这项研究由 MIT(麻省理工学院) 领衔,联合斯坦福大学(Stanford) 以及 MIT-IBM 沃森人工智能实验室 的顶尖计算语言学与认知科学团队共同打造。
传统的 AI 模仿人类,都是在死记硬背某句特定的话(通过最大化对数概率或匹配文本相似度),结果就是 AI 说话一股洗不掉的“助理味”。
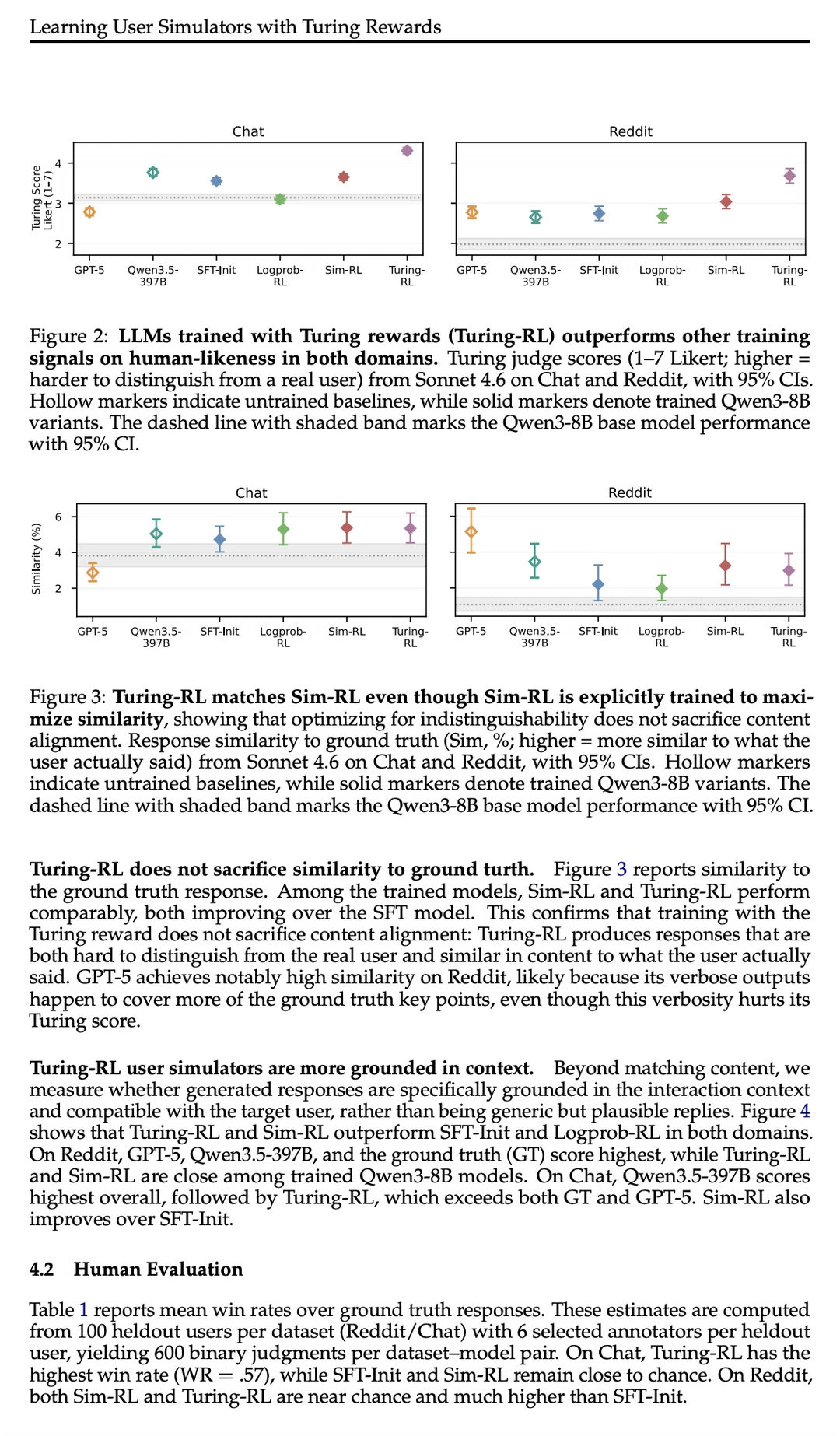
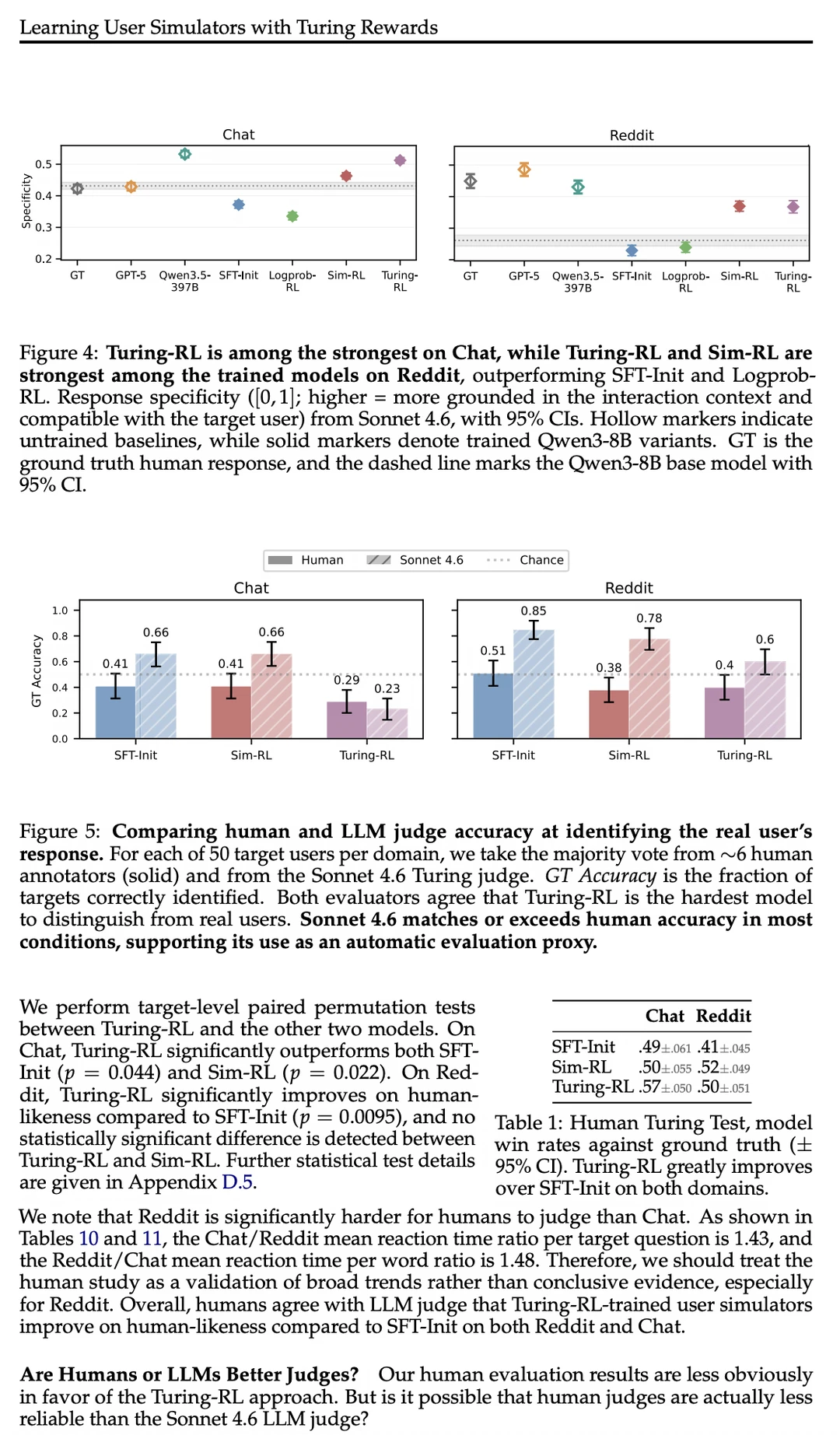
这篇论文提出了 Turing-RL 框架,基于 Turing Test 的 RL 方法,让 LLM Judge 打分生成的回复是否“像真人写的”(给定用户历史)。
用 GRPO 优化后,模型在 Chat 和 Reddit 两大场景中,人类似度全面超越传统 similarity/logprob 基线,同时保持内容相关性。
研究团队在 PRISM(多轮对话) 和 ConvoKit(Reddit 论坛讨论) 两个截然不同的高难度真实社交数据集上进行了严格验证。
LLM 裁判和真实人类的双重评测均显示:Turing-RL 生成的回复更难与真人区分!
它彻底打破了过去“Response Matching(响应匹配)”的僵化路径,证明了以“不可区分性(Indistinguishability)”为优化目标的强化学习,才是通往高拟真人类行为模拟的正确解法。
如果你是 Agent开发、Personalization推荐算法,或是数字人/数字替身领域的从业者,可以Mark这篇工作~(论文可以直接下👇🏻哦)