
2026年3月23日,超声波俱乐部汕头龙虾大会成功举办。大会吸引了三百余位AI创业者、投资人、当地企业相关负责人以及龙虾爱好者参加,广东主流媒体和汕头电视台也对大会进行了深度报道。
大会现场,趣丸科技副总裁李博闻为大家带来了《OpenClaw爆火背后:开发者Agent记忆管理的挑战》的主题分享,以下为李博闻的分享整理:

大家好,我是趣丸科技的李博闻。现在我主要探索AI和社交相关领域,同时也探索一些AI和长期记忆相关的东西,今天主要想跟大家分享的是龙虾和记忆相关的内容。
刚才子超讲到一件事情是,我们今天不同的人用龙虾,首先要问自己一个问题“我把它当做什么?”你可能把它当做是你的个人助理或伙伴,可能把它当做是你的下属,也可能你希望养一只龙虾,当别人也用你养的龙虾的时候,可以解决同样的问题。
这几种看似不太一样的角色定位会给我们带来养龙虾方式的差别。先说我怎么理解养龙虾这件事情。养龙虾,某种程度上你在做什么?其实你在做几件事情:
如果是个人的助理,你在做的核心一件事是让它更懂你,因为它足够懂你,因为它有你足够多的信息,所以它在处理一个特定任务的时候,它能够依照你的喜好做得更好。
当然,你也可能把它当做一个下属,这个时候它更了解之前我们在做哪些事情,今天的这件事情和之前的什么事情相关,所以我应该把事情做得更好。
还有一种情况是龙虾创业。养一只龙虾,能够解决某一个行业或某一个场景的具体问题,它的解决方案比其它人的龙虾或者比单模型更好。相当于在这个场景下的Know-How,以及这个场景下的所有信息和私有数据封进了我的龙虾里,让我的龙虾可以把这件事情做好,在某一个具体场景里可以解决得比别人更好。
如果你在做的事情是能规模化地、低成本和可治理地跑起来,如果你希望龙虾可以提供给别人一个应用的话,就会存在三个问题:
第一个,企业级的上下文控制,就是它的性能是不是高的,它的效果是不是真的好?
第二个,我的成本是不是低的?大家现在都在说龙虾的Token消耗很大。
第三个,是不是可治理的?以及隔离、审计和部署。可能我们绝大多数同学用不上,但是如果今天你不是养一只龙虾,而是希望几只龙虾能够分别以不同的角色协作的时候,那么隔离和部署就变得更加重要了。
1.场景经验和私有数据,是养龙虾下一阶段真正的差异化关键
我们观察了大量的龙虾社区,观察大家是怎么养龙虾的。我提供一个视角,就是大家期望龙虾的介入层面有所不同。这个介入层面的不同并不是由低到高的层级递进,而是定位不同。这个要首先说明。

第一种是细节执行。帮我做“我知道怎么做但我不想做的事”。这个事很烦、很复杂,我完全知道怎么把它做到足够好,但是太麻烦。你帮我搞定。
第二种是能力扩展。帮我做“我一个人做不到的事情”。可能因为时间、精力的问题,也可能是我个人的能力做不到的事情,比如我们都知道龙虾今天有一个能力是可以直接调Vibe Coding开发某一个东西。
第三个是决策辅助。“帮我处理信息但最终判断仍由我完成”,你给了我足够多的建议和可以去做判断的东西。
第四个是自主决策。“直接替我去做决策,我保留监管权。”
我们发现这四个维度里,当人们要介入的层级越深,对于记忆这件事情的依赖就越强,因为龙虾需要那些个性化的记忆才敢于去深入。
第二个观察是,由“帮做”到“帮决策”,你会发现记忆不再是一个附属能力,它可能是一个非常重要的能力。
我具体展开说一下,关于上面的四种维度,分别从服务两个维度,一个是服务自己,另一个是服务别人的角度进行举例。

