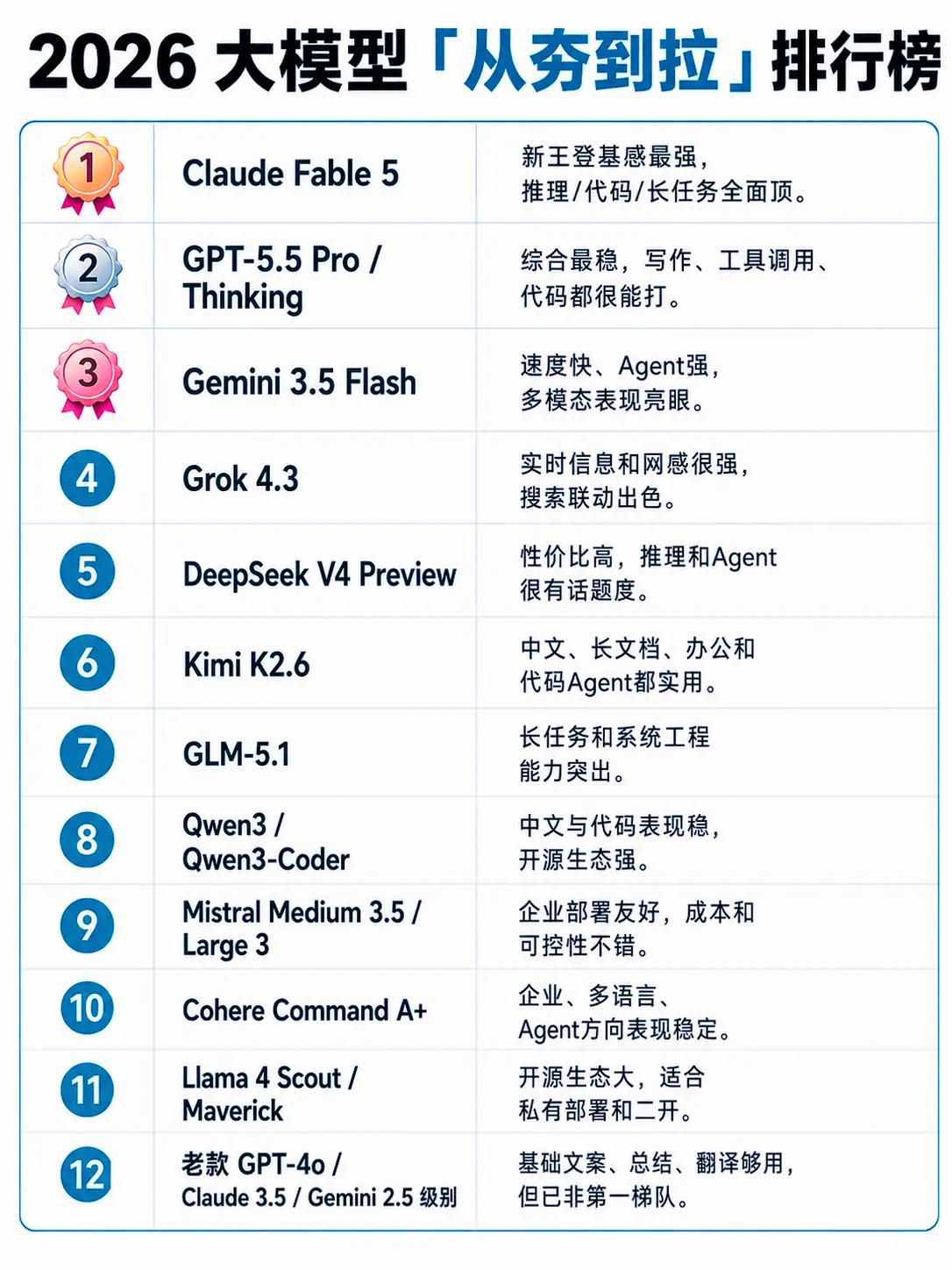
2026大模型「从夯到拉」榜单工程视角解读
这份榜单以实战落地价值为核心,按「能力强→弱」排序,覆盖通用、推理、Agent、代码、中文场景、开源部署等维度,以下是精简工程视角解读:
第一梯队:全能型底座(1-3)
1. Claude Fable 5
当前工程落地首选的「全能王者」,推理、代码、长任务全面领先,百万级上下文稳定性极强,安全策略完善,是企业级RAG和Agent架构的首选底座。适合复杂系统工程、高合规要求场景,防蒸馏降智策略是主要争议点。
2. GPT-5.5 Pro / Thinking
综合能力最稳的「通用标杆」,写作、工具调用、代码均衡,生态插件与Harness架构适配度最高,是Agent原型验证和通用场景的安全选择,Thinking版本在复杂推理上表现突出。
3. Gemini 3.5 Flash
速度与Agent能力双优的「多模态先锋」,响应快,多模态理解和Agent编排亮眼,结合谷歌生态可实现信息检索闭环,适合实时交互、多模态分析场景,国内访问稳定性是主要短板。
第二梯队:专项能力突出(4-6)
4. Grok 4.3
实时信息与网感优势明显的「搜索联动专家」,联网检索能力强,适合资讯类、舆情分析场景,对传统工程场景适配度有限。
5. DeepSeek V4 Preview
高性价比的「推理与Agent黑马」,推理和Agent编排话题度高,成本优势显著,是国内开发者搭建低成本Agent的优选,部分场景稳定性不及头部模型。
6. Kimi K2.6
中文场景优化的「办公与代码Agent实用派」,中文理解、长文档处理、办公适配度高,适合国内团队快速搭建轻量级应用。
第三梯队:垂直场景与开源生态(7-11)
7. GLM-5.1
国产工程向模型,长任务与系统工程能力突出,对国内企业部署环境友好,适合大型项目文档分析、系统架构梳理。
8. Qwen3 / Qwen3-Coder
中文与代码表现稳定的「开源生态标杆」,开源生态完善,支持二开和私有化部署,是国内开发者常用选择。
9. Mistral Medium 3.5 / Large 3
企业部署友好的「成本与可控性平衡之选」,部署成本低,可控性强,适合企业内部知识库、客服系统等批量处理场景。
10. Cohere Command A+
企业多语言与Agent场景的「稳定派」,多语言支持完善,Agent方向表现稳定,适合跨国企业或多语言场景。
11. Llama 4 Scout / Maverick
开源生态庞大的「私有化部署首选」,社区工具链成熟,支持私有部署和深度二开,适合有定制化需求的团队。
垫底梯队:老款模型(12)
12. 老款GPT-4o / Claude 3.5 / Gemini 2.5级别
仅能满足基础文案、总结、翻译等轻量任务,已退出第一梯队,不建议作为新Agent项目的底座。
工程落地选型速记:
- 通用型Agent/复杂任务优先选 Claude Fable 5 或 GPT-5.5 Pro;
- 成本敏感的国内场景优先考虑 DeepSeek V4 或 Qwen3;
- 私有化部署/企业可控性需求优先选 Llama 4 或 Mistral系列;
- 中文办公场景优先考虑 Kimi K2.6。
大模型数据困境 开源模型测评 AHP层次分析 大模型代码 大模型推荐系统 ito基石 智能测试框架