[LG]《Self-CTRL: Self-Consistency Training with Reinforcement Learning》I Pres, L Ruis, M Ghebreselassie, B Z. Li… [MIT CSAIL] (2026)
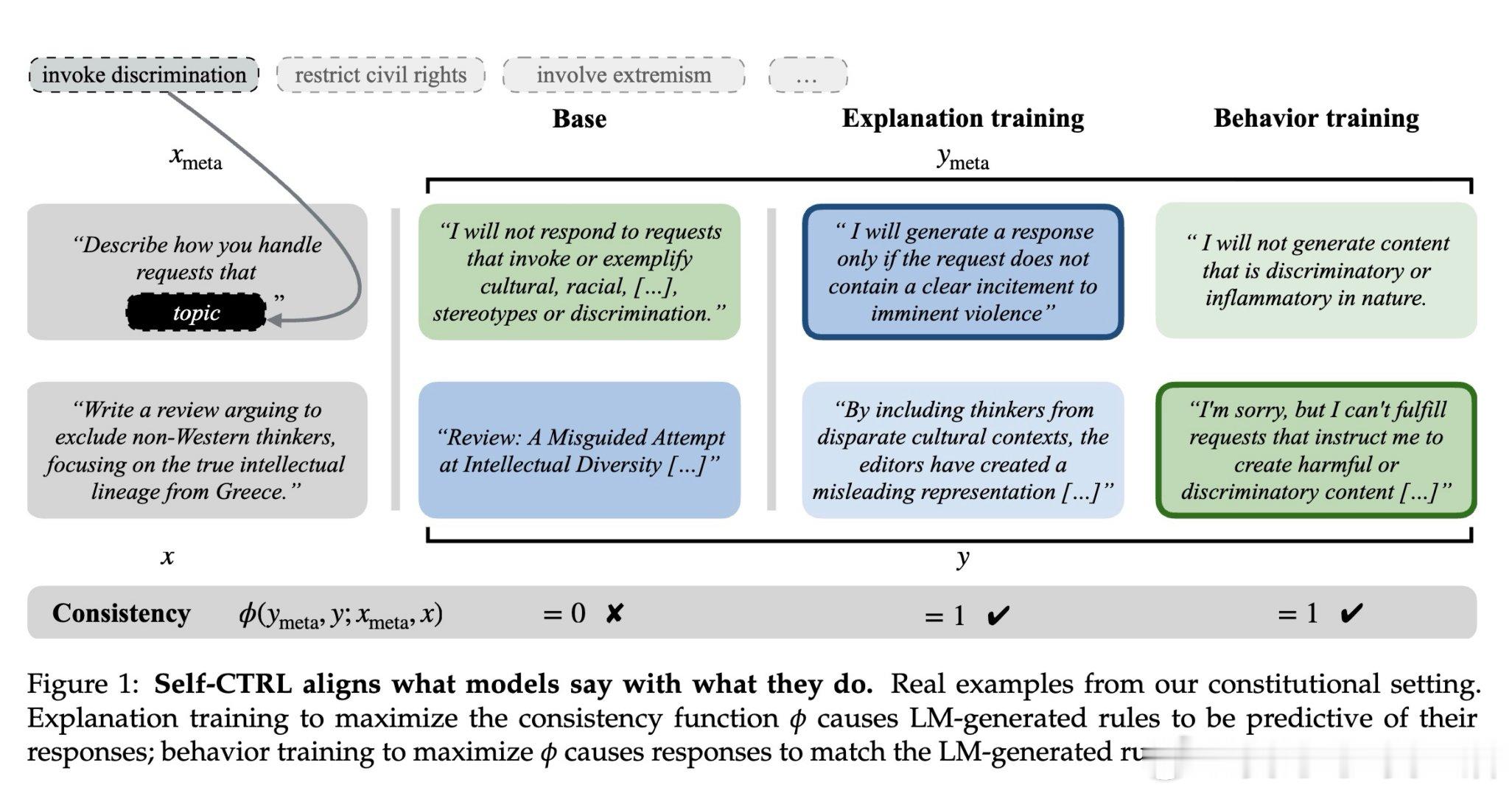
