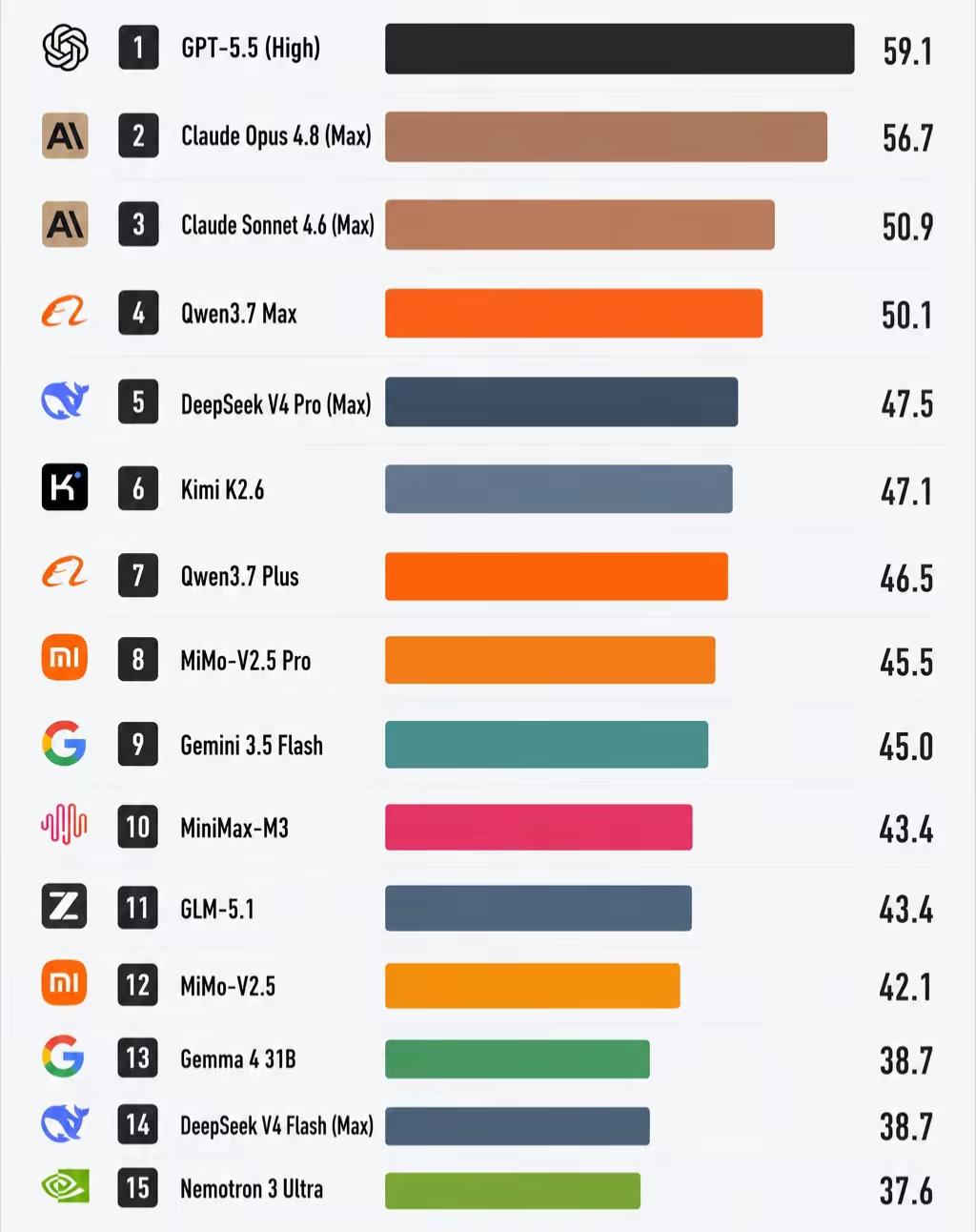
2026大模型综合跑分榜分层解读
榜单为通用推理+代码+长文本综合能力得分,可直接对应Loop工程、Agent开发的选型逻辑,分为四个梯队:
第一梯队|顶级旗舰(50分以上,自治循环首选)
1. GPT-5.5(High):59.1分全场第一,逻辑、多模态、复杂决策能力最强,适合高难度闭环策略设计
2. Claude Opus 4.8(Max):56.7分,长上下文、代码重构、长周期任务收敛能力拉满,是AI自动编程标杆
3. Claude Sonnet 4.6(Max):50.9分,均衡性价比旗舰,日常Agent迭代、项目开发的主力选型
4. Qwen3.7 Max:50.1分国产第一梯队,中文理解、本地私有化适配优势明显,国内企业闭环落地优选
第二梯队|国产主力商用梯队(45~49分,性价比生产主力)
- DeepSeek V4 Pro、Kimi K2.6:代码库解析、百万级长文档处理极强,适配代码审计、知识库型Agent
- Qwen3.7 Plus、MiMo-V2.5 Pro:轻量化高性能版本,适合部署本地子Agent、批量轻量化任务执行
- Gemini 3.5 Flash:谷歌生态联动强,多模态图文链路自动化场景适配好
第三梯队|均衡中端可用梯队(40~44分,轻量化办公Agent)
MiniMax-M3、GLM-5.1、MiMo-V2.5,中文日常交互、文案、轻量流程自动化完全够用,成本更低,适合简单办公工作流。
第四梯队|轻量化开源底座(40分以下,本地私有部署)
Gemma 4 31B、DeepSeek V4 Flash、Nemotron 3 Ultra,主打低成本本地私有化部署,适合搭建离线测试环境、边缘端简易智能体。
Loop工程选型结论
1. 核心顶层决策、长代码重构:GPT-5.5、Claude Opus
2. 国内合规私有化、中文项目闭环:Qwen Max、DeepSeek V4 Pro
3. 批量子Agent、轻量化校验节点:各家Plus/Flash轻量化版本,控制调用成本
4. 纯本地离线闭环:选用开源小模型做执行层,大模型做顶层策略层
ai价值榜 AI模型横评 AI测评体系 AI模型排行榜 AI能力分级 AI全模态模型 AI大模型竞赛