第一个是细节执行。把那些我不想亲手做的事情交出去的时候,它实际面临的是什么状况?那也是我们绝大部分人在最开始用龙虾的时候干的事情。
比如很简单的早间晨报。你(龙虾)当然可以帮我总结各种早间晨报,但这里面你总结的早间晨报是不是我想看的?涉及需要知道我的喜好、品味、习惯,才能真正做好早间晨报,让这件事情对我有益,而不是一个今日头条推荐的早间晨报。
就服务别人来说,如果我现在在做一个内容创作的流水线,我非常清楚内容创作应该分成哪些角色,每个角色的每一步都该做什么。那我用一个龙虾或三个龙虾去搞定,这个时候需要做的是什么呢?第一流程,第二品味,内容的品味,它才会做出这个品味下的东西。也就是龙虾要记住我的工作规范和固定的流程,以及知道我的品味。

第二个是能力扩展。帮我做到更多。这里我们还是同样的分为,养一个为自己的龙虾,和做一个为别人的龙虾。
如果是一个为自己的,举个简单的例子,就是我晚上睡觉的时候提了个需求,“龙虾你帮我写一个APP出来”,然后明天早上我可能就可以看到了。
那服务别人呢?如果是一个投研机构,我有大量的投研的分析方法论和分析的信息,甚至有大量的过往投研的数据。这些我如何应用起来做成新的投研?这里会用到同样的两个东西,一是技术工作规范和领域的经验,当我不在场的时候也能做。第二是领域经验必须能够被准确地召回。如果说大家用龙虾多一点的话,会发现记住和准确召回可能是两码事。这件事情你去问它,“你知不知道?”它可能是知道的,但遇到了一个具体场景,它不一定能够真的用出来。
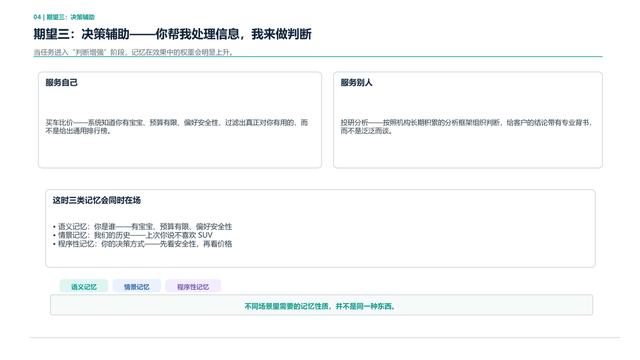
第三个是决策辅助。我还举个简单的例子,比如说买车比价。你可以跟你的龙虾聊天的时候说,“我最近准备换一辆车了”,今天所有的APP都可以做到我给你推荐几辆车,你可以告诉我(龙虾)你想要的价格,你可以告诉我(龙虾)你喜欢的品牌,但实际上,它真正能够服务好你的是什么?其实不是汽车销售告诉你这辆车的优势是什么,更关键的是我要知道今天为什么要换这辆车?过往所有的信息是我一时冲动换这辆车,还是我有某些喜好?
比如可能我换这辆车核心原因是我有宝宝了,我需要一个更大的车、更安全的车,但这件事情可能并不在你最开始想换车时考虑的第一范畴内,但有可能在你养龙虾的过程当中,龙虾是知道的,这个才是真正辅助决策的价值。它不是基于你的所有喜好,整理信息之后告诉你,而是发现那些可能本来该被你意识到的东西,而在今天提醒你,它应该是你的辅助决策的一环。
第二个例子,我还说投研分析这件事——服务别人,同样会存在这样的情况,就是如果你是一套固定的分析方式,固然是OK的,但所有固定的分析方式它并不能够解决所有问题。我们中国人经常说就事论事,那这个就事论事是哪来的?是有了过往的一些信息的经验和积累之后,在那件事情上我能够调用出来,才能够做到真正的就事论事。

