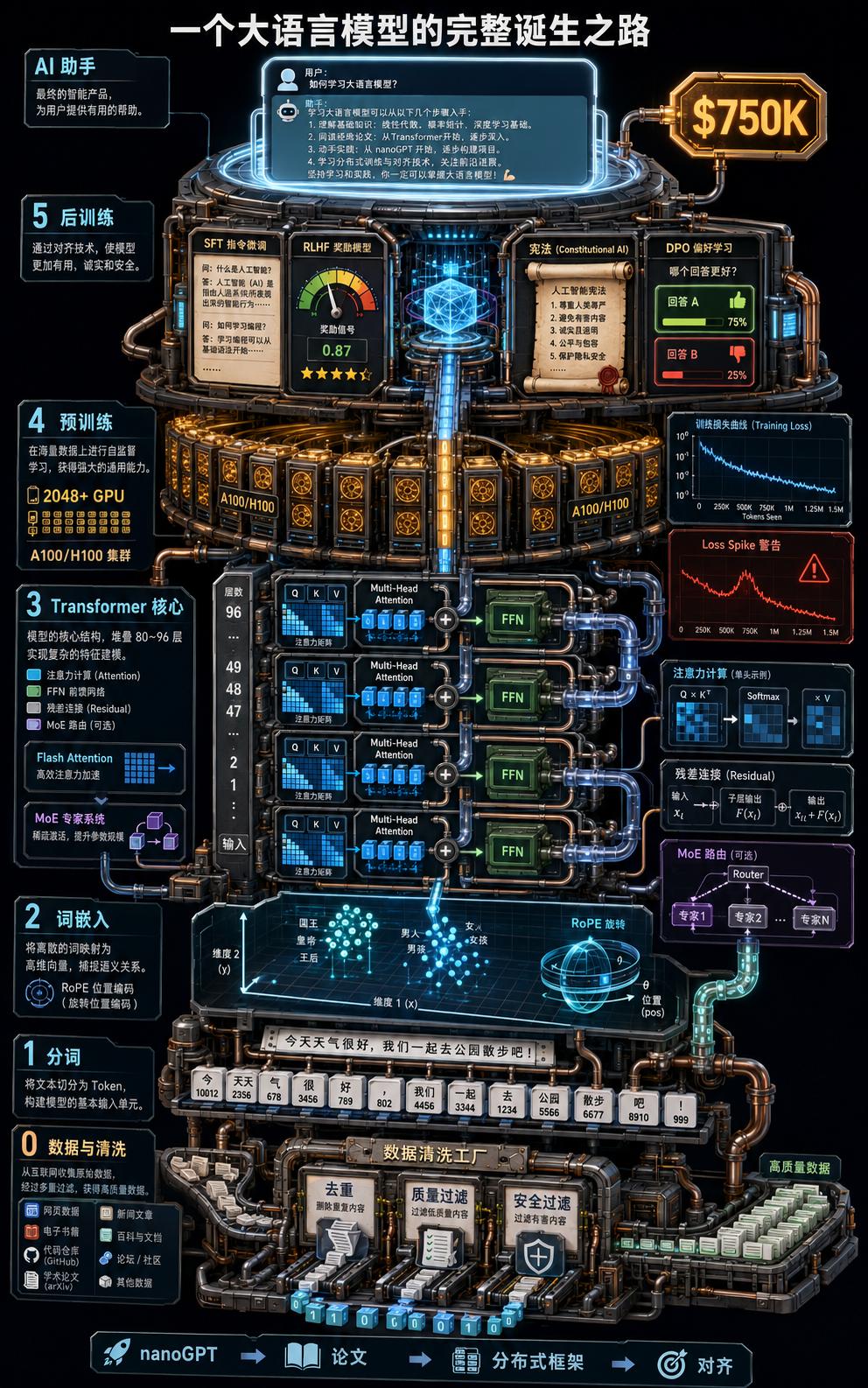
Anthropic 开出 75 万美元年薪招"能从零构建大语言模型架构"的工程师,这不是又一条硅谷高薪新闻。当你把这个数字和 Levels.fyi 上 56-89 万美元的总包数据放在一起看,真正的问题就变成了:什么样的能力配得上这个价?
