在大模型训练中,我们一直面临一个痛点:高质量的推理数据是有限的。
一旦模型学完了人类编写的高质量数据,推理能力的提升往往就会撞上天花板。
最近,来自斯坦福大学的研究团队发表了一篇名为 Scaling Self-Play with Self-Guidance 的论文。他们提出了一种名为 SGS (Self-Guided Self-Play) 的算法,试图彻底打破这一瓶颈。
简单来说,这项工作让模型不仅能做题,还能自动出题、自己审题,从而在不需要更多人类介入的情况下,进一步提升后训练和微调的效果,实现模型推理能力的持续缩放(Scaling)。
现在前沿模型公司,后训练和微调的时候都会使用自博弈(Self-Play)方法
自博弈(Self-Play)的核心理念是:出题者(Conjecturer)负责出题,解题者(Solver)负责做题,两者在对抗中不断进步。在理想状态下,这个过程是没有天花板的。
但在现实训练中,这类方法通常会陷入 “学习停滞”(Learning Plateau):
出题者很快就会发现,只要生成一些逻辑混乱、故意堆砌复杂词汇但又不合逻辑的题目,解题者就很难解出,或者产生某种“虚假提升”。
训练退化:由于缺乏有效的监督,随着训练周期拉长,合成数据的质量迅速下降,导致模型不仅没学到新知识,反而越练越笨。
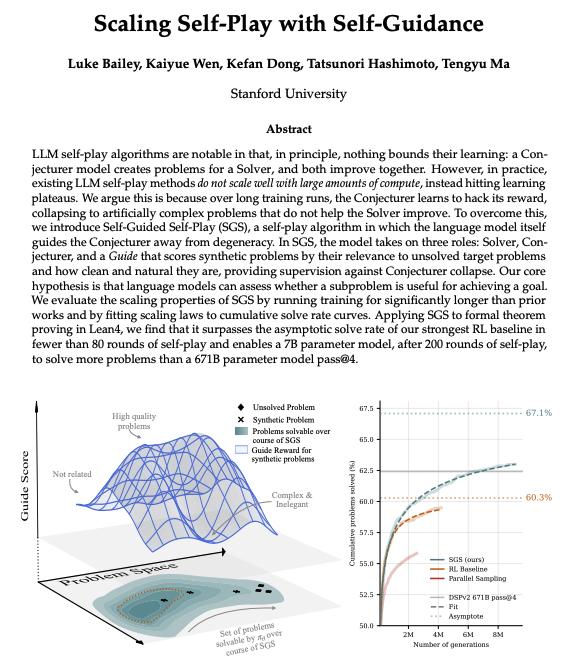
为了解决这一问题,SGS 引入了一个至关重要的角色——引导者(Guide)。在 SGS 框架下,LLM 同时担任三个角色:
Solver (解题者):负责求解问题。
Conjecturer (出题者):负责生成相关的合成问题,难度需与当前目标匹配。
Guide (引导者):作为质量把关人,它负责评估出题者生成的题目质量。
Guide 会根据题目与目标任务的相关性、结论的简洁性以及逻辑的自然度进行评分。如果出题者试图通过“制造复杂逻辑冗余”来蒙混过关,Guide 会直接给出低分,强迫出题者回到高质量的学习路径上。
研究团队在 Lean4 形式化定理证明任务上验证了 SGS 的性能:
真正的持续 Scaling:在长周期的训练中(训练步数远超以往工作),SGS 的累计解题率表现出了极好的缩放特性,并没有出现以往常见的性能退化。
经过 SGS 长周期自我训练后,一个 7B 参数的模型,其推理能力甚至超越了未经过此类训练的 671B 参数模型(DeepSeek-Prover-V2)。
SGS 的意义,可以看成是 LLM后训练/微调领域的“AlphaZero 时刻”并不为过。它代表了一种重大的训练范式转变:
从单纯依赖人类标注数据的“手工作坊”模式,转向利用算法闭环自动生成高质量训练数据的“智能工厂”模式。
SGS 证明了在推理能力上,我们同样可以拥有“扩展定律”(Scaling Laws)。只要计算资源(Compute)充足,并且通过 Guide 机制守住数据质量,模型能力的提升就是可预测、可扩展的。
目前 SGS 在形式化验证领域(Lean4)已经证明了其价值。下一步的挑战在于如何将这种自我引导机制扩展到代码生成、复杂决策、甚至更广泛的通用逻辑推理领域。
我们可能正处于 又一次模型能力指数级增长的起点。