某座舱负责人:Harness+Model的Agent做不到现场感原作者为群友,是非理想的座舱负责人,以下为群友原文,原标题为Agent就是智能座舱交互的终点吗?
We can only see a short distance ahead, but we can see plenty there that needs to be done.— Alan Turing
序章2025 年底,Tesla 把 Grok Agent 放进车机,能自然地聊天,能理解并执行自然语言表达的复杂出行任务。
2026 年 4 月,北京车展前夕,地平线发布 KaKaClaw 咖咖虾,有记忆、有技能、有性格,还能调度全车舱驾能力,进一步把 Agent 推到"整车Agent操作系统"。
如果说过去十年座舱语音的关键词是"识别率"和"指令成功率",那今年的关键词明显变了:LLM、Agent、情感、人格、记忆、任务编排。
车不再只能听你说"打开空调""音量调大""导航回家",它开始能够理解你随意表达的需求,能猜出你后续可能的需要,能知道你的兴趣喜好,能温柔接纳你的烦恼。
这是一次巨大的进步。
过去的车载语音,本质上是一套规则系统。用户说一句话,系统识别意图,填槽,执行。它很稳定,也很可控,但边界非常硬。换个说法、跨个场景、多问两句,体验就容易掉下去。
引入大模型技术以后,对话管理不再完全依赖预置的状态机,任务可以被动态拆解、规划、调用工具;语音也不再像播报员,开始有语气、有停顿、有情绪。智能座舱终于从"命令执行器",往"有真人感的车内助手"靠近了一步。
无论是 KaKaClaw,还是正在上车的一大波 Agent 们,智商和情商都有了很大提升。
分合但这并不意味着传统系统会被一夜替换。
车载场景对延迟、成本和可控性极度敏感。低延迟链路、无网时本地链路、可见即可说、免唤醒指令、垂域逻辑,这些能力很多仍然会被保留。这也是当前 Agent 在车端落地的最大难点:新架构性感强大,旧链路似乎也必要,两套系统该如何共存。
有的做多个语音入口,有的通过设置切换,有的做分发缝合,却没人敢直接抛弃旧有的系统。
随着模型能力的提升、芯片成本的下降、推理技术的优化,成本、延迟和可控性都会逐步解决,Agent 的覆盖面会一点点扩大,最终走向更统一的架构。这是大概率会发生的演进,但具体是哪一天,恐怕没人敢预测,我们常常高估一年后的进展,也常常低估五年后的变化。
暗涌即便那一天到来,问题仍然没有彻底解决。
因为这套 Agent 的底层,仍然沿用着一套旧式的交互假设。
一个用户,对着机器,说完一句话;机器拿到一段文本,理解,思考,回答。
这就是我们常说的 turn-based。但它不只是"轮流说话"这么简单。它背后默认了许多假设:这句话是对机器说的;用户已经说完了;文本本身足够表达意图;环境信息可以事后再补。
这套结构适合微信、ChatGPT 这类聊天界面。当你按下发送键,就等于告诉系统:这是给你的,我说完了,请回答。它也适合很多车控任务,比如"打开空调""导航回家""音量调大"。
但真正的自然语音交互不是这样。
用户说到一半停下来,不一定是说完了,也可能是在组织语言。后排说了一句"这个太冷了",不一定是在和车说话,也可能是在阻止小朋友吃冰箱里的冰激凌。用户询问环境信息时,当一句话说完,环境状态可能已经改变了。
我们在和人对话时,还会用停顿、眼神、手势、语气来不断确认彼此是否理解。
而当车内交互被简化成了一段"已经说完、已经指向机器、已经足够表达意图"的文本,这在模型上更好处理,产品也更好控制;但被牺牲掉的停顿、指向、说话对象、视觉现场、车内状态,恰恰是车内交互最关键的现场感。
尽头最近很流行一个说法:Agent = Harness + Model。
Model 能力不够,Harness 来凑。
聪明的工程师们,引入语义判停,音区锁定,拒识别模块,视觉信息融合,时间戳对齐,然而问题却没有被完美解决。
以最常见的判停为例:阈值短了总是截断用户,阈值长了延迟太多,加语义判断要引入一个多大的模型才能真正准确?
这不是某个模块的精度问题,是整个范式的问题。turn-based 假设了一个清晰的"输入-处理-输出"边界,但真实的交互没有这个边界。在边界不清晰的世界里缝合再多模块,缝出来的也只是一个更精致的 turn-based。
归元那么,能不能从 Model 层解决?
