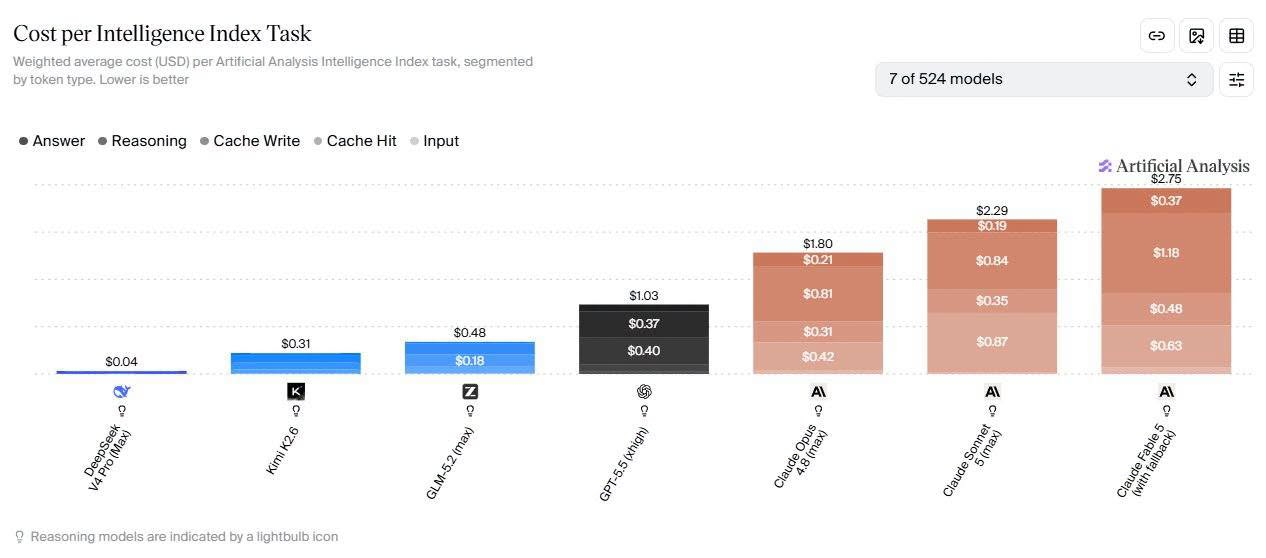
国外部署了一项前沿大模型的“C/P值”(性价比)评测。与以往单纯计算 Token 消耗的评测不同,这次的评判标准是:在完成预先定义好的、具有实际经济价值的智能开发工作时,完成单个任务所需的实际美元成本。简单来说,既然任务标准和产出价值是固定的,那么谁花的钱最少,谁的性价比就最高。
从具体的评测柱状图来看,各家模型在 Answer(回答)、Reasoning(推理)、Input(输入)等环节的累加成本一目了然:
• 高成本梯队:Claude Opus 4.8 (max) 的单任务总成本高达 1.80;Claude Sonnet 5 (max) 更是达到了 2.29。这也印证了您的观察:虽然 Sonnet 5 的单次调用单价可能较低,但由于在处理复杂任务时消耗的 Token 更多,导致完成整体任务的总成本反而比 Opus 4.8 更高。
• 极致性价比梯队:位于图表最左侧的 DeepSeek V4 Pro (Max)(带有灯泡图标,代表其具备强大的推理能力),完成同样一个标准智能任务的累加成本竟然只有令人咋舌的 $0.04!
DeepSeek 到底“发生了什么事”?为何能做到如此离谱的低价?
图表中 DeepSeek V4 Pro (Max) 极低的成本并非标价出错,而是源于其在底层架构和工程效率上的极致优化:
1. MoE(混合专家)架构的高效压榨:DeepSeek V4 Pro (Max) 拥有 1.6 万亿的庞大参数,但在推理时,每次只会激活其中的 490 亿个参数(即稀疏激活)。这意味着它就像一个拥有一千名专家的超级智囊团,每次只按需唤醒最合适的几十个专家来解决问题,从而在保证顶级智商的同时,极大地节省了单次计算的能耗。2. 算法与注意力机制的革新:模型内部采用了诸如 MLA(多头潜在注意力机制)等前沿技术,显著提高了 GPU 集群的计算效率,降低了显存占用。3. 结果导向的经济学竞赛:正如 Artificial Analysis 机构升级评测标准所强调的,现在的 AI 行业正在从单纯的“跑分竞赛”转向“经济学竞赛”。DeepSeek 正是踩准了这个节点,用远低于美国闭源巨头(如 Anthropic 或 OpenAI)几十倍的成本,做到了与之相当的顶级智能水平(在 Intelligence Index 上仅落后 Opus 4.8 约 12 分,但成本仅为后者的四十五分之一)。
总而言之,这张图不仅展示了 DeepSeek 极其恐怖的工程化成本控制能力,更预示着 AI 行业的一个关键转折点:当“智力”的上限逐渐触顶时,“成本”的下限将重新定义各大厂商的市场格局。
——————————DeepSeek就是极致的性价比