Kimi K2.7-Code 新版编码模型简评
一、核心升级亮点
1. 编码能力大幅跃升
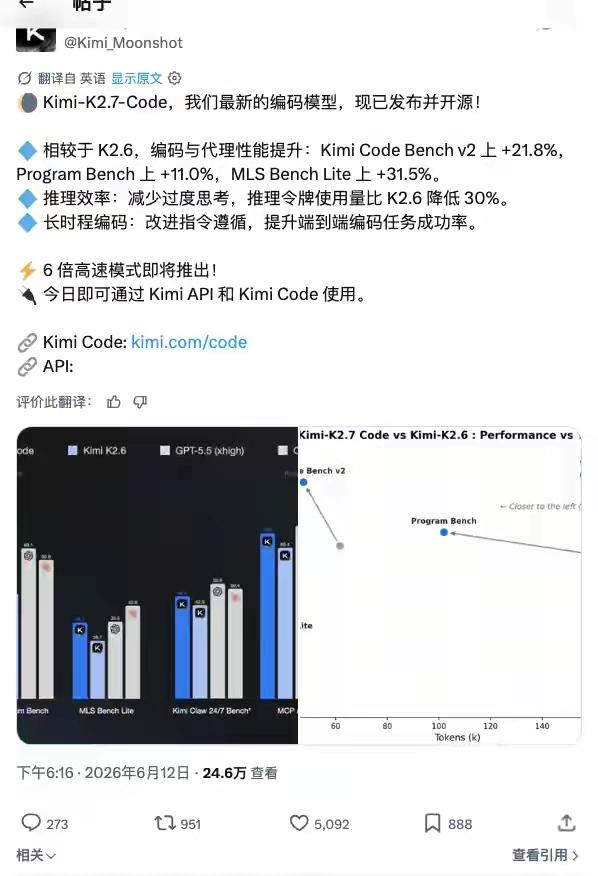
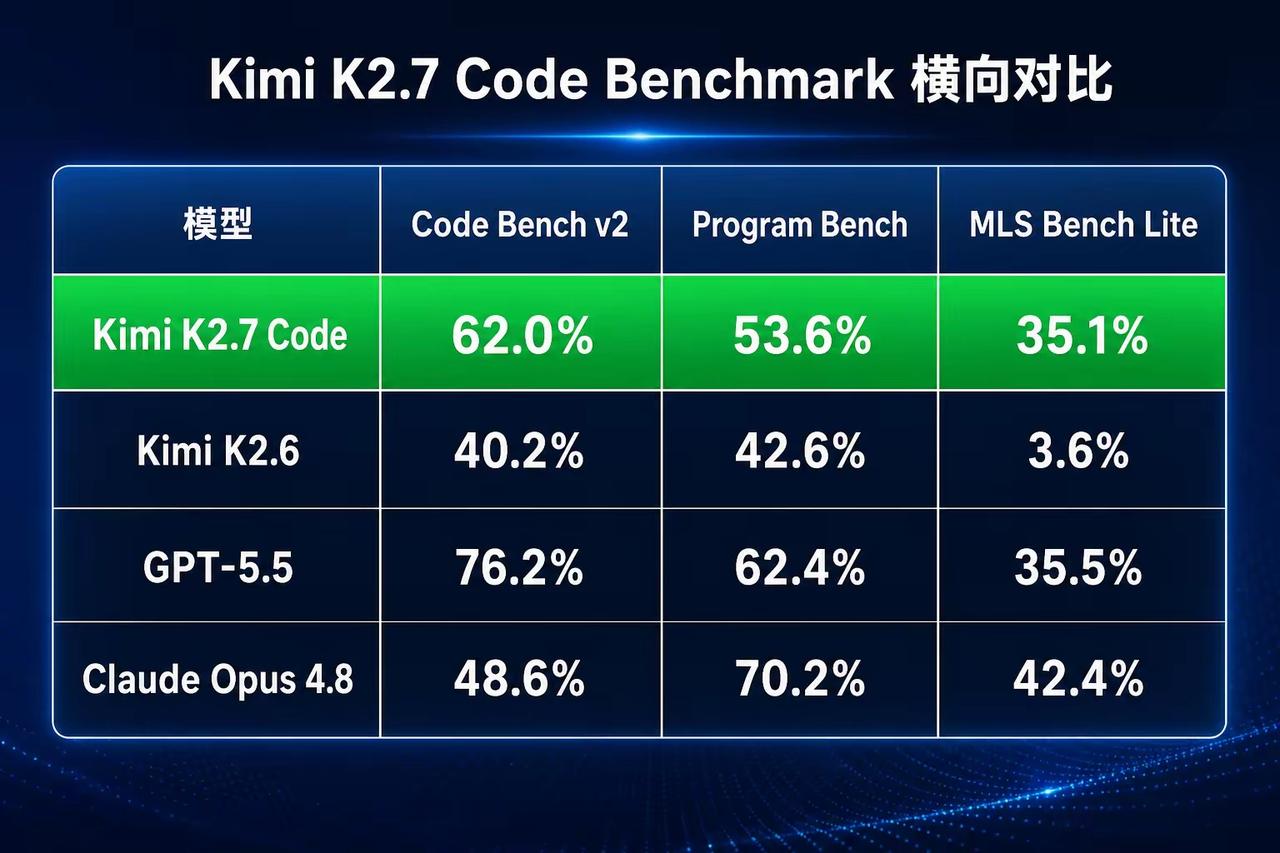
对比上一代K2.6:Code Bench v2提升21.8%、Program Bench提升11%、MLS Bench Lite暴涨31.5%,多场景代码完成度全面拉高。
2. Token成本直降30%
优化冗余思考逻辑,推理阶段token消耗显著减少,长期开发调用成本更低。
3. 长代码任务更稳
优化指令遵循能力,多文件、端到端完整项目的交付成功率提升,适配大型工程开发。
4. 高速模式即将上线
6倍加速版本筹备推出,后续代码生成响应速度会大幅提升。
5. 开放可用
现已开放API与Kimi Code网页端使用,模型同步开源。
二、横向对标现状
- 对比GPT-5.5:整体仍有差距,但MLS轻量场景得分几乎追平;
- 对比Claude Opus 4.8:通用代码基准更高,复杂程序推理、数学代码场景仍落后;
- 自身迭代优势突出,是国产编码模型里进步幅度很大的版本。
三、落地适配场景
适合国内开发者做Web、后端、轻量算法项目,中文注释、国内开发框架适配天然友好;搭配MCP、Agent工作台搭建成本更低,兼顾性能与开销。
四、客观短板
距离GPT-5.5、Claude Fable 5这类头部编码模型仍存在明显分差,超大型多文件工程、深度逻辑推理场景还有追赶空间。
互动提问:你平时写代码更看重token成本,还是纯代码基准得分?
AI代码理解 AIGEO模型 AI提效创作 ai代码索引 代码评测 NPC代码 rubii指令