最近美国大模型性能上去了,中国落后的差距在拉大。原因是工程和生态的,可以解释,没有秘密
大模型训练、推理,这些大方向的技术,预训练、后训练,RLHF,MOE架构,思维链,智能体,没有秘密的概念。一个前沿大模型,怎么做出来的,业界都知道,没有技术秘密。
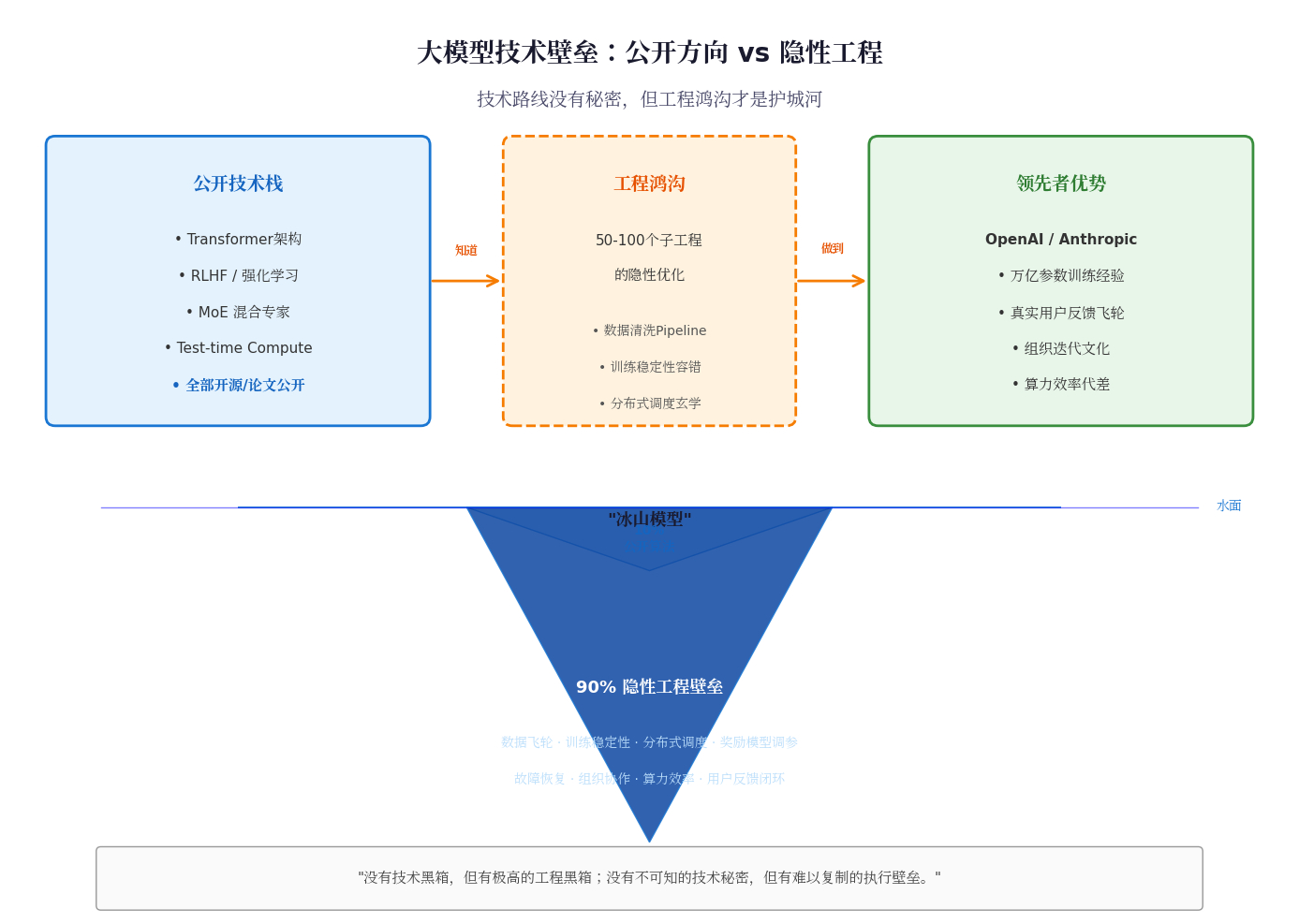
但是大模型开发难度极高,它到底难在哪?一个是要很多卡,这是门槛,但有足够卡的公司也有好几家了,这不是最关键的。
现在大模型很讲究性能,同样的架构、同样的算力,一伙最顶级的牛人去开发能到95分,另一伙水平差了一点的(也全是精英)可能就只有80分了。美国几家公司就是这个情况,Anthropic和OpenAI的开发团队明显领先。但是Meta、xAI这几家也有很多卡,开发团队明显要差不少。
团队领先,不是说人的钱多,而是牛人足够多,还组织良好,把非常精细的研发架构搭起来了。大模型最根本的特点,它是一个庞大的开发工程,里面可能有上百个小细节,无数个know-how。细节全部都做好,才能达到不错的水平。光知道理论没有用,不去实际摸索,连细节是什么都不知道。所有细节都差不多补好了,大模型性能才能达到业界顶级。
差一些的,肯定是某些细节做得不到位。但想到位就没那么简单,因为大模型开发代价非常高,训练一次都在烧钱,时间也不短,并不是很容易调试。来来回回打磨,才慢慢能把一些没到位的细节补好。但领先者又进步了,这边还有些细节没补好。想追前沿,真不容易。
中国大模型公司,在团队搭建方面,其实很厉害了。以DeepSeek为代表的几个公司,用不高的代价,组织了不少人,去磨细节,还真的把平台搭起来了,陆续推出了前沿大模型。而且这个能力似乎还在扩散,能把研发平台搭起来的公司越来越多,上人去磨细节,中国公司不怕。
中国与美国头部公司的细节都到位了,2025年初DeepSeek R1推出的时候,和美国领先大模型几乎没差距了,从感觉来说,应该是差距最小的时候。但为什么后面差距又大了一些?应该是算力和生态的差别,终于起作用了。
OpenAI和Anthropic工程体系不说领先中国头部公司,至少不差。他们领先的是,数据飞轮与反馈闭环。ChatGPT和Claude有海量真实的个人与公司用户,数据质量、多样性和标注深度明显领先中国公司,绝大部分是私密的。公开数据集大家都能用,但真实场景下的高质量反馈数据是封闭的。这是一个大的差距。
再一个是算力基础设施的代差。GPU数量,还有数据中心的网络拓扑、故障恢复基础设施的成熟度,中国还有国产化的任务。这方面算力总量、稳定性,美国还是有优势的。在摸新的know-how时,不能只靠中国天才的聪明才智,需要实际跑任务,海量跑,堆算力跑。
这两个原因,让美国头部公司在开发速度上,领先了中国一段时间。没有技术秘密,但有海量的工程know-how,需要算力和生态去弥补。
评论列表