[LG]《STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability》H Luo, Q Sun, S Wu, C Xu… [Tencent Hunyuan & Tsinghua University] (2026)
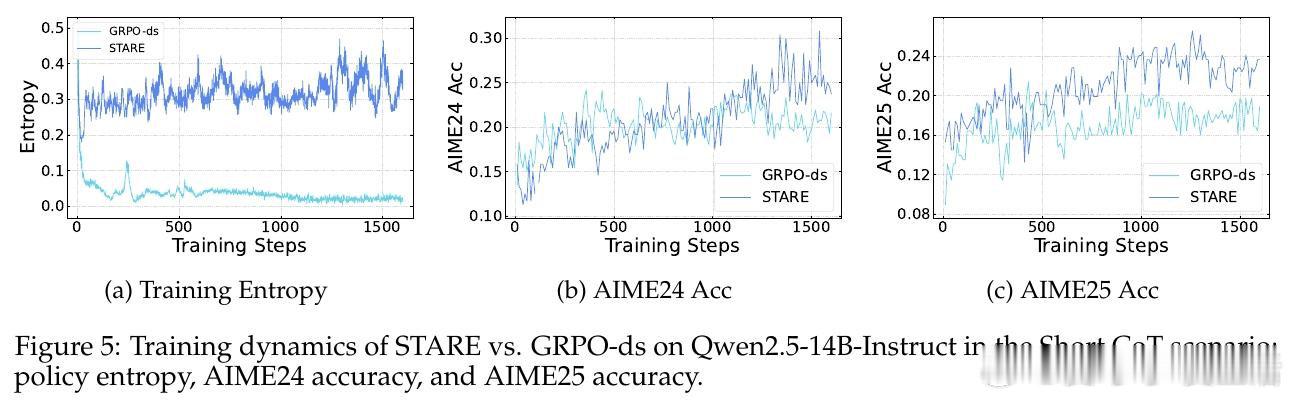