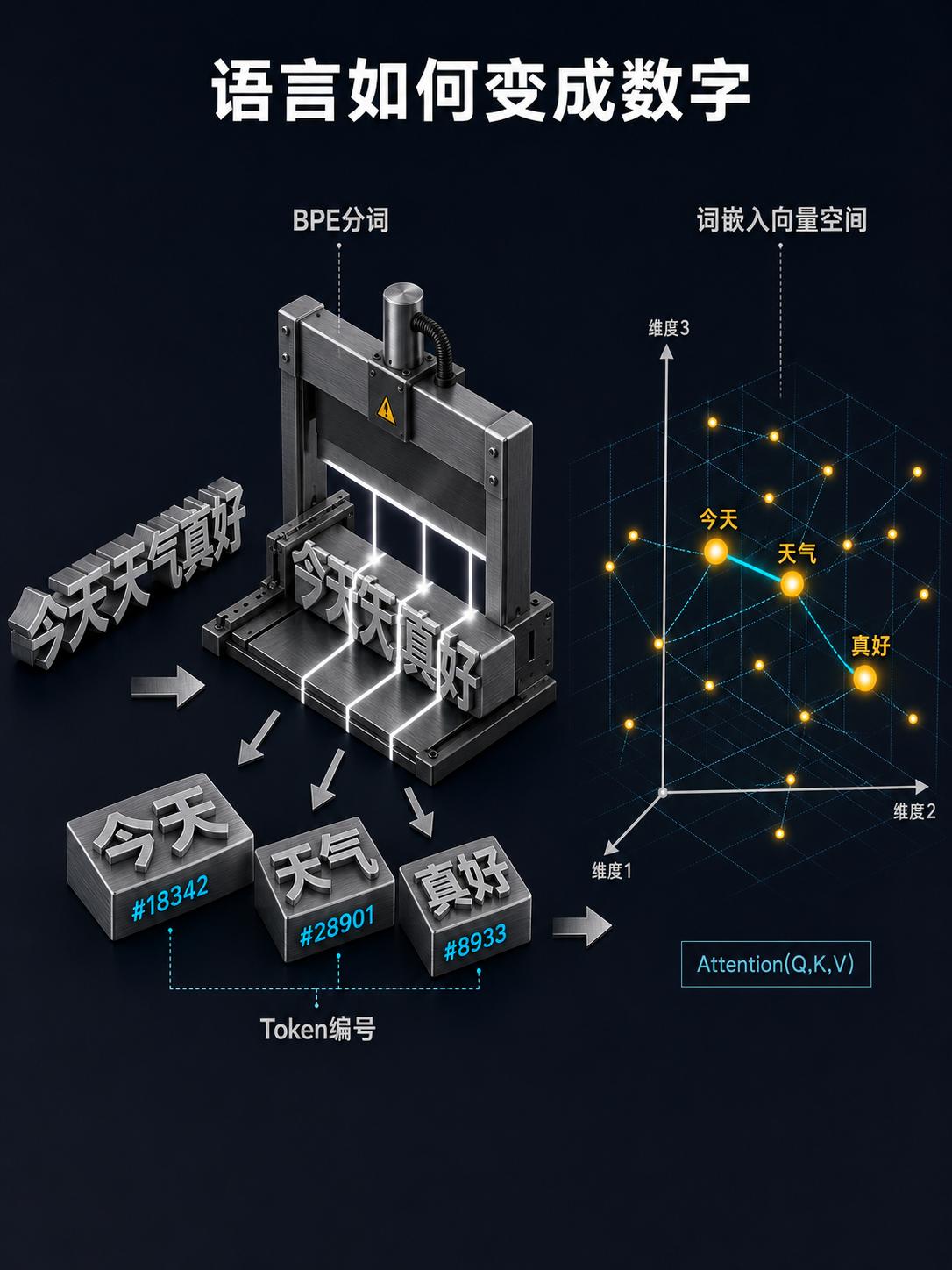
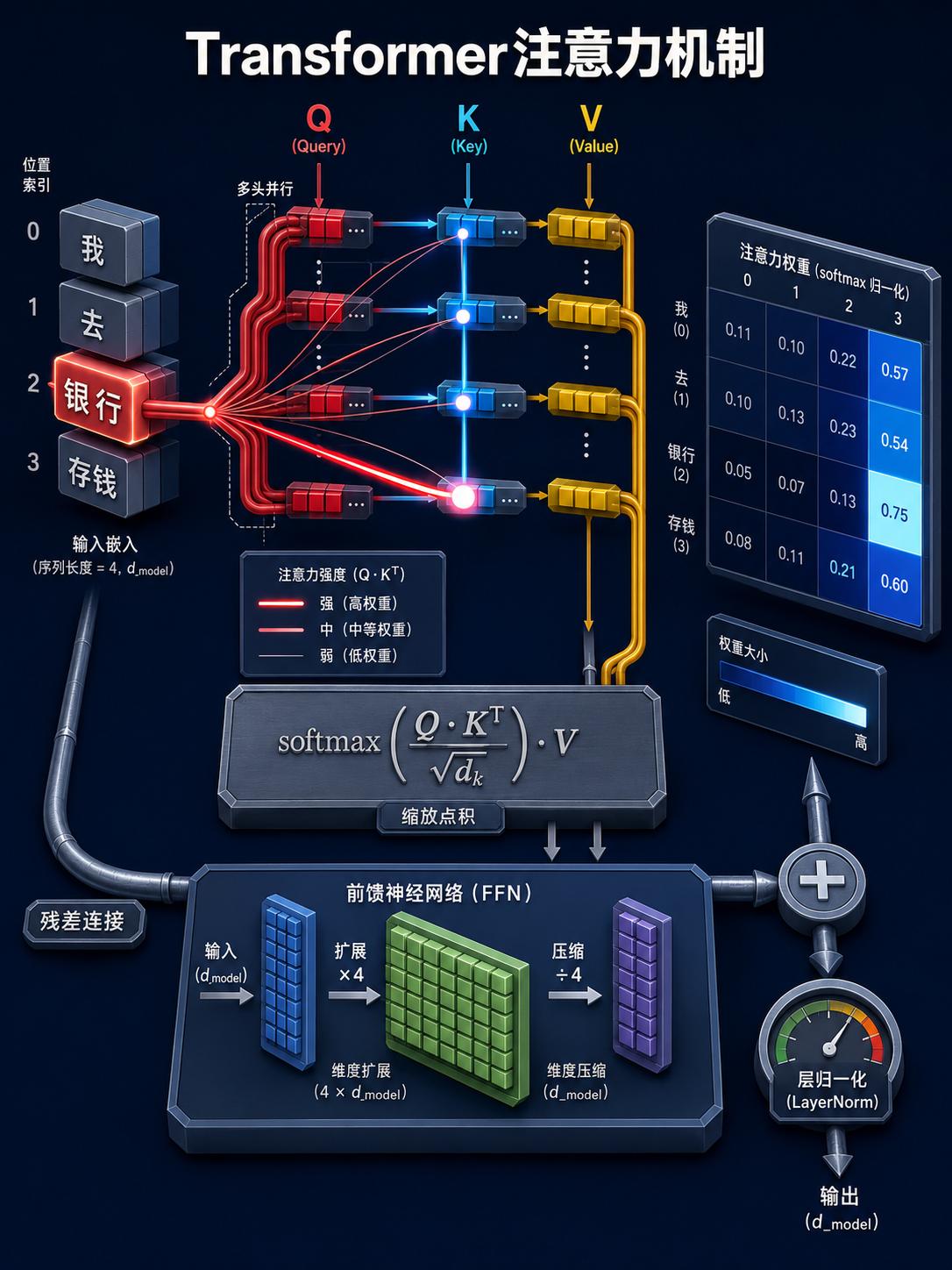
答案藏在一条精密到极致的技术流水线里。大语言模型不是魔法,是工程。从把人类语言切成 token 数字编号,到用几千维向量给每个词编码语义坐标;从 Transformer 架构里 QKV 三角关系的注意力计算,到 96 层堆叠的残差连接和层归一化——每一个环节都是一道独立的工程难题。
最烧钱的部分是预训练。GPT-4 的训练成本据估计在 6300 万到 1 亿美元之间,2048 张 GPU 跑 3D 并行,凌晨三点 Loss spike 时需要在几分钟内决定回滚还是调参。而真正值钱的秘密武器是数据清洗管道——同一个架构,用更好的数据训练,效果可以超过两倍大小的模型。这就是 Anthropic 在数据工程上砸顶级工程师的原因。
后训练阶段决定了模型从"会说话"到"会帮忙"的跨越。SFT 教会模型回答问题,RLHF 让它变得安全诚实,Anthropic 自研的 Constitutional AI 让 AI 用"宪法"自我约束。而 DPO 用更简洁的数学跳过了奖励模型这一步。每一个选择背后,都是对齐能力与灾难性遗忘之间的精密权衡。
Scaling Laws 告诉我们一个残酷而简洁的事实:模型性能只取决于参数量、数据量和算力投入,而且这种关系是可预测的。英伟达的万亿市值,很大程度上就建立在这条幂律曲线之上。推理阶段的 KV Cache、量化、采样策略,则决定了模型能不能在你手机的零点几秒内给出回答。
所以 75 万美元买的到底是什么?不是某个单一技能,而是一个人能在分词策略、注意力架构、分布式训练、Loss 稳定性、对齐工程、推理优化这六步里,每一步都做到顶尖。读完这篇拆解,你或许拿不到那个 offer,但你会彻底理解:那个每次秒回你的 AI,到底经历了怎样一条精密到极致的诞生之路。