我身边很多搞开发的朋友对模型能力一直有个默认排序:天花板主要看Anthropic和OpenAI,这在过去一年多里基本没被挑战过。
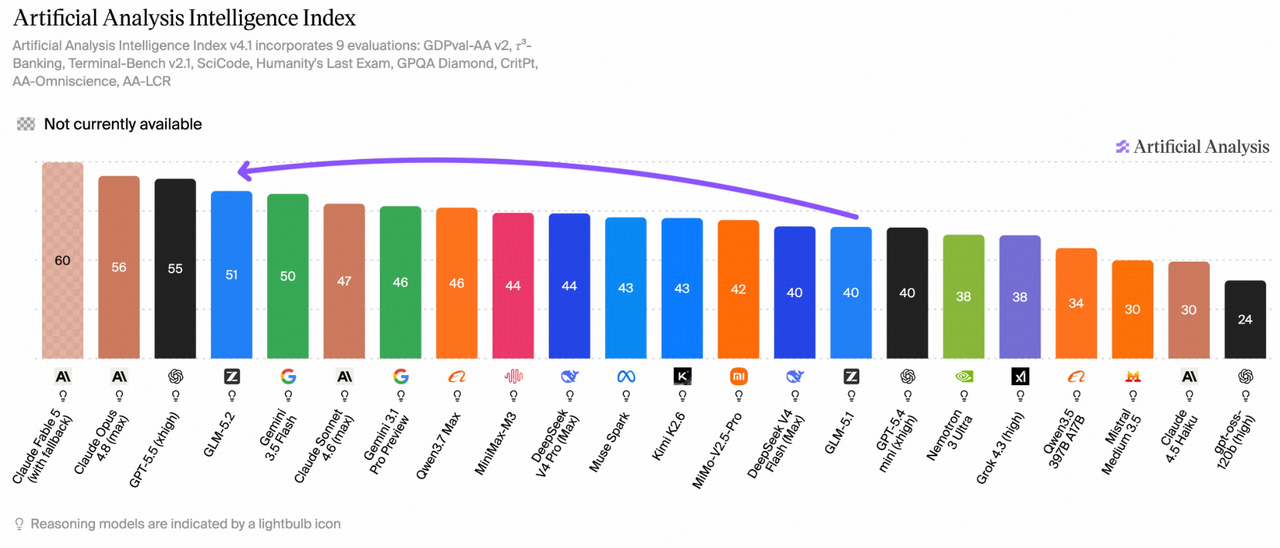
但最近Artificial Analysis的综合评测榜单出了一个新结果,让不少人开始重新排座次。
智谱6月17号发的GLM-5.2,开源的,MIT协议,在这个榜单上拿了51分,开源模型里最高。
更值得注意的是整个榜单的格局:Anthropic、OpenAI、智谱,三家拉开了跟后面选手的身位,海外媒体开始用御三家来形容这个组合。
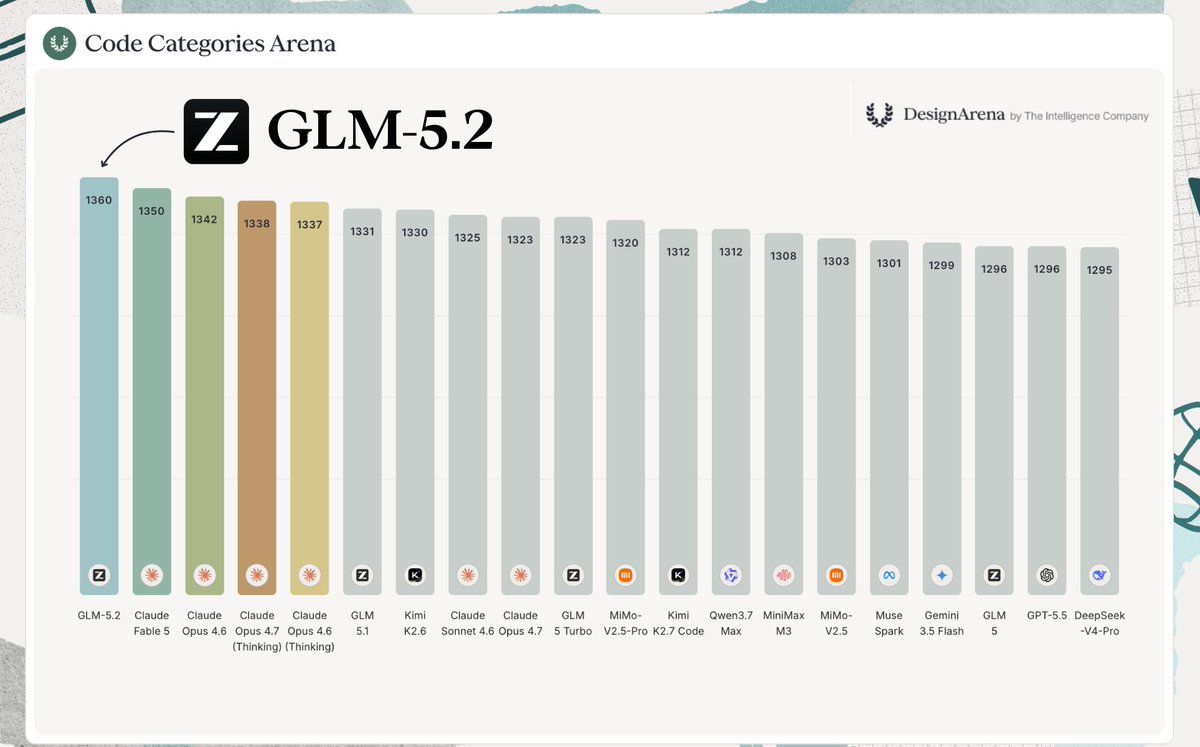