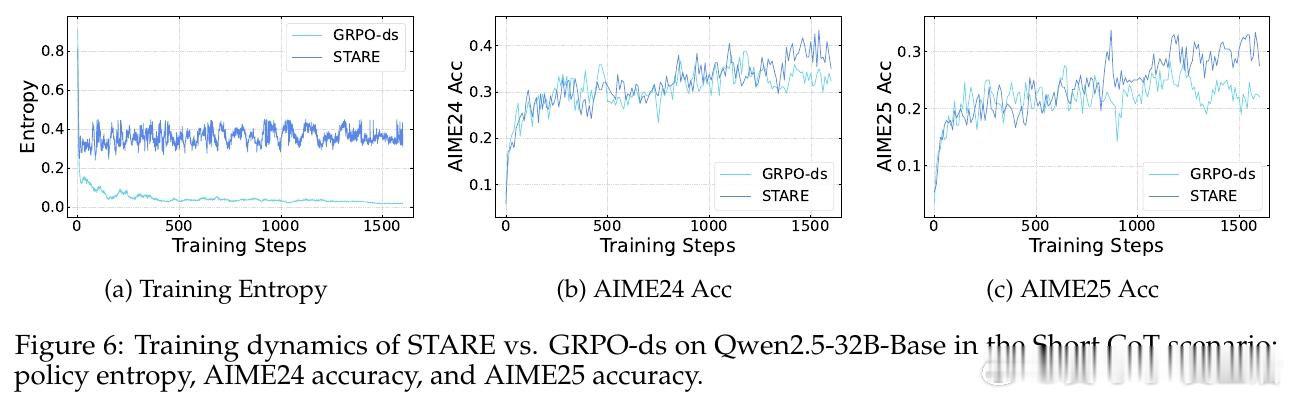
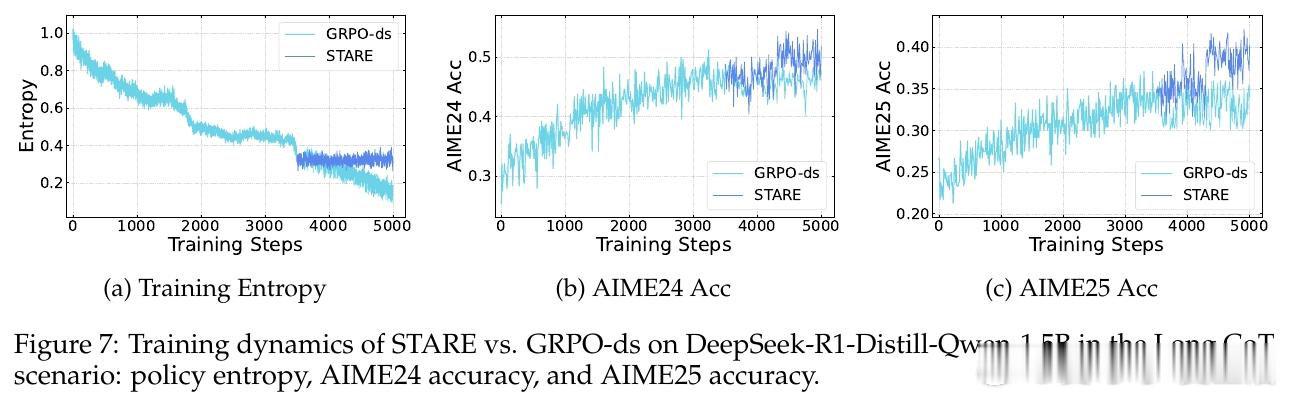
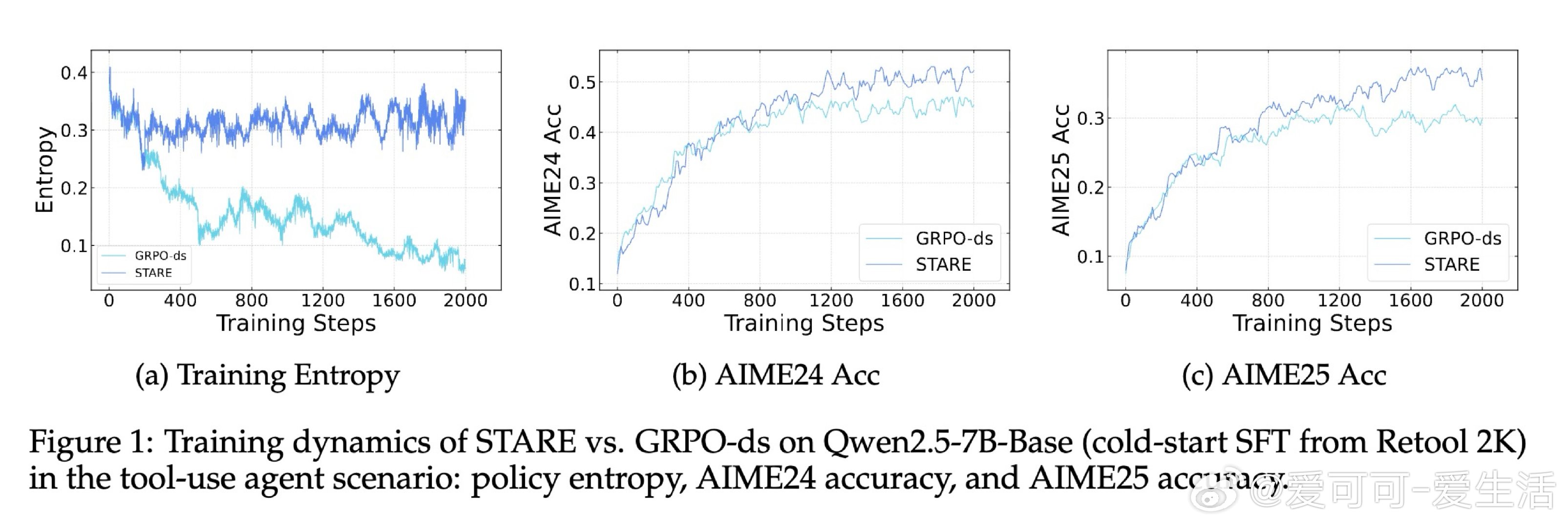
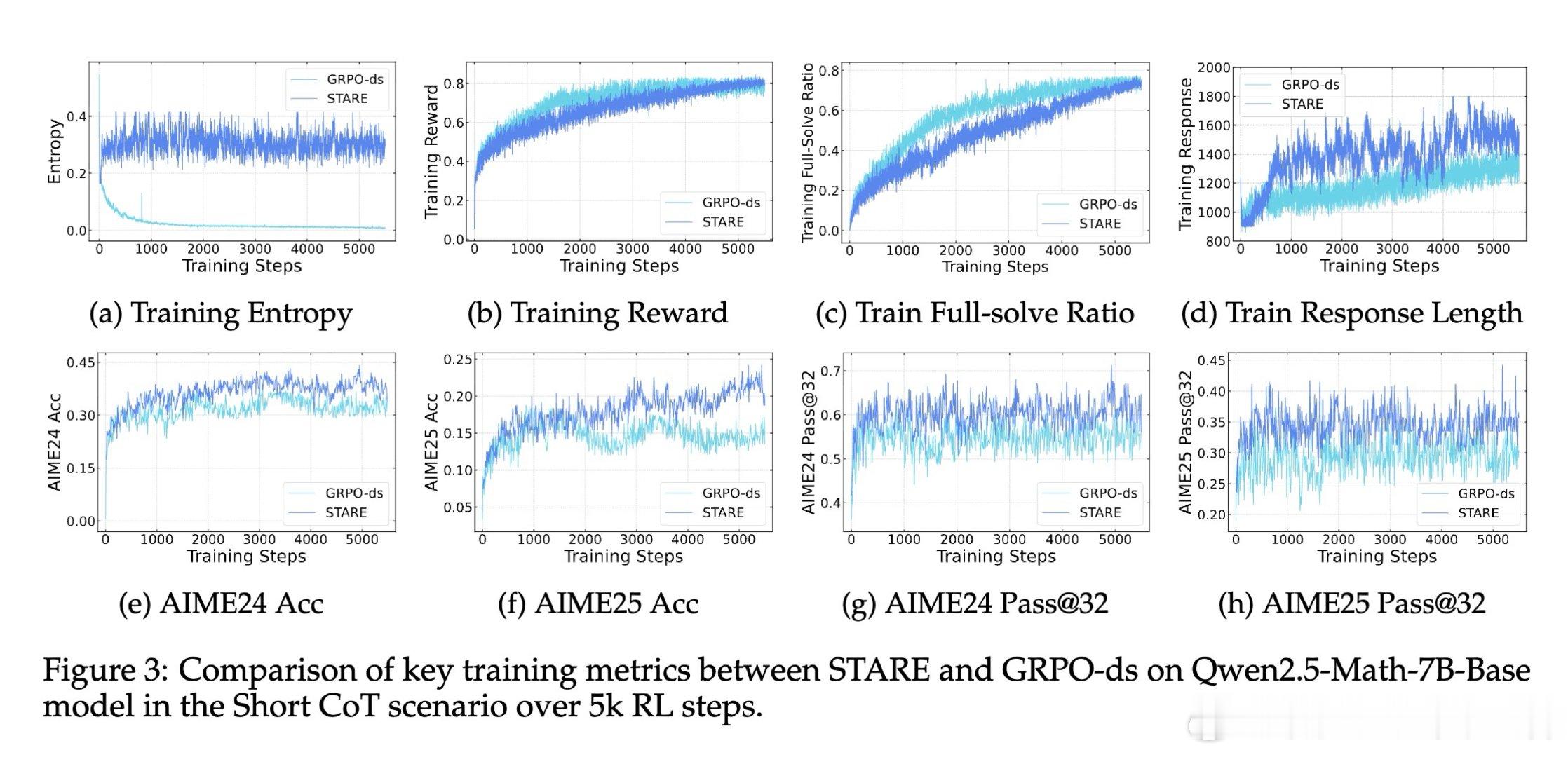
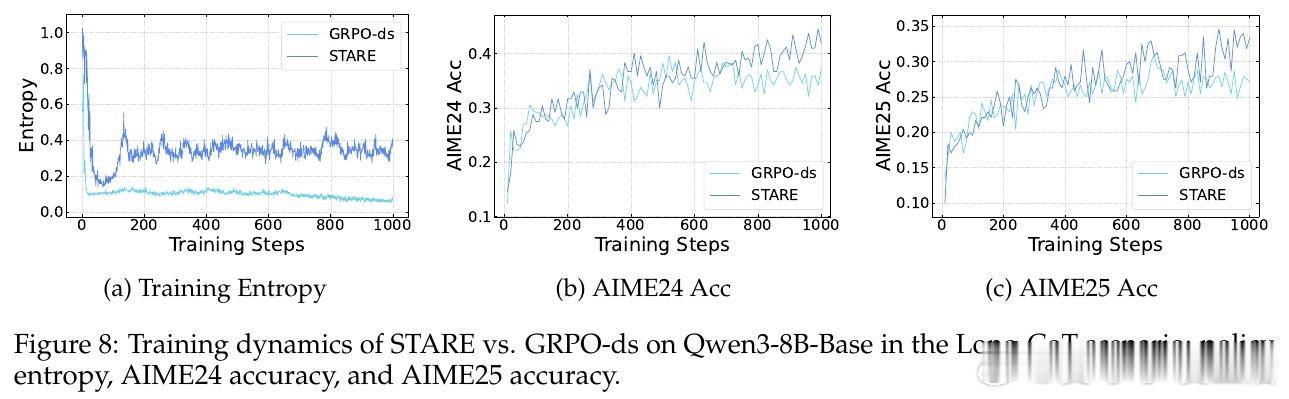