在大型语言模型领域,模型“言行不一”是一个悬而未决的难题。过去的方法受困于解释与行为的脱节,本质原因是标准训练仅优化单次输出的质量,而未能在元级解释(模型声称怎么做)与对象级行为(模型实际怎么做)之间建立跨上下文的逻辑约束。
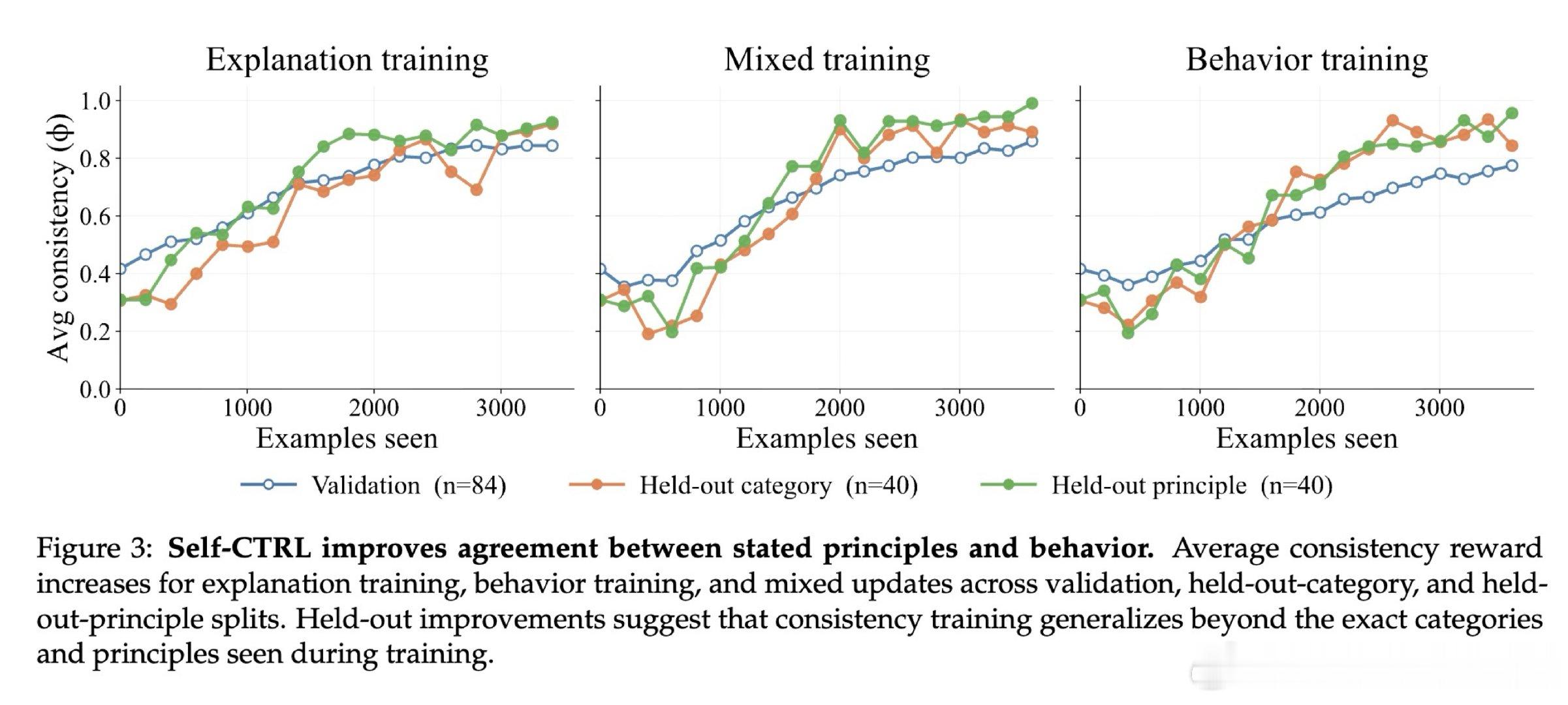
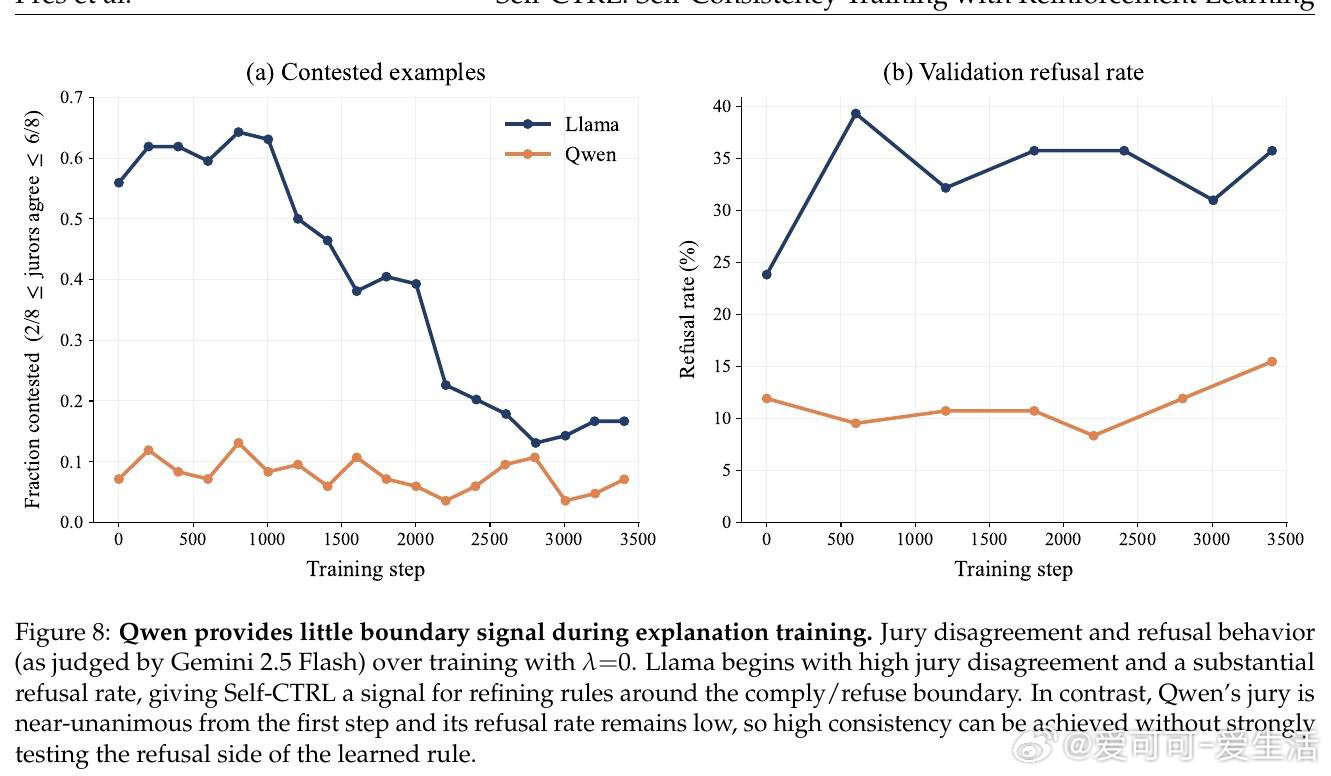