这正是当下许多顶尖的 AI 实验室正在关注的方向。从 Google 的 Gemini Live 到阿里的 Qwen Omni、字节的 Seed Duplex,都在试图把"实时交互"放进模型本身,让模型直接完成边听-边想-边说,而不是放在外层的 Harness 里。
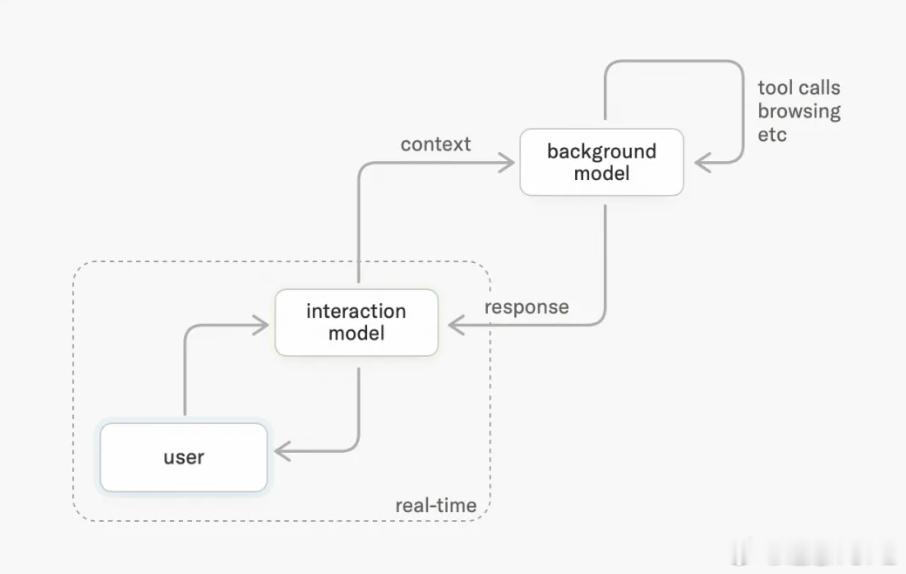
最近,前 OpenAI CTO Mira Murati 创立的 Thinking Machines 也提出了 interaction model。这个模型重新设计了交互模型的时间结构,它处理的是连续发生的现场信息,声音、画面、文本、工具调用都在同一条时间轴上。它不等用户说完,而是在很小的时间片里(200ms)持续判断:用户还在想吗?现在该回应吗?视觉里发生了什么?后台任务到哪一步了需要告知用户吗?
Thinking Machines 的系统是一套前后台的架构,前台进行交互对话,后台提供任务调用的能力。
图1
前台是 interaction model。它本身必须足够聪明,能在实时交互里判断用户是不是在和车说话,停顿是不是意味着说完,打断是不是需要立刻停止,屏幕上的信息是否和用户当前意图有关。
Thinking Machines 在文中专门强调:
Both the background and interaction models are intelligent — on its own, the interaction model is also competitive on both interactive and intelligence benchmarks.也就是说,前台模型和后台模型不是"浅智能"和"深智能"的区别,而是智能发生在不同时间尺度上。
前台负责的是当下这一秒——会听、会等、会停、会接话、会处理打断,也要知道什么时候闭嘴。
后台是 Agent 模型。它负责更长链路的任务,比如查路线、读车辆手册、调用生活服务、规划行程、协调多个工具。它可以慢一点,但要想得更深,做得更完整。
在这种架构下,座舱交互才有可能真正具备现场感。
未竟当前座舱行业的热点是 Agent,但未来智能化真正的分水岭,不只是 Agent。
大语音模型带来的自然语调、大语言模型带来的复杂任务执行能力,都将变得不稀奇。真正稀缺的,是 Model 层引入的新交互能力,它有可能带来下一个奇点。
未来座舱 AI 的竞争,可能会从"谁更聪明",变成"谁更懂互动"。
最好的智能座舱,是一辆能和你保持同一节奏交流的车。
车里许多声音重叠,它能判断谁在和车说话;你边看屏幕边问"这个怎么关上",它知道你指的是什么。你在倾诉烦恼时停顿下来,它只是轻轻说一声"嗯,我在听呢",而不是急着告诉你什么是正确答案。
李想理想汽车