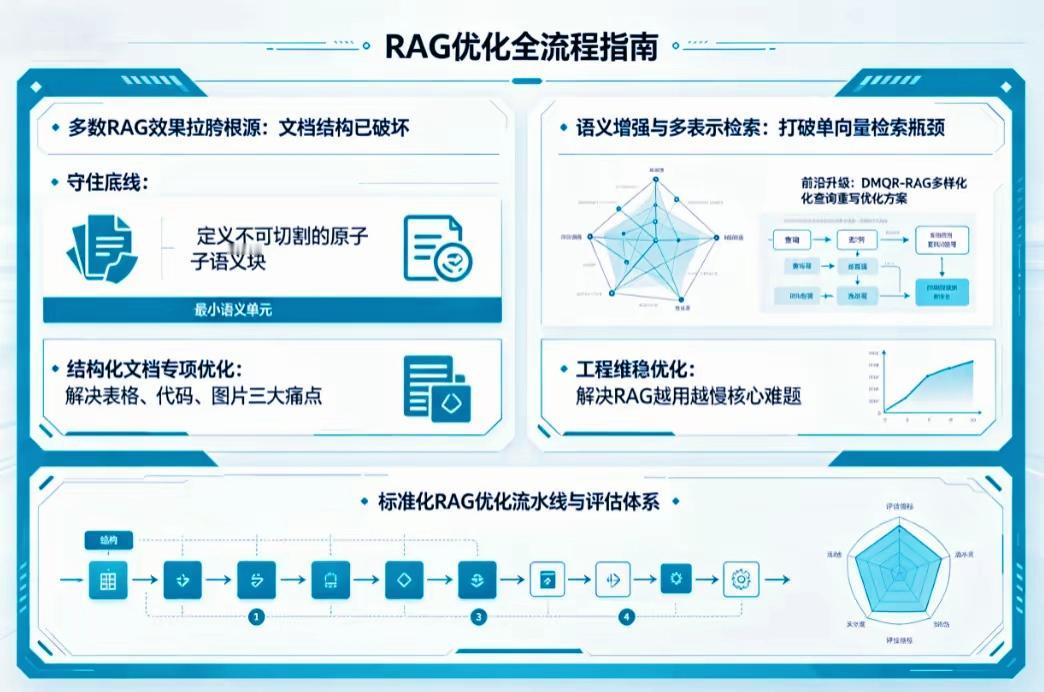
RAG全流程工程优化完整拆解
一、RAG效果差的核心根源:文档结构被破坏
绝大多数检索问答效果失真、答非所问,根源是粗暴文本切分割裂语义完整单元。
底线优化:定义原子语义块
把文档拆分为不可切割的最小语义单元,保证单块内容逻辑闭环、上下文完整;避免按固定字符长度粗暴截断表格、代码、章节段落,从源头规避语义残缺问题。
结构化文档专项优化
针对性解决三类高频痛点:
1. 表格:保留行列关联关系,转换为带语义描述的结构化文本,防止拆分后行列数据失联;
2. 代码:以函数/类为完整单元切块,保留注释、入参、返回值完整上下文;
3. 图片:通过OCR+图文语义绑定,将图表说明、标注与图像文本合并为完整语义块,避免图文信息分离。
二、检索层前沿突破:语义增强+多表示检索
单向量检索存在语义模糊、歧义匹配短板,通过多维度检索方案突破瓶颈:
1. 多表示向量网络:同一文档块生成多条不同维度向量(关键词向量、语义向量、摘要向量),构建多维语义空间,提升模糊问题、长句问题召回精度;
2. DMQR-RAG多样化查询重写:一套标准化查询增强链路,对原始问题做改写、拆分、扩写、多视角生成,批量生成多条检索问句,覆盖用户真实隐藏诉求,大幅降低漏召回。
三、工程维稳优化:解决“RAG越用越慢”
业务长期运行会出现向量库膨胀、检索延迟持续走高、吞吐下滑问题,核心优化手段:
- 向量分库分表、冷热数据分离,高频文档单独索引;
- 增量向量化机制,避免全量文档重刷向量;
- 检索结果缓存、相似度阈值动态过滤,减少无效向量计算;
- 索引压缩、量化存储,降低内存与检索耗时,保证大规模知识库长期稳定响应。
四、标准化RAG完整流水线+量化评估体系
端到端标准化流水线
文档载入 → 结构化解析 → 原子语义分块 → 多模态信息融合(图/表/代码) → 多向量编码入库 → 查询增强改写 → 多维混合检索 → 检索重排(Rerank) → 上下文压缩过滤 → Prompt组装 → LLM生成回答 → 结果校验复盘
全链路每个环节均可单独调参、替换组件,适配不同行业知识库。
五维量化评估体系
采用五边形指标综合衡量RAG效果,避免单一指标判断偏差:
1. 召回率:相关文档片段是否全部检索出来;
2. 精准度:召回内容是否与问题强相关、无冗余;
3. 忠实度:大模型回答是否完全依托检索文档,无幻觉编造;
4. 完备度:回答是否完整覆盖问题全部要点;
5. 流畅度:输出文本逻辑通顺、无拼接割裂感。
行业落地总结
1. 基础层优化优先:保留文档完整语义结构是所有RAG效果的底线,切分策略直接决定上下限;
2. 检索层决定上限:单向量检索无法应对复杂业务,多表示+查询重写是当前工业界主流升级方案;
3. 长期运行重点看工程维稳:不做分库、缓存、增量优化,知识库扩容后会出现明显性能瓶颈;
4. 必须配套量化评估:依靠人工主观判断无法持续迭代,五维指标可自动化批量评测每一轮优化收益。
企业GEO优化 geo优化系统 企业流程优化 geo优化流程 流程拆解法 最佳优化方案 何为优化