最后一个是自主决策。自主决策,我的看法是现在离得还有点远,虽然社区上有一个比较惊艳的东西,就是我们经常看到有人说我养了一只龙虾,去炒股赚了多少钱。还有像客服工单系统有百分之多少托管了出去。
但实际上我认为,自主决策难的地方在于要解决两个问题,一个是信任的问题,第二个是自主程度的问题。自主程度可能取决于模型的能力,取决于它的所有已知信息是不是支持它能够自主。
就像我们今天招来一个员工,他工作的第一天,你不太可能直接把公司特别复杂,需要判断的事情交给这个员工,因为你知道可能他有很多信息是不知道的,或者某些内隐的东西他是不知道的。第二个就是信任问题,信任必然是个需要长期建立的事情。
所以当这些被叠加的时候,你会发现到自主决策这一层,为什么短期可能不容易实现?是因为它不再是一个独立的场景,它是一个叠加在所有维度程度下的场景。你对它的信任取决于它对你和场景的了解深度到底是怎么样的。
此外,我认为对你和对场景的了解深度其实是两码事。比如刚才举的例子,如果自主决策到了龙虾帮我买辆婴儿车回来,不用再让我决定,反正你直接买回来就好了。那这个时候,对你的了解决定了,我到底该买一辆什么样的婴儿车?婴儿车大家好像觉得就是价格的问题。当然它一定会出现一些特例,比如说有的宝宝可能本身先天有一些身体不适的地方,所以它必须要找一辆婴儿车是能够平躺的,这件事情就是基于对你的了解才能做到的。
那对场景的了解是什么意思呢?还是刚才那句话,如果它是为某一个场景服务的,那么场景了解深度其实就是它的最大价值。换句话说,今天如果我们去做一个服务于别人的龙虾的时候,我们的最大价值是什么?就是我们对那个场景本身了解有多深,抽象化程度有多高,以及有哪些私有数据我们可以应用下去。

小结一下,私有经验和私有数据是在我们做了一个自己的龙虾的时候,真正具有不可替代的关键。
刚才说到的授权维度不同的四种方式,我们都会看到几个问题。第一个,现有的龙虾它做到越复杂的任务,成本消耗越高。第二个,越复杂的任务,龙虾能够探索的上限就越不可控。
今天我们说OpenClaw它不是没有记忆,它有一个非常好的记忆方式。但是在成本和上限上,它会暴露出一些可能我们需要去探索和解决的东西。这些可能是造就我们的龙虾真正符合我们,并且有能力的地方。
2.龙虾记忆管理机制的实践与思考
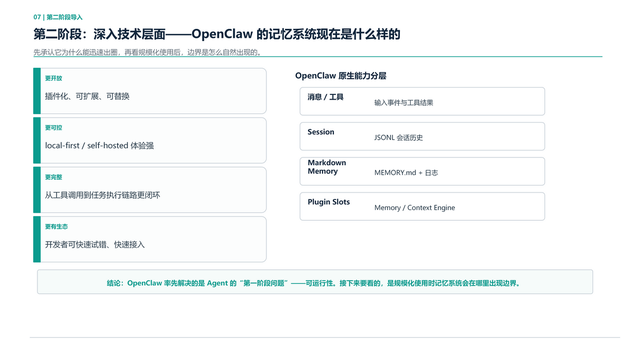
第二部分,深入技术一点,我们看看龙虾是怎么实现它的记忆的?简单来说就是龙虾其实它做了一个非常好的东西,更开放,插件化可扩展、可替换,更可控,本地可以部署,更完整,从工具调用到任务的链形更闭环,以及到更有生态,开发者可以快速试错。它自己做了能力的分层,消息层、对话层、记忆层和插件层,这些都是它本身有的技术。这些其实非常好地让我们可以在每一个地方,做到你认为更适用你的方式。
接下来分享一下我们怎么看这件事情。因为刚才给大家介绍各种授权的时候说了,你需要不同的信息。我们从认知科学角度把记忆分成了三种维度,这三种维度对应了不同的信息和不同的信息的取用方式。我们把它在龙虾的所有实现对照一下,这三种分别是语义记忆、情景记忆和程序记忆。

