但这篇来自 Mila 实验室、康奈尔大学等机构的最新论文发现:这种“均匀堆叠”其实浪费了潜力。
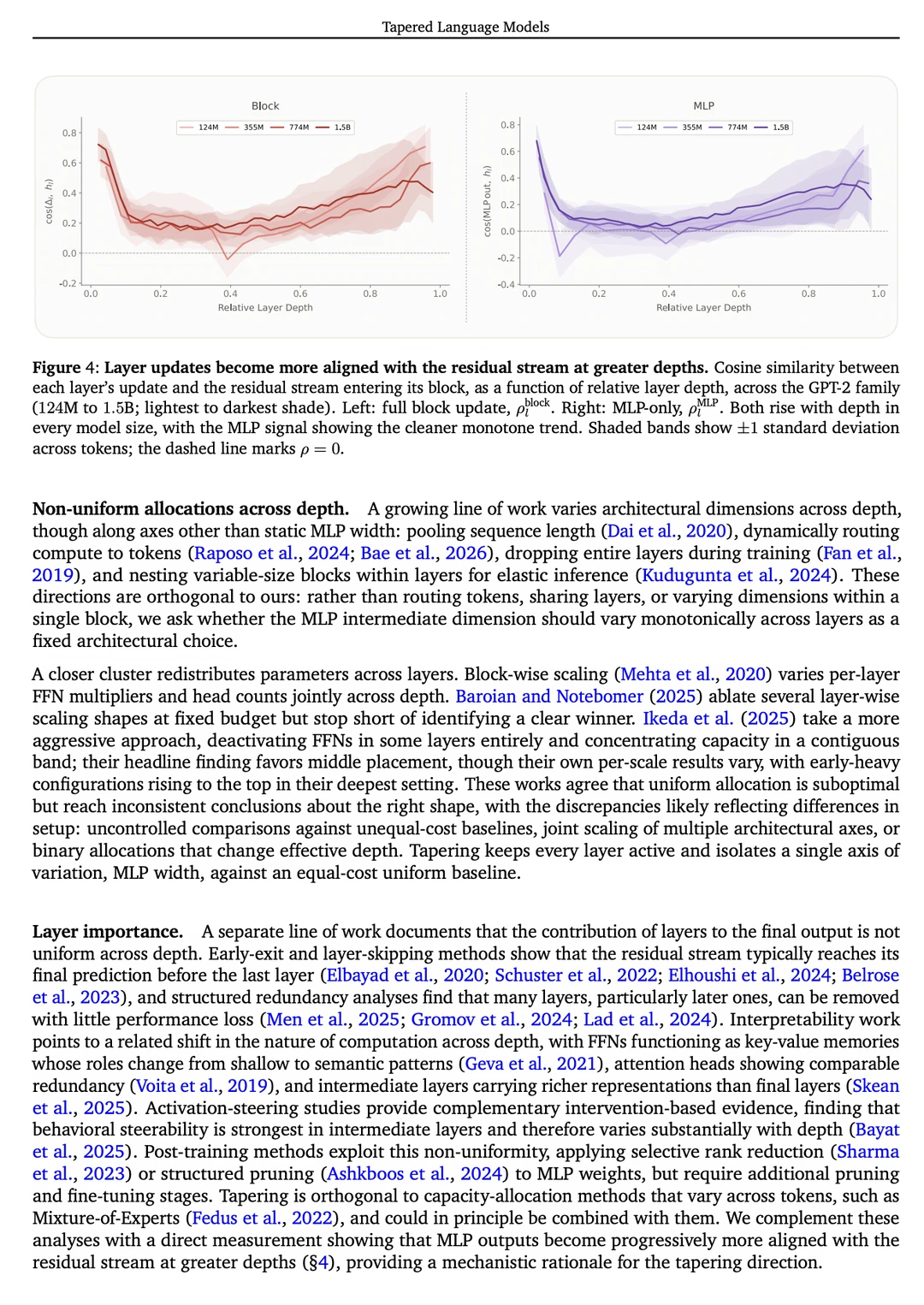
研究人员做了一个非常巧妙的机制分析。他们去测量模型每一层的输出和进入该层的原始信号(残差流)之间的夹角(余弦相似度)。
结果发现了一个惊人的物理规律:随着层数的加深,层输出和残差流越来越趋于同向。
这暴露出一个巨大的资源浪费:高层既然不需要高强度的特征创新,却占用了和底层一模一样多的参数量。
既然知道了“底层缺资源,高层在划水”,那直接把高层的参数抽出来,挪给底层用不就行了?
