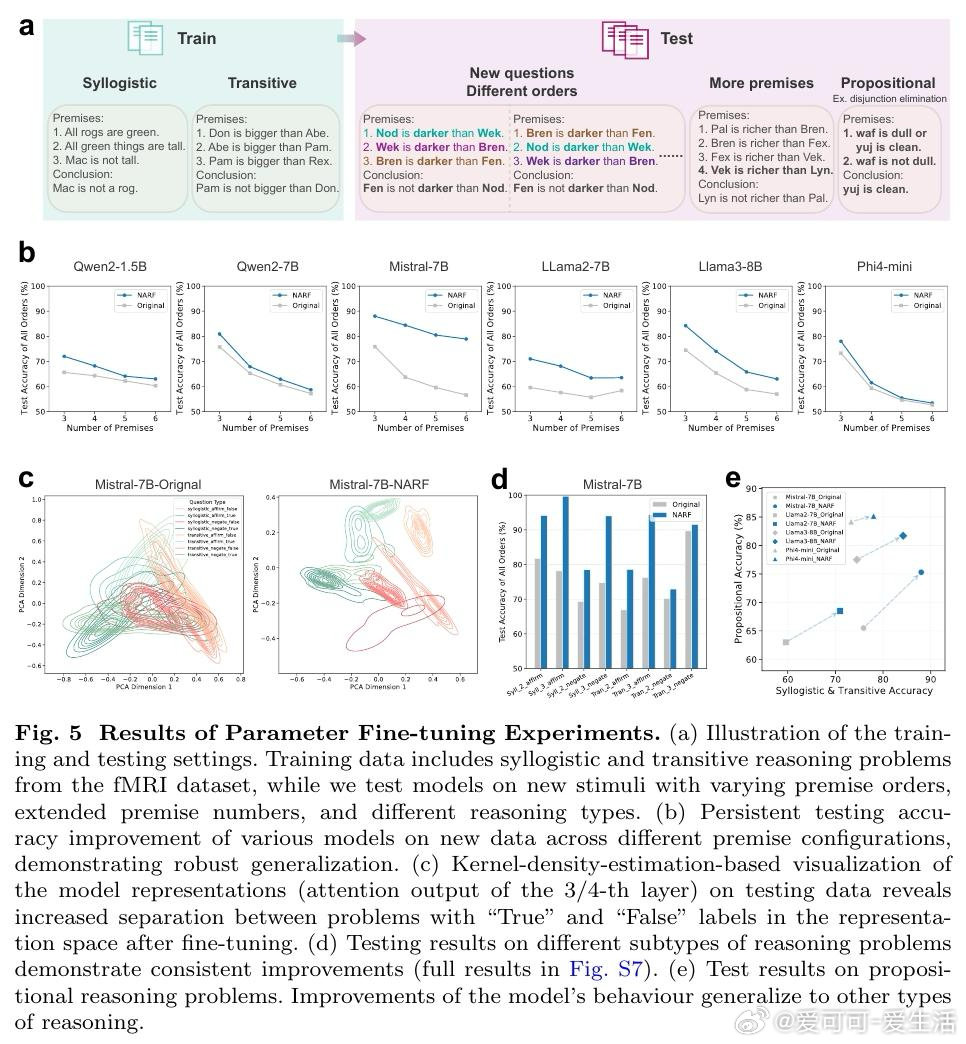
本文通过fMRI信号揭示:LLM内部表征与人脑推理区神经激活存在部分对齐(可解释约76%的可解释方差),但单一推理类型内对齐度较低(约27%)。基于此发现,作者提出神经激活引导的表征干预(NARI)和微调(NARF)框架——利用脑信号与模型表征的联合结构计算梯度方向,在推理错误时实时修正表征或将神经知识内化至参数。该方法在10个模型(1.5B-72B参数)上验证,准确率提升最高达13%,且能跨推理类型泛化。
这项工作将LLM-脑科学关联从"相关性观察"推进至"功能性引导":首次证明认知神经信号可直接提升AI推理能力,开辟了一条不依赖语言监督、直接从人脑表征学习中间过程的路径。其遗产在于确立了神经数据作为模型优化信号源的可行性,为构建认知对齐的AI系统提供方法论范式。但尚未跨越的门槛包括:当前方法依赖fMRI的慢血流动力学响应,无法捕捉快速推理的动态过程;且在更复杂认知任务和更大模型上的扩展性仍待验证。
arxiv.org/abs/2606.11893 机器学习 人工智能 论文 AI创造营