简单理解一下,什么是语义记忆?语义记忆就是我是谁?我是哪天出生的?我有没有孩子?这些碎片型的事实性信息,它被归纳成了语义性记忆。
情景性记忆是什么?可能今天我讲的所有东西被归纳成了一个情景记忆,或者平时你在跟龙虾聊天聊了100句,这都属于情景记忆。
程序性记忆是什么?程序性记忆就是关于怎么做事的,这个事具体该一步一步怎么做的。
我们看到这三者记忆上会有一个非常大的明显差别,这个明显差别其实在龙虾的Markdown里也有体现,它会用不同的Markdown命名来做。
但实际上你发现在用它的时候会出现一些区别是什么呢?比如说第一个语义性记忆,必须要碎片且足够精准的,比如说我是谁?我叫什么?我是哪一天出生的?这是非常碎片化信息,但是这些碎片化信息你必须要精准拿到。
而情景记忆,可能是我们在100句聊天里说到了某一个真正跟我有关系的东西。你是不是在真正需要那一个信息的时候,能够把它提取出来?
最后一个程序性记忆怎么做的?它不再是碎片化的,它是一个完整的信息,你必须要把这个完整信息一字不差的记下来,才能真正把这件事做好。
这是龙虾的解决方案。龙虾有统一的检索层,还有一个默认的压缩方式。

但是有几个问题,第一个是统一的检索,在我们刚才看那三种记忆分类方式的时候,就不能很好地解决这个问题,因为不同的信息需要的检索方式应该是不一样的。
第二个是同一个压缩方式,也不能作为同一种信息做处理。
第三个是如果你不能去做更好的共享环境的隔离,会出现一个问题——今天这只龙虾既跟我交流,又跟别人交流的时候,可能把我只想让它知道的信息告诉了别人。存在我知道只有你该知道他不该知道这样的问题,该怎么解决。以及企业治理的能力缺位问题。

再稍微展开一点说三种记忆方式分别解决的是哪些问题?
第一个语义性记忆,是关于事实和知识的用户画像的典型的实现。现在的龙虾或者一些记忆的方式,基本上是用向量匹配和模糊匹配的方式去做,但是你会发现这件事情更需要的是它需要被结构化组织,它需要按字段进行精准搜索的。就像我刚才举的那个例子,我只需要知道你叫什么的时候,我不需要把你的其它相关信息拿到,这是第一。第二我需要知道你叫什么的时候,我一定要知道你叫什么。我不能拿到一个其它的不太相关的东西。
第二个是情景性记忆,是关于具体事件和交互的历史,天然带有时间和情境。大家可以理解为你每天跟你的朋友聊天,你每天跟龙虾聊天,其实都算情景记忆,甚至你今天早上去吃了饭,干了啥,喜不喜欢喝什么东西,比如吃了肠粉里面的什么东西好吃?这都属于情景记忆。它是非常杂乱连续的信息。但在处理一个具体问题的时候,恰恰在这些非常杂乱连续的信息当中,会出现那些对你个人来说更加有价值的东西。
回想一下刚才我们说的买车的例子。你为什么要买这个车?买车的时候你有哪些信息?这些信息基本不太可能从语义当中拿到,基本是在龙虾知道你所有情境性信息才能给出来的。它的更大价值不是检索出哪辆车OK,而是因为那些信息重新帮你思考了,在做这个决策的时候你应该考虑哪些因素。这是情景记忆当中它能够提取出来最有价值的部分。
第三个是程序性记忆,大家可以把它理解成Skill或者调Tools。对它的要求是当我要用它的时候必须完整,一字不差。因为但凡你做了其它的调整,这件事情都完不成,或者这件事情都完成不好了。
所以我们发现如果三类记忆都用同一种检索方式、存储方式来做,就好像你用同一把尺子去量了长度、温度和重量,必然会把它搞混乱。
无论我要做一个为自己服务的龙虾,或者要做一个为别人服务的龙虾的时候,你都可以考虑一下我的哪些信息分别对应在这里边的哪一部分?这一部分对我自己或对我服务的那个场景有什么样的价值?我应该把什么样的信息真正地喂给它?某种程度上那个东西就是你怎么去养好你的龙虾。

回到技术实现上,龙虾会把“记忆检索”和“上下文装配”明确地拆成写入层、检索层、装配层和压缩层,分别去解决记忆的一些问题,这也就意味着第三方如果想创造显著的价值,必须介入的不只是“多存一点的记忆”,而是能够在这些不同层级里去构造一个整体的决策逻辑。