在强化学习后训练(RLVR)领域,策略熵坍塌是一个导致模型过早收敛、丧失探索能力的顽疾。过去的方法如 GRPO 受困于训练数千步后多样性的迅速消失,本质原因是轨迹级的奖励分配忽略了 Token 级的差异,导致高频出现的低信息熵 Token 主导了梯度更新,系统性地扼杀了具有探索价值的罕见 Token。
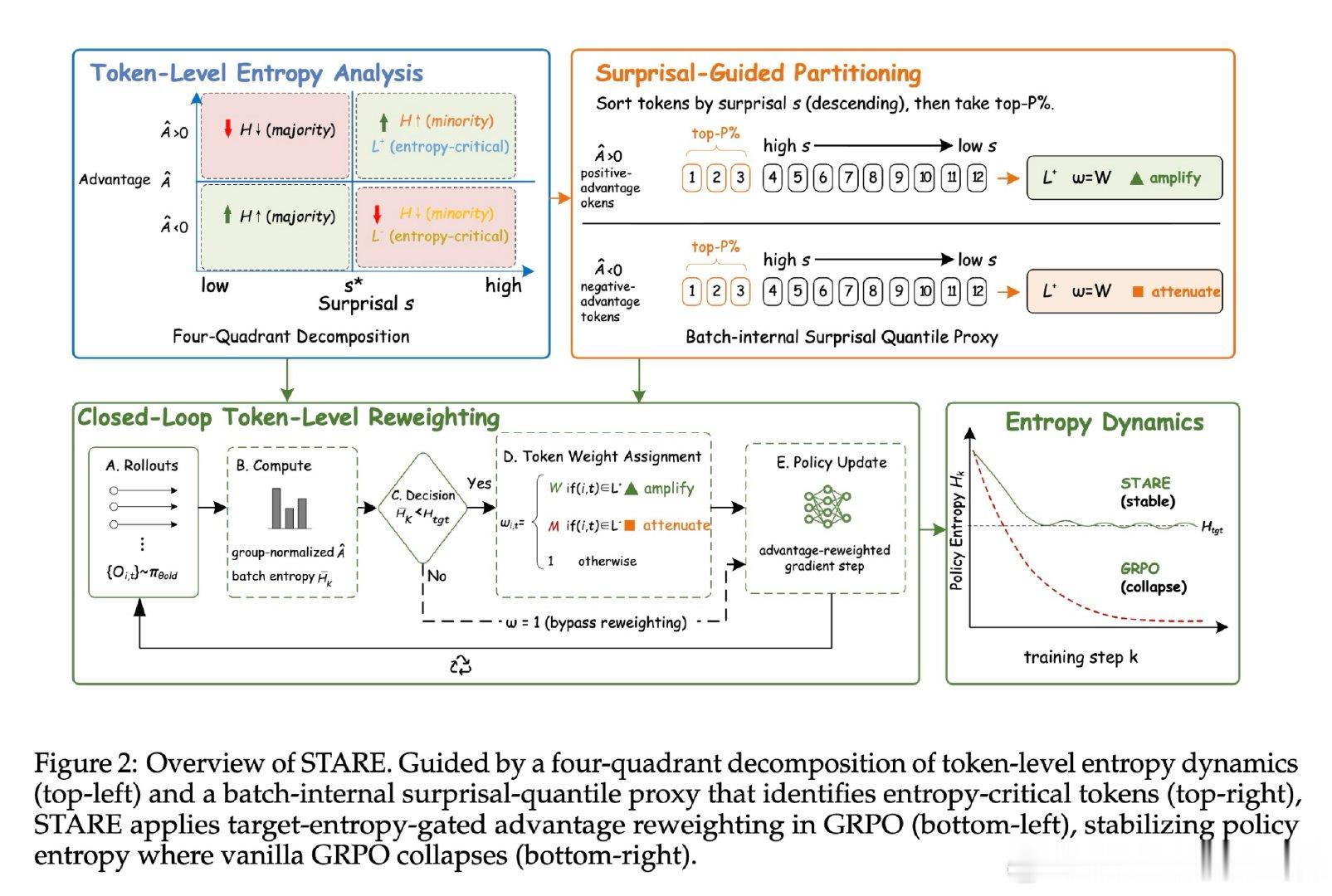
