近日,一项覆盖 2018-2024 年间 445 篇顶级 AI 会议论文的国际研究,给迅猛发展的大语言模型(LLM)领域泼了一盆冷水。牛津大学、华盛顿大学等机构的研究者联合 29 位领域专家,发现每篇基准测试论文均存在至少一项重大方法论缺陷,当前主流测试标准难以客观衡量 AI 技术的真实进步。这一发现不仅动摇了现有 LLM 性能评估的根基,更引发了业界对 AI 研究可信度的深刻反思。
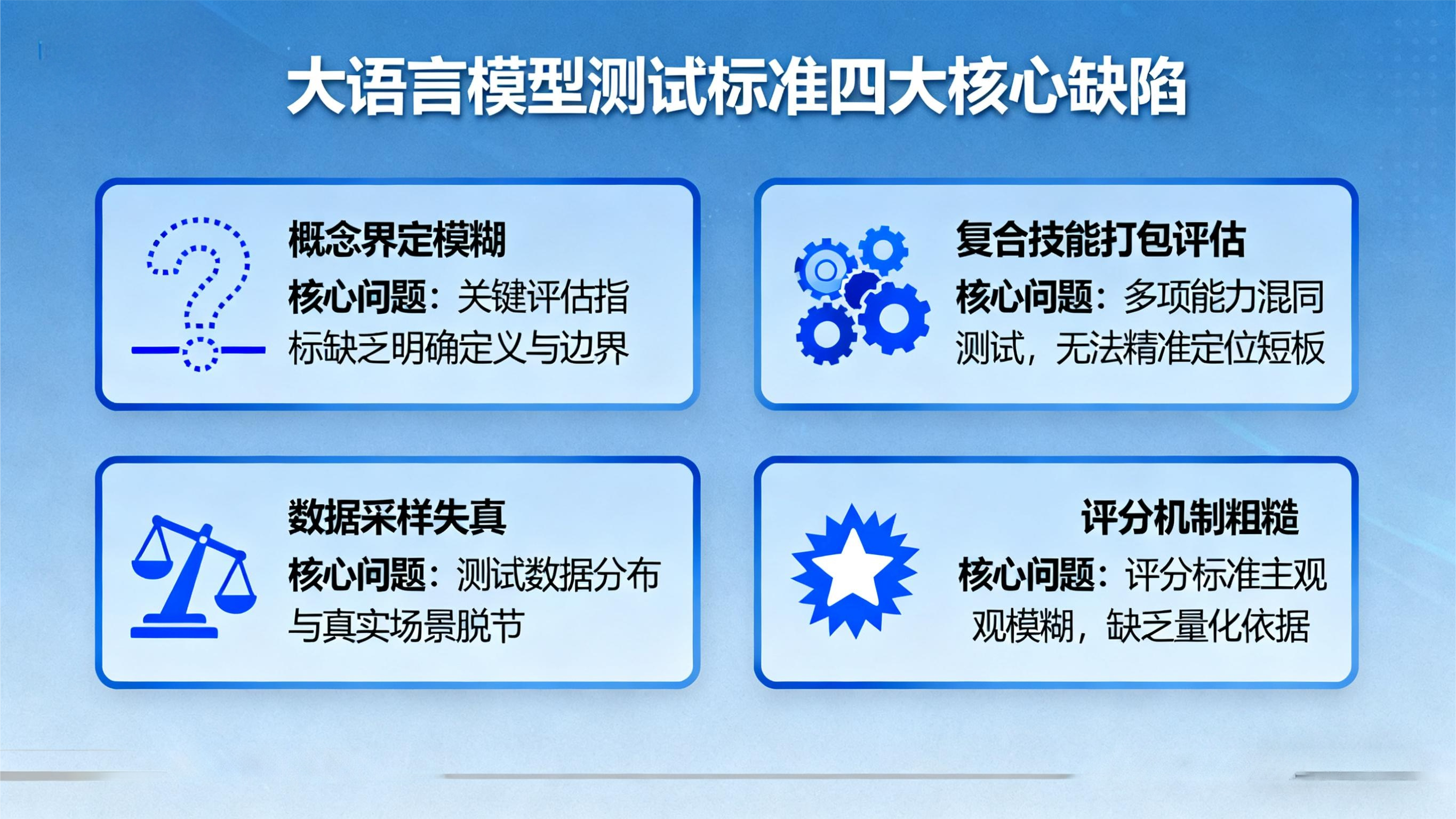
四大核心缺陷:测试标准的 "致命硬伤"
研究揭示的缺陷呈现系统性特征,集中体现在四个关键维度:
概念界定模糊,结论失去根基。尽管 78% 的基准测试会说明任务内容,但其中半数未明确定义 "推理"" 对齐 ""安全性" 等核心术语。这种模糊性导致不同研究对同一能力的评估缺乏共识,例如某模型在 A 测试中被判定 "推理能力优秀",在 B 测试中却表现平平,本质是对 "推理" 的定义存在偏差,最终使研究结论丧失可比性。
复合技能测试 "打包评估",结果难以解释。约 61% 的基准测试聚焦 "智能体行为" 等复合技能,这类任务同时涉及意图理解、结构化输出生成等多个子任务,但研究者极少对各子项单独评估。当模型测试得分偏低时,无法判断是哪个子任务存在短板;得分偏高时,也难以确定核心优势所在,这种 "黑箱式评估" 严重阻碍技术迭代。
数据采样失真,脱离真实应用场景。数据问题成为重灾区:93% 的论文采用便利抽样,12% 完全依赖此类非代表性样本,导致测试结果无法反映模型在真实场景中的表现;更有 38% 的测试存在数据复用,部分研究直接套用已有测试集,不仅增加数据污染风险,还可能高估模型的复杂推理能力 —— 尤其在数学推理等关键任务中,这种做法会让模型 "刷分" 而非真正提升能力。
