百度新OCR偷偷上线,这是把DeepSeek的魂给接过来了?
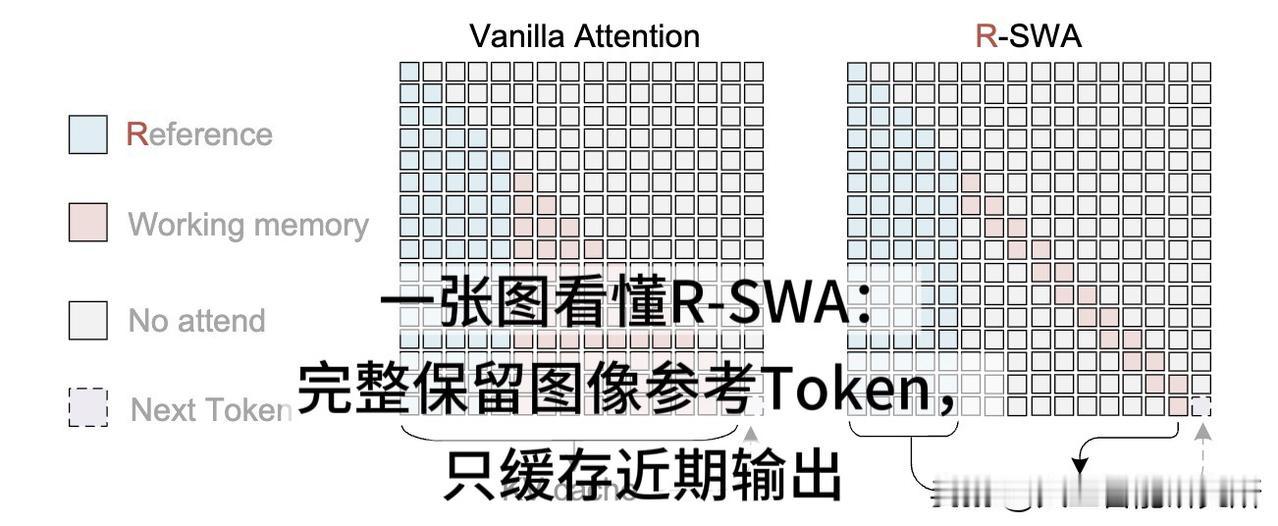
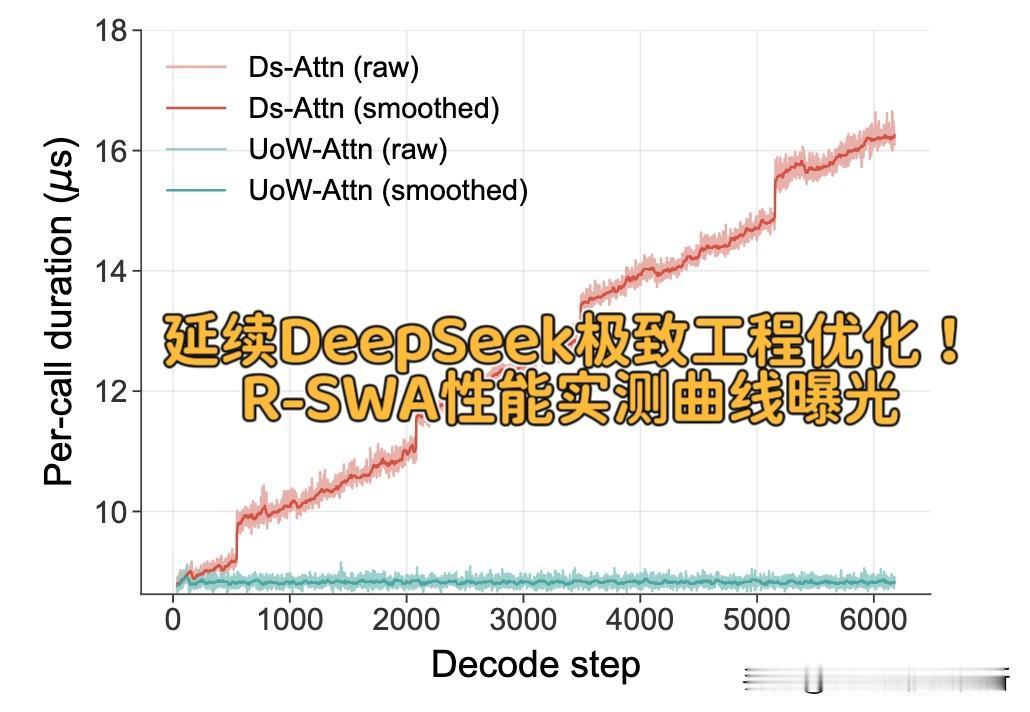
Unlimited OCR刚出来的时候,大家都在讨论技术——一次前向推理转录几十页文档,KV Cache全程恒定,32K上下文直接搞定长程解析。这套R-SWA机制的灵感来自人类抄书时的“软遗忘”,思路确实清奇。
但我翻完技术报告,越看越觉得不对劲。
先说作者名单。三位核心贡献者,两人挂真名,唯独技术总监那一栏写着“YY”。大厂发技术报告,核心负责人用缩写,这操作几乎没见过。YY是谁?圈里已经开始猜了。
再说技术路线。DeepEncoder最初是在DeepSeek OCR里被引入的,这次Unlimited OCR完美融合了这套高压缩率编码器。GitHub致谢栏更是直接把DeepSeek-OCR和DeepSeek-OCR-2排在前两位——这不像是在致敬竞品,倒像是在引用自己的过往工作。
最让人在意的是行文风格。这篇报告叙事逻辑太眼熟了:先分析人类怎么做长程任务,再提炼机制,最后落地模型。不堆参数、不卷榜单、故事性极强——这完全是DeepSeek那套技术报告的“舒适区”。
去年DeepSeek-V4那篇58页报告里,有10个名字旁边标了星号,表示已离职。不到半年走了五个人。圈内一直有人在问:这些人去了哪?
OCR圈就这么大。能做出R-SWA这种级别突破、同时对DeepSeek架构熟到能随手改进的团队,凑出一支来并不容易。
YY是谁,报告没明说。但致谢顺序、技术路线、文风调性把指向画得很清楚了。这大概就是百度的技术报告里,留给圈内最大的一个开放式谜题。
百度 文心 文心大模型 DeepSeek OCR ai AI大模型 科技 AI技术