在Code Arena超百万用户盲测里,GLM-5.2直接在全球可用模型排行摘冠。
但跑分归跑分,GLM-5.2这次主打1M长上下文加长程任务不掉线,所以我关心的只有一个问题:这次是真能用还是纸面数字?
我设计了两轮实测,咱们一起来看一下👇
第一轮:一句话需求到可运行应用。
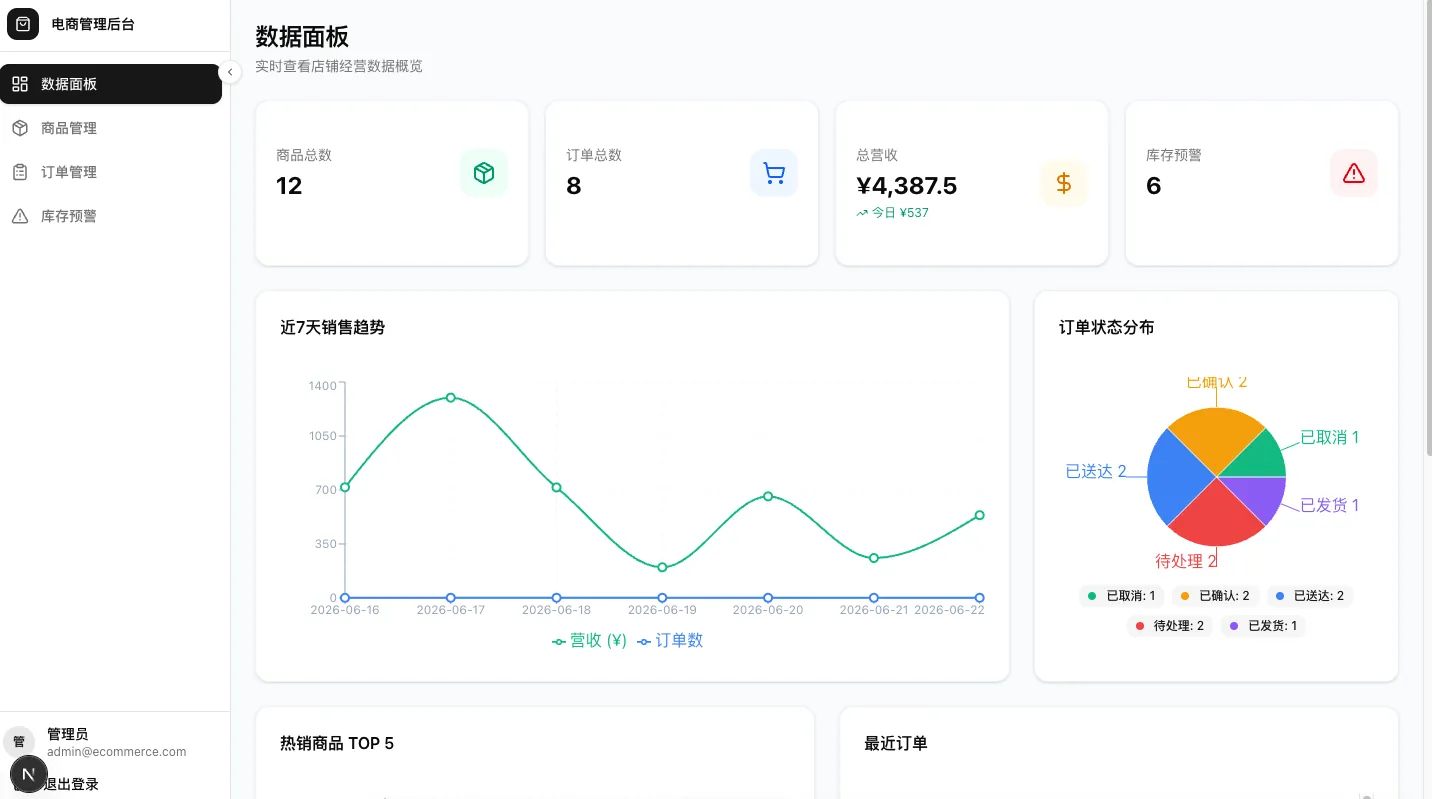
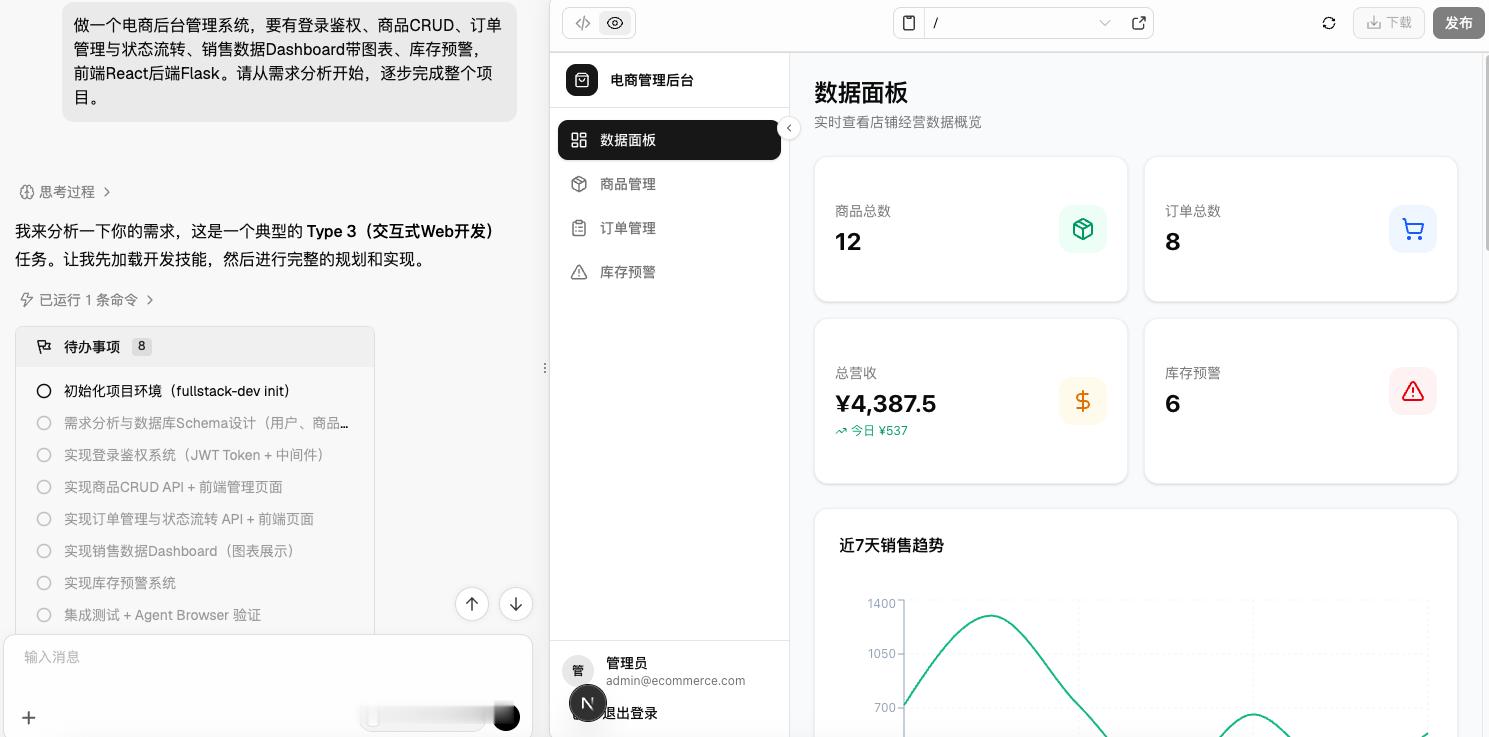
需求:做一个电商后台管理系统,要有登录鉴权、商品CRUD、订单状态流转、销售Dashboard图表、库存预警,前端React后端Flask。
全程不介入。