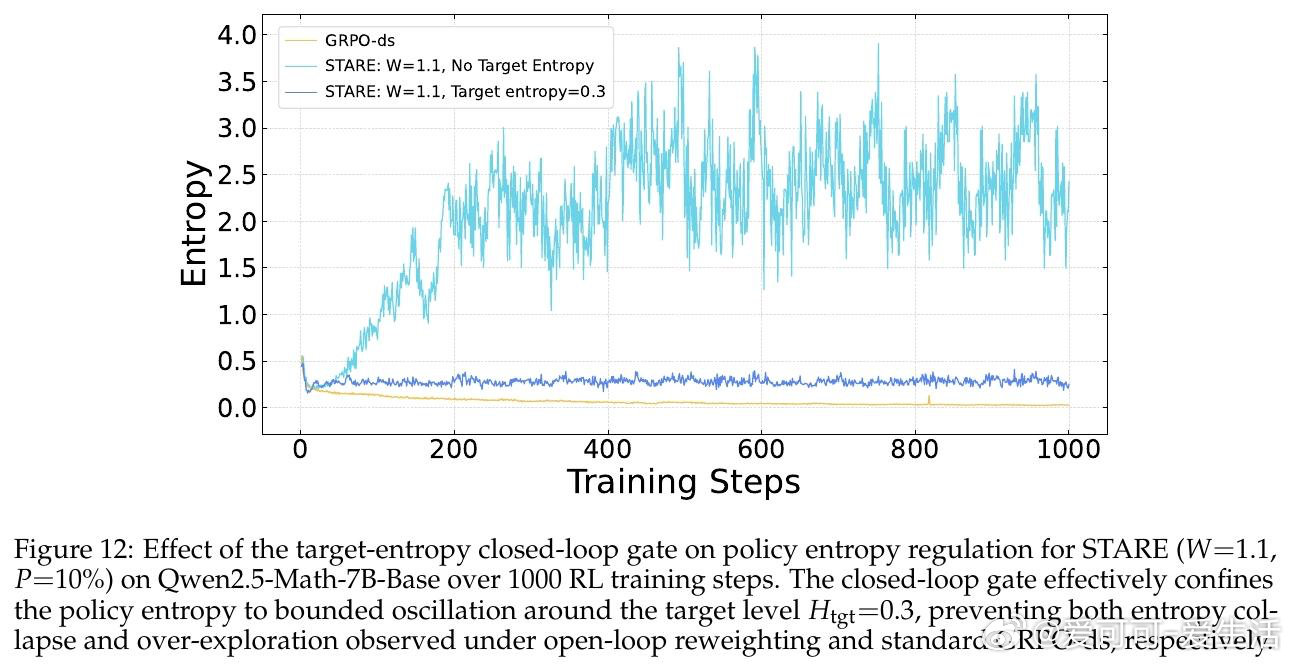
本文的核心洞见是:把策略熵的演化重新看作由“优势值”与“惊奇度”(Surprisal)共同驱动的四象限动力学。由此,STARE 这一关键操作使问题得以解开:它通过批次内的惊奇度分位数识别出对熵增减至关重要的 Token 子集,在不改变梯度方向的前提下,动态放大高惊奇度 Token 的权重并配合目标熵闭环门控,实现了对策略熵的精准稳态调节。
这项工作真正留下的遗产是揭示了 GRPO 熵坍塌的梯度级诱因,并证明了微小的 Token 级信用分配重平衡即可解锁长程 RL 的潜力。它为后来者打开的新门是在不依赖复杂正则项的情况下诱导模型产生自我反思与深度推理行为,但尚未跨过的门槛是这种基于启发式分位数的重平衡在非验证性奖励(如开放式对话)场景下的普适性。
arxiv.org/abs/2606.19236 机器学习 人工智能 论文 AI创造营