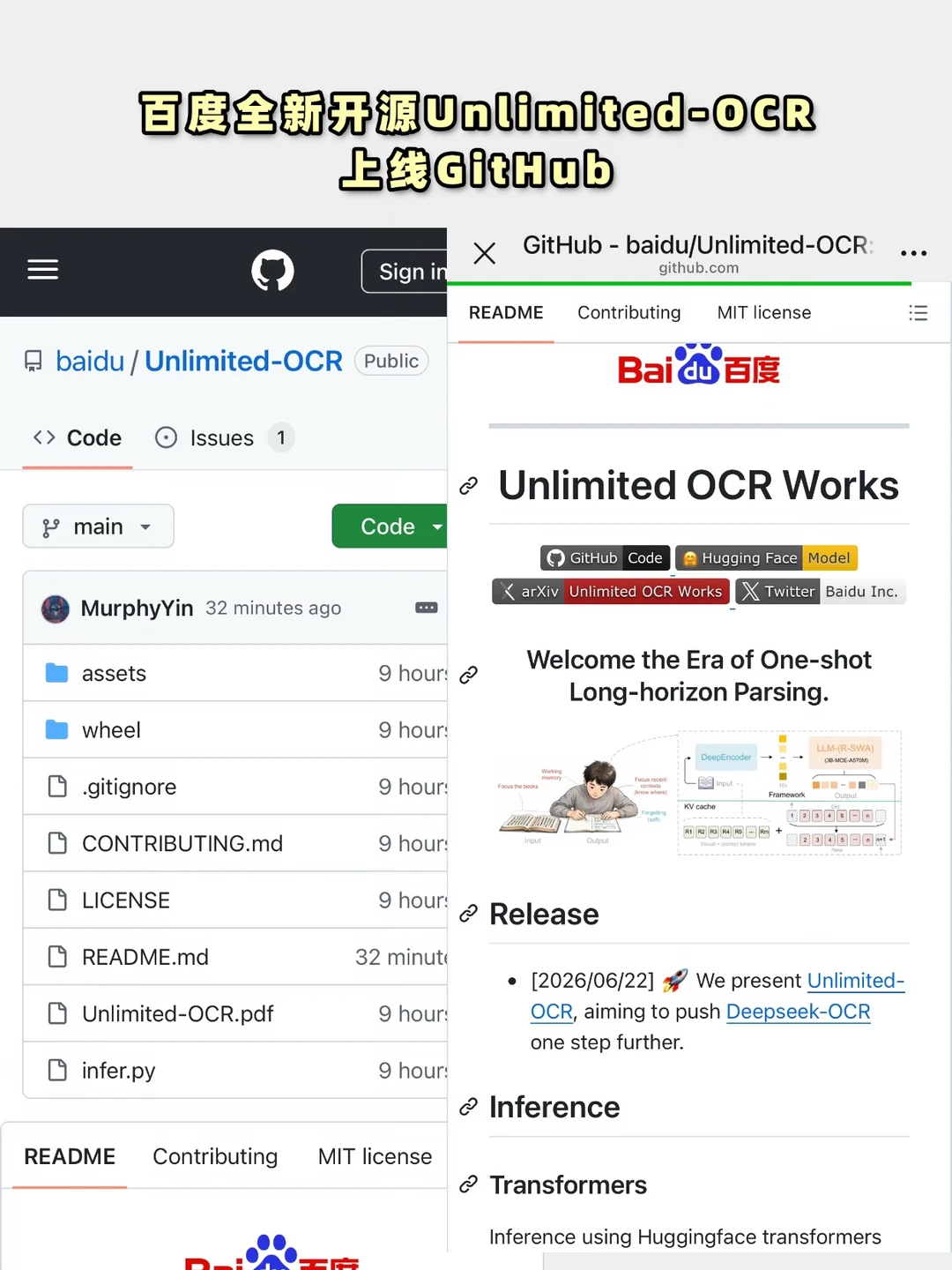
本来以为只是又发一个OCR模型,结果越看越发现,这里面的信息量比模型本身还大。
-
Unlimited-OCR最大的升级,是把长文档OCR这个老难题狠狠干了一遍。
它模拟的是人读书的方式。
比如你看到第50页,不会再记得第一页讲了什么;模型也是一样,不需要一次把几百页图片全记住,而是边读边忘,也就是论文所谈到的“软遗忘”机制,这样一来,古籍、论文、多页PDF可以连续解析,不容易出现计算量爆炸问题。简单说,Unlimited-OCR像是真正把一本书"读完"。
-
官方介绍里,这次解码端用了R-SWA参考滑动窗口注意力机制,编码端沿用了DeepSeek-OCR里的DeepEncoder思路,所以长上下文能力提升不少。
不过更有意思的是另外一个细节。
不少开发者发现,Unlimited-OCR的GitHub主页专门致敬了DeepSeek-OCR系列,甚至在技术报告中,高达40+次提到了DeepSeek-OCR,不少人开始猜测,这项目的背后大神,搞不好是此前DeepSeek离职的 OCR核心作者魏浩然,毕竟这项目怎么看都像是在原有技术路线上继续往前做,而不是另起炉灶。
如果这一点属实,那得期待下百度之后还会端出什么了🤔