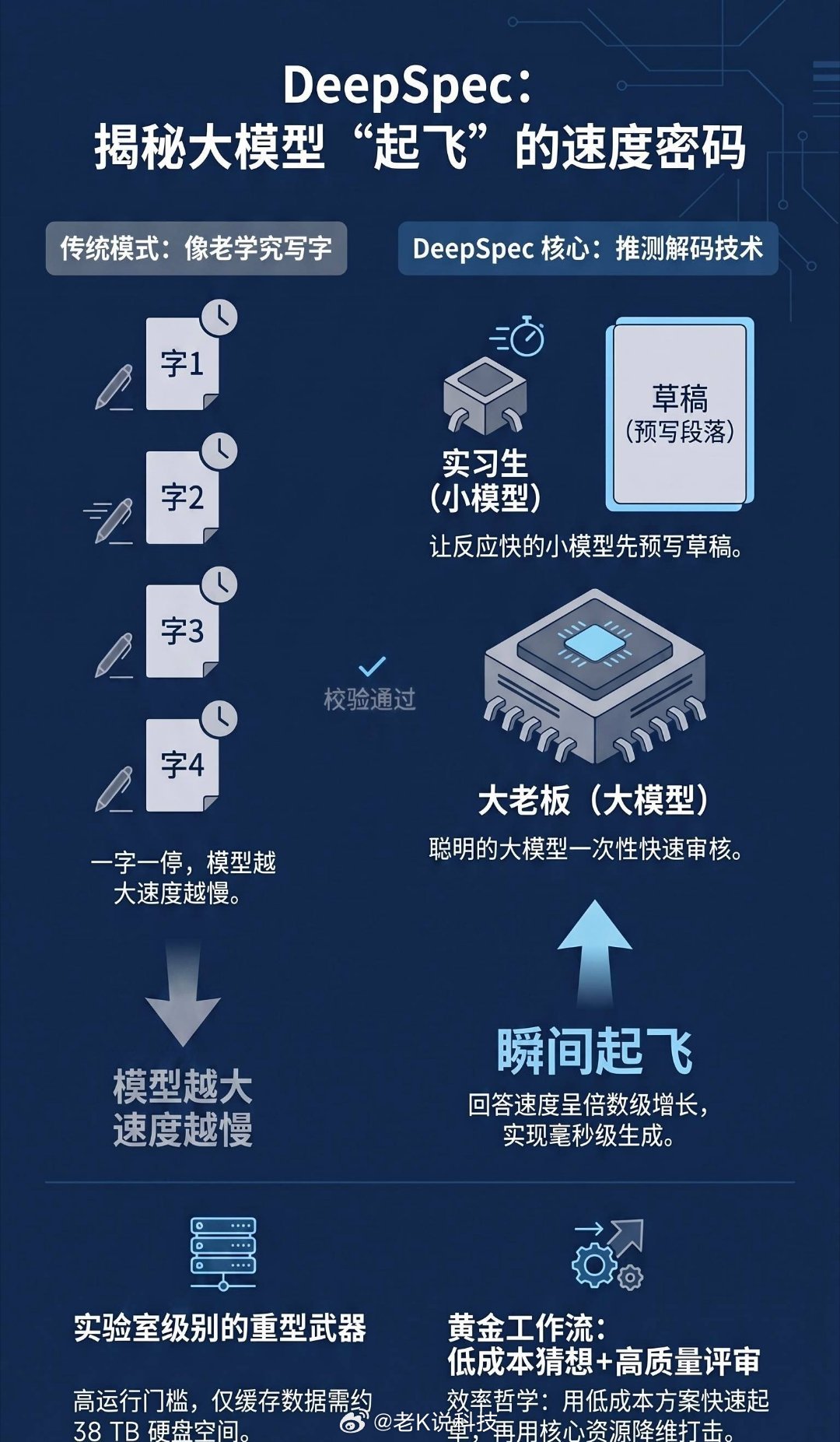
DeepSeek发布DSpark 聊聊DSpark这个新开源工具:大家平时用AI觉得回复卡顿,本质是生成每个字都要完整跑一遍模型,显卡大半资源都闲置了
而DSpark的逻辑很好理解:先预判一段文字,机器自己判断这段内容靠不靠谱,靠谱就直接过,存疑再重新核验,不用重复运算。
这样速度就会明显提升,最高能翻四倍,日常使用也能明显缩短等待时间。
重点是公开了代码就不限模型,不管你跑通义还是Gemma都能用,谁都能拿去二次调整。
看得出来Deepseek再一味追求纸面跑分,开始深耕落地阶段的成本和效率了