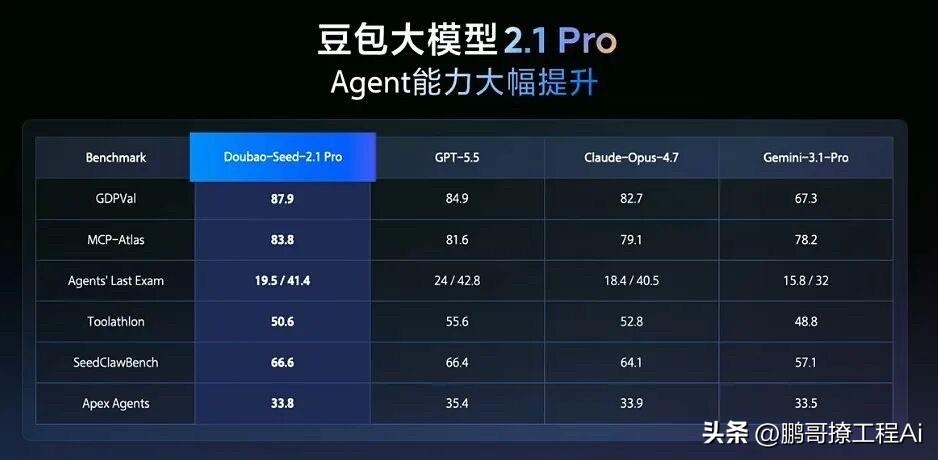
豆包新模型推出来了!真的没必要再迷信那几家了。 很多人还在讨论GPT和Claude谁更强,回头一看,豆包已经带着2.1 Pro杀到了桌子中央。 这张对比图我看得挺感慨的。什么概念呢?就是在GDPVal这块最难啃的骨头上,豆包直接干到了87.9,把GPT-5.5和Claude-Opus全按在身后。这不是那种“咬得很紧”的焦灼局,这是彻底拉开了断层的碾压。
在Agent能力相关的核心评测里,豆包2.1 Pro的策略很明显:不追求每个单项的虚名,但在MCP-Atla 和 sSeedClawBench这种极其考验模型底层调用和长链操作的地方,它全是第一。这种“硬核实力”不打折扣,高分都是实打实往关键部位打。
更有意思的是Agents' Last Exam这项,看似GPT略高,但仔细看逻辑,豆包完全是在用另一种非对称的路径死磕上了牌桌。