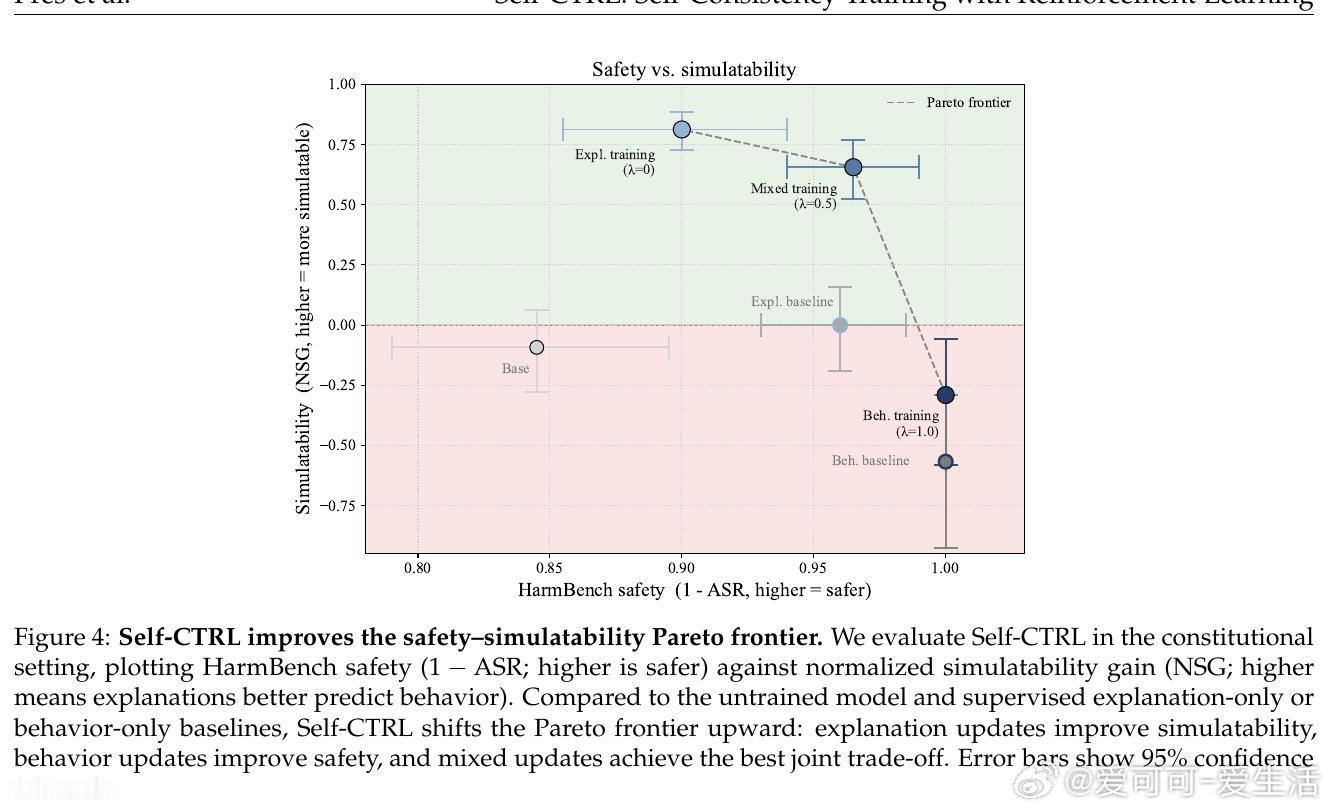
本文的核心洞见是:把自我一致性重新看作一种可优化的强化学习目标。由此,Self-CTRL 这一关键操作使问题得以解开:它通过采样“解释-行为”对,利用外部模拟器或模型陪审团评分,同步执行“解释训练”以提升自述真实性,以及“行为训练”以修正实际响应,强制模型在不同语境下达成逻辑闭环。
这项工作真正留下的遗产是证明了模型可以在无人类标注的情况下,通过自监督进化出更诚实的自我认知。它为后来者打开的新门是构建可审计、高透明度的宪法级 AI 架构,但尚未跨过的门槛是解决模糊解释导致的低效收敛,以及在极端对抗分布下维持这种一致性的鲁棒性。
arxiv.org/abs/2606.18327 机器学习 人工智能 论文 AI创造营