这就是论文提出的 渐变式语言模型(Tapered Language Models,简称 TLM) 核心思想。
这是一个极其优雅的方案。
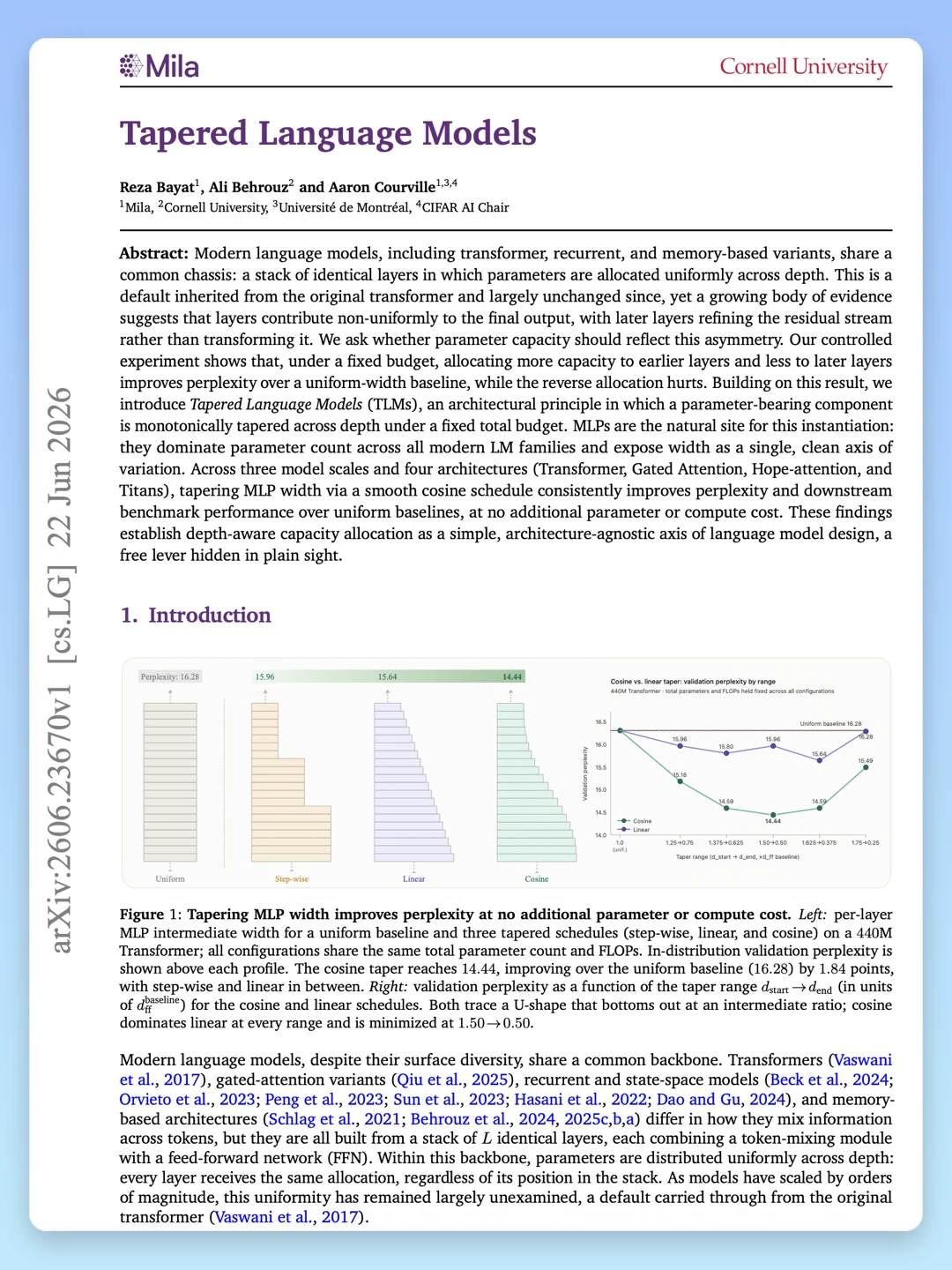
他们在总参数量不变、训练/推理算力(FLOPs)完全锁定的前提下,让 MLP 的中间层宽度随着深度增加而单调递减。
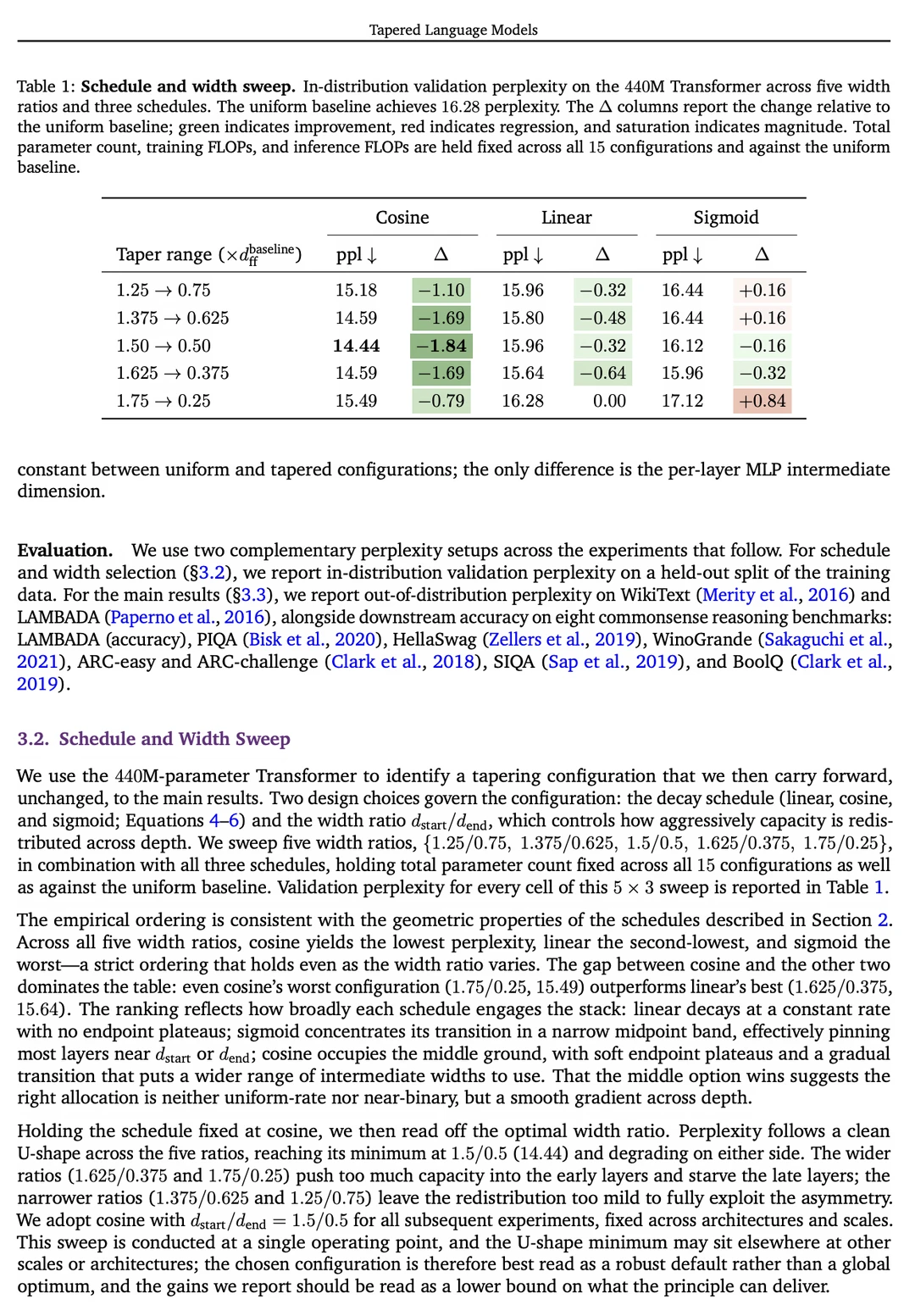
经过对“线性渐变”、“Sigmoid 渐变”和“余弦渐变”的对比测试,发现余弦渐变(Cosine Taper)效果最好。它就像一个平滑的漏斗:最底层的宽度放大到原来的 1.5 倍,最顶层缩减到原来的 0.5 倍,中间层平滑过渡。
实验结果非常暴力,在 440M、760M、1.3B 等不同参数规模下,TLM 在 WikiText 困惑度(Perplexity)以及 8 项常识推理任务、长文本“大海捞针”(NIAH)测试中,全面、无例外地击败了传统的均等大模型。
最性感的点在于:它不花一分钱。
把参数聪明地往前放,模型就能用同样资源学得更好、更高效。这是一种简单却被长期忽略的设计杠杆,值得更多模型尝试。
觉得有意思的,想详读论文的可以直接download👇🏻~ 给大家上传好了~ 拿走不谢(点个赞吧)