评分机制粗糙,缺乏统计严谨性。超过 80% 的研究将 "完全匹配率" 作为核心评分指标,要求模型输出与标准答案一字不差,却忽视了自然语言的灵活性。更严重的是,仅 16% 的研究使用统计检验方法对比模型差异,仅 13% 引入人工评判,绝大多数测试未提供置信区间或不确定性分析,导致评分结果的科学性大打折扣。
缺陷背后的深层影响:AI 发展的 "导航偏差"
这些缺陷并非单纯的技术疏漏,已对 AI 领域产生实质性误导。一方面,模糊的评估标准让研究者难以精准定位技术瓶颈,可能导致资源错配 —— 例如过度追求测试分数提升,而非解决真实世界中的鲁棒性、安全性问题;另一方面,失真的测试结果可能误导行业应用决策,让企业在选择模型时陷入 "唯分数论" 的陷阱,忽视实际场景中的性能落差。
Meta 首席 AI 科学家杨立昆近期指出的 "训练数据边际效益衰减" 现象,更凸显了测试标准改革的紧迫性。当模型规模扩张的成本持续攀升,若缺乏科学的评估体系,将无法判断技术进步的真实方向,甚至可能导致整个领域陷入 "伪进步" 的困境。
破局之路:构建科学评估的新框架
针对上述问题,研究团队提出了明确的改进路径:首先,必须清晰界定测试目标与边界,避免核心概念模糊化,确保评估聚焦特定能力维度;其次,需重构数据采集机制,减少便利抽样依赖,建立独立且具代表性的测试集,严防数据污染;最后,应革新评分体系,结合定量统计检验与定性人工评估,引入不确定性分析,让评分结果更具说服力。
从长远来看,LLM 测试标准的完善需要学界、业界的协同努力。这不仅要求基准测试的方法论更趋严谨,更需要建立动态迭代的评估机制 —— 随着模型能力的进化,测试任务、数据分布、评分指标也应随之更新,真正实现 "以评促研",让 AI 进步建立在坚实的科学基础之上。
大语言模型测试标准的缺陷暴露,并非 AI 发展的倒退,而是行业走向成熟的必经之路。当技术狂奔时,唯有校准评估的标尺,才能确保前进方向的正确性。未来,一套兼顾科学性、实用性与动态性的测试体系,将成为 AI 技术健康发展的关键保障,让人工智能真正朝着解决人类复杂问题的目标稳步前行。