具体从企业角度来说,问题不再只是“记不记得”,而是“怎么记,记多少,什么时候取,如何治理”。我们分别从两个例子来说。
第一个,如果在社交和长期聊天的时候,你需要考虑的是用户跨天、跨周、跨月地持续交流,要靠记住长期的偏好、识别短期的状态变化。如果只靠粗糙地总结或者浅层地召回,就会出现记得不准,记得不活,或者记得不对这样的问题。
第二个,如果是数字员工的话,连续做文档撰写、总结报告,或者代码生成,这里的核心是你要遵循企业规范,要继承你的历史案例,要延续你的组织语境,上下文的管理一旦弱了,就会出现约束失真、流程失真,甚至成本失控的问题。

所以关键问题在于召回什么、什么时候注入、注入多少,和我们要考虑如何兼顾共享、隔离和审计。
共享、隔离、审计其实是三个问题。审计问题最简单,如果所有存下来的信息是以KV矩阵(高维向量矩阵)的方式存下来的,其实它是不可被审计的。也就说你只能用问答方式知道它记住了什么,但是你并不知道真实地记住了什么,这个对于企业来说其实是一件挺危险的事情。
共享和隔离就是角色的分工决定了你可知道的信息和你可调用的信息。传统的理解里,记忆等于存储加召回,重点在于把东西存下来,关键时候拿出来,它像个数据库一样。
但今天我们再看这件事,如果你想把龙虾往下一级去用好,甚至为别人提供服务,可能记忆等于上下文的控制能力,重点在于你什么时候召回,什么时候注入,预算的控制,隔离治理和可审计性到底做得怎么样。
我们提出的一个观点是核心要解决的其实不再是记忆的存储问题,而是context control的问题,也就是上下文真正的管理问题。

来看看现在主流都有哪些方案在做?当然有很多的方案,我只举了两种现在相对主流的方案。
第一个路线是全生命管理的memory。它的基本做法是一个可插拔的记忆插件,你可以做的是对话前把它recall,对话后把它重新写入。它的好处是接入更轻,改造成本更低,它更像一个外挂的记忆服务,可以快速地接入各种现有的Agent框架。大家在用龙虾的时候,应该可以在搜到挺多这样类似产品或者插件服务的。
第二个路线是做上下文管理,它不只是做召回和写入,而是直接重构了整个上下文的组织方式,它更强调的是分层加载和Token预算的问题。所谓分层加载就是一个信息我是不是能把它重新分层?它抽象层是什么样的,摘要层是什么样的,以及原文层是什么样的?它更像一个上下的控制基础。
两类没有谁更好,只是适用在不同的场景里。如果大家用到的时候,能够给大家一些启发。

先说第二类,它最核心的一件事情是做了分层的加载和结构化的寻址,这件事情的好处是什么?分层的加载和结构化的寻址,不仅仅是一个检索器,它更做到了一个上下文如何去组织管理的问题。如果大家应用深一点的时候,你会发现这件事情它不再是以前一块信息一起去搜的问题,而是我把它重新组织了。
简单的理解有点像图书馆,你要找到一个具体内容时,做法应该是我先告诉你这本书的内容是什么,这本书的上层可能在哪个分类里,再上层可能是具体的书名,或者它在哪一个大的分类区里。这样,其实你的信息被重新整理过了,重新整理的应用效率会更高一点。