它先完成需求拆解、五张表的数据库设计和API定义,然后写前端,分页参数、筛选字段、响应体结构跟后端接口完全对得上,最后做库存预警,准确复用了第10分钟定义的min_stock字段,没造新名。
看了一下,项目能跑,登录、商品管理、下单流程、图表渲染、库存预警均正常。
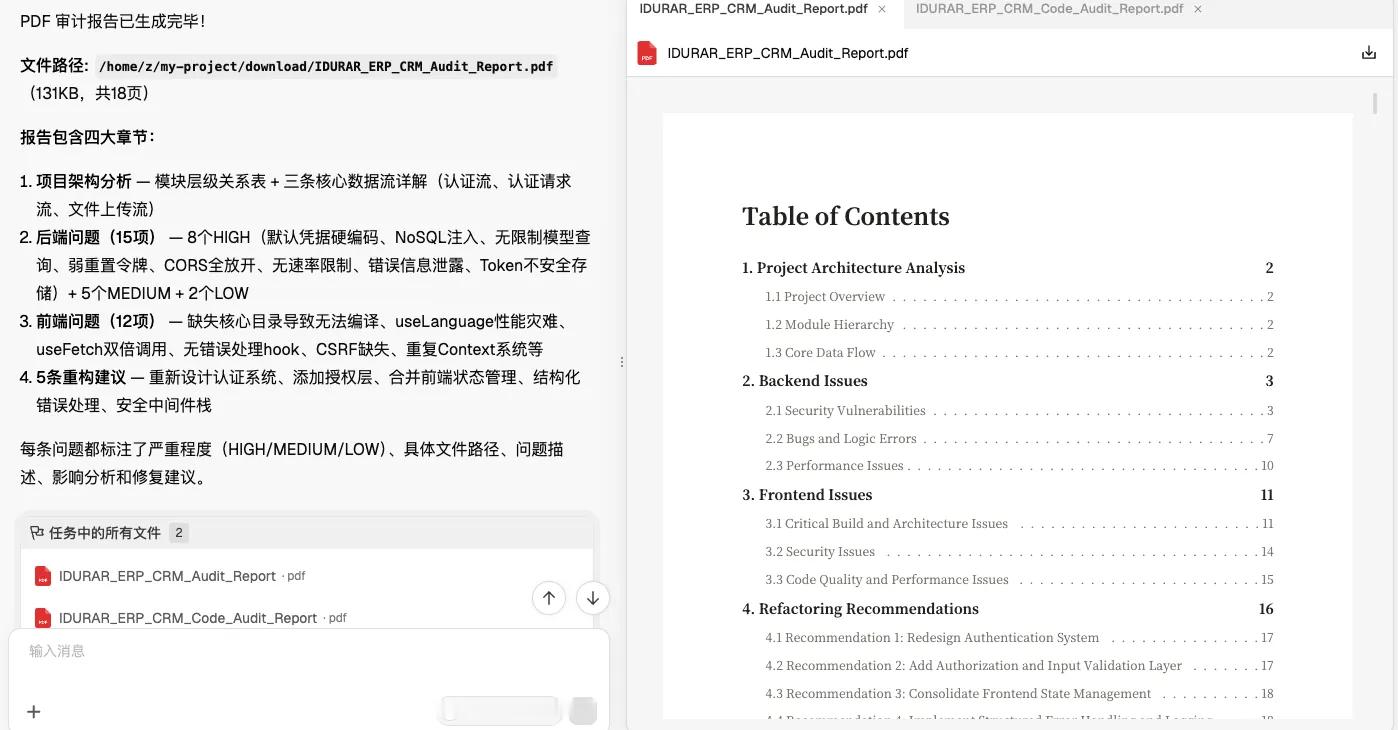
第二轮:整库代码审计。
我把一个真实的开源项目整个喂进去做代码审计,这个项目是一个基于 MERN 栈(Node.js + Express.js + MongoDB + React.js)的开源 ERP/CRM 系统,覆盖发票、库存、会计、HR 四大模块。
可以看到,最后给出的报告非常详细。
报告包含四大章节:
项目架构分析 — 模块层级关系表 + 三条核心数据流详解(认证流、认证请求流、文件上传流)
后端问题(15项) — 8个HIGH(默认凭据硬编码、NoSQL注入、无限制模型查询、弱重置令牌、CORS全放开、无速率限制、错误信息泄露、Token不安全存储)+ 5个MEDIUM + 2个LOW
前端问题(12项) — 缺失核心目录导致无法编译、useLanguage性能灾难、useFetch双倍调用、无错误处理hook、CSRF缺失、重复Context系统等
5条重构建议 — 重新设计认证系统、添加授权层、合并前端状态管理、结构化错误处理、安全中间件栈
测完,我简单总结一下。
记忆力:80万token内可靠,开源第一梯队。
持久力:42分钟长任务前后一致不失忆。
理解力:跨文件推理表现不错,准确率64%,幻觉仍存在。
海外开发者的对比实测体感大概介于Claude Opus 4.7到4.8之间,跟最强的Opus 4.8差距收窄到1%到4%。考虑到这是MIT开源模型,这个水位相当有竞争力。
另外GLM-5.2的Coding Plan已经全量开放,包括Lite版本,不用付费就能体验。
过去一年大家关注的都是模型有多聪明,能解多难的题,但实际工程里真正卡脖子的是工作记忆。
你让一个天才程序员干活,每半小时清空一次记忆,他也干不了大项目。
GLM-5.2解决的就是这个问题,记得住事、扛得住长任务、能通盘理解大工程。
在实际开发场景里,这些能力的优先级比跑分高得多。