再说更轻的接入方式,就是每一次对话前把记忆放进上下文,对话之后再把新生成的记忆存起来。它的好处就是快、简单、方便、好做。

应用到刚才这件事情,记忆本身或信息该被记下来的东西本身是有不同分类方式的,不管是插件的方式还是重新上下文整理的方式,都应该贯穿一个思想——不同的信息,应该用不同的检索方式,甚至存储方式,才可以把它应用的效率更高。
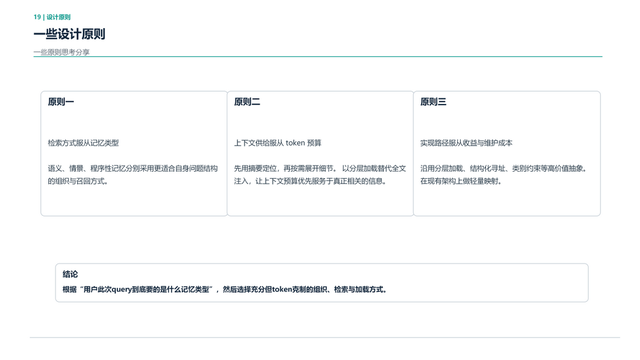
我们提出这些看法,如果大家觉得有价值和意义的话可以去参考。如果你要做一个类似的记忆的时候,它可能有几个原则,第一个是检索应该服从记忆的类型,而不是检索服从某一种技术方案或范式,语义、情景和程序性的记忆分别应该采用更适合自己自身问题结构的方式去组织和召回它。
第二个是上下文应该服从Token的预算,也就说你总要考虑一件事情,这个预算能不能控制得住。我不止追求效果,还追求成本。
第三个是实现路径服从收益和维护成本。分层加载、结构化寻址、类别约束等高价值抽象,它是非常有价值的一套东西。

所以在此基础上我们做了一个尝试,大家也可以按照同样的逻辑和思路去做一些尝试。我们做了双路径,一路是我们去做更情景性的记忆,一路是我们去做更语义和程序性的记忆。这两路我们在不同的任务下去做不同的信息召回,然后去保证成本相对低一点,效果相对好一点。
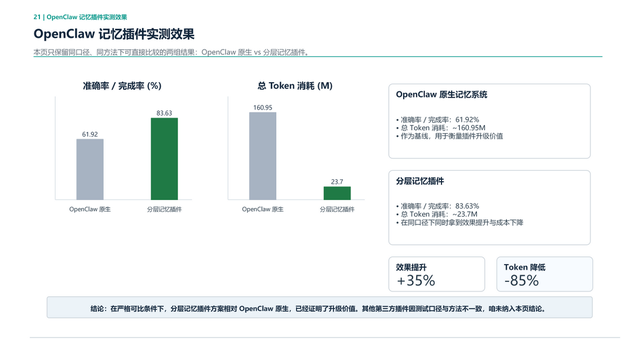
这是一个大概的实现思路。实际效果我们做了一下对比,它和原生的OpenClaw在准确率上和在Token消耗上都有一个相对不错的表现。因为它用到了刚才我说的,到底什么内容,该以什么方式存,什么方式取?这些数据想告诉大家,似乎这套方案是OK的。如果大家想用的话,也可以用类似的方案解决这个问题。

最后总结一下刚才说的所有内容,我们观察到的方向是私有数据和场景经验,可能是下一个阶段你去养龙虾真正的差异化所在。下一个阶段的竞争可能不再是谁能干,而是谁在垂类的场景里面可以干得更好,不管是为自己还是为别人。
OpenClaw解决了可运行,让更多人能够用上Agent,但在我们的观察里,用得好不好还是有一定差距的。跑得好的案例可能都有共同点,就是把自己真实的数据、经验、场景和判断融到了系统里。不管是服务自己让它更了解自己,还是服务别人,在运用这些自己掌握的宝贵资源上,我希望能够为大家提供一些思路和解决方案。
这就是我今天的分享,希望大家觉得有帮助或者有价值。

峰会现场












欢迎更多AI企业一起支持超声波俱乐部AI Open Day城市龙虾大会的全国巡回,让我们一起开启全民龙虾的AI大时代。
深圳龙虾大会
欢迎报名
超声波俱乐部将在4月举办深圳龙虾大会,欢迎全世界的AI创业者、投资人、CTO/技术、大厂高管、行业大咖、对龙虾无限热爱的超级虾友们一起参加!北京、上海龙虾大会人气嘉宾齐聚深圳,更多神秘嘉宾陆续登场。

超声波俱乐部目前拥有超过2000位AI领域的顶级创业者,连接超过10000位AI领域的创始人、CTO、产品经理、风险投资人。
超声波俱乐部定期组织成员开展内部分享会,也会举办不定期的开放交流活动,分享内容涵盖AI行业趋势、技术创新、产品及商业等方向。