An Empirical Study on Code Comment Completion
Antonio Mastropaolo, Emad Aghajani, Luca Pascarella, Gabriele Bavota
SEART @ Software Institute, Università della Svizzera italiana (USI), Switzerland
引用
Mastropaolo A, Aghajani E, Pascarella L, et al. An empirical study on code comment completion[C]//2021 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2021: 159-170.
论文:https://ieeexplore.ieee.org/abstract/document/9609149
摘要
代码注释在程序理解活动中起着重要的作用。然而,源代码并不总是有文档化的,代码和注释并不总是共同发展的。为了处理这些问题,研究人员提出了自动生成注释的技术。该领域的最新工作应用了深度学习(DL)技术来支持这一任务。尽管取得了一些进展,但对这些方法的实证评估表明,它们的性能仍远未达到对开发人员有价值的水平。我们解决了一个更简单和相关的问题:代码注释完成。我们不是从头开始为给定的代码生成注释,而是研究最先进的技术可以在多大程度上帮助开发人员更快地编写注释。我们提出了一个大规模的研究,在该研究中,我们实证评估了一个简单的n-gram模型和最近提出的文本到文本转换的T5模型自动生成代码注释的性能。结果表明,尽管n-gram模型是有竞争力的,但T5模型更具优越性。
1 引言
代码理解能够占用开发者58%的时间。在这样的过程中,代码注释在帮助开发人员理解手头的源代码方面发挥着关键作用。然而,正如最近的研究所示,代码注释可能完全缺乏,或者没有与相关代码共同进化,甚至对开发人员产生误导。
为了支持开发人员的代码理解活动,研究人员提出了能够自动记录给定代码的技术和工具。这些方法大致可以分为两类:提取和抽象。前者创建代码组件的摘要,该摘要包括从被总结的组件中提取的信息(例如,通过利用一系列包含从类代码中提取的信息的预定义模板来总结类)。虽然实现简单且高效,但如果代码组件使用较差的词汇表,这些方法仍达不到目标。抽象方法试图通过在生成的摘要中包含要记录的代码组件中不存在的信息来克服这一限制。在这些技术中,使用深度学习(DL)为给定的代码片段生成自然语言描述的技术正在崛起,并且这些技术尝试在给定代码更改的情况下自动更新注释。
尽管DL技术在解决代码注释生成问题方面带来了实质性的改进,但最近的实证研究结果表明,这些技术对于软件开发人员来说仍然不是有用的工具。
代码注释完成问题首先由Ciurumelea等人在Python代码上下文中解决:他们研究深度学习模型是否可以预测开发人员在注释代码时可能键入的下一个单词。据我们所知,这是在这一领域所做的唯一工作。基于他们的想法,我们在本文中提出了一个大规模的研究,评估一个简单的n-gram模型和最近提出的文本到文本转换变压器(T5)架构在支持Java程序的代码注释完成方面的能力。与Ciurumelea等的工作相比,除了关注不同的上下文(即Python vs Java)之外,我们还做了如下工作:(i)研究基于dl的模型(T5)比简单的n-gram模型的实际优势,可以在T5所需的时间内训练;(ii)不要将我们的研究限制在预测开发人员可能输入的下一个单词,而是评估当被要求预测更长的单词序列(例如,接下来的10个单词)时所调查的技术表现如何,为开发人员提供更高级的完成支持。我们还研究了这两种技术的互补性,并报告了正确和错误预测的定性例子,以了解它们的优势和局限性。
我们的研究是在一个由497,328个Java方法及其相关注释组成的数据集上运行的。所获得的结果总结如下。首先,T5模型优于n-gram模型,在我们测试的所有注释完成场景中都取得了优越的性能。其次,尽管T5模型的性能更好,但它不仅利用了开发人员已经编写的注释的第一部分(也被n-gram模型使用),而且还利用了表示注释完成的相关代码的上下文。这意味着,正如我们测试的T5模型,只能在代码已经实现后开发人员编写注释时使用(由自动化代码文档的方法所做的假设)。因此,n-gram模型的适用性更高(也就是说,当代码还没有实现时,也可以使用它)。
2 模型介绍
Raffel等人引入了T5模型,以支持自然语言处理(NLP)中的多任务学习。其想法是以统一的文本到文本格式重新构造NLP任务,其中输入和输出总是文本字符串。例如,可以训练一个单一的模型来跨语言翻译和自动完成句子。T5的训练分为两个阶段:预训练,它允许定义一个共享的知识库,用于大量的序列到序列任务(例如,猜测英语单词来学习语言),以及微调,专门针对特定的下游任务(例如,学习句子从英语到德语的翻译)。我们简要概述了T5模型,并解释了我们如何调整它来支持代码注释完成。
A.T5概述
T5是基于变压器模型架构的,它允许使用自我注意层的堆栈来处理可变大小的输入。当提供输入序列时,它被映射到一个传递到编码器的嵌入序列中。Raffel等人提出了T5的五种变体:小、基础、大、30亿和110亿。这些变体在架构复杂性方面有所不同,较小的模型有60M的参数,而最大的模型有11B的参数。与不那么复杂的模型相比,最复杂变量的精度更高,但训练复杂度随着参数的增加而增加。考虑到我们的计算资源,我们决定使用最简单的T5模型,因此,我们期望所获得的结果是基于t5的模型在代码注释完成任务中的性能的下限。
T5小型架构的特点是编码器和解码器的6个块。每个区块中的前馈网络由一个输出维数为2,048的密集层组成。所有注意机制的关键矩阵和值矩阵的内部维数为64,所有注意机制都有8个头。所有其他的子层和嵌入的维数都为512。
B.问题定义
我们将T5实例化到Java中的代码注释完成问题。我们在方法级粒度上解决这个问题,这意味着我们希望模型学习如何自动完成用于记录一个方法或方法的一部分的代码注释。在Java中,可以使用Javadoc注释或内部注释来记录一个方法。每个注释都与一个特定的上下文相关。
给定一个上下文和一个不完整的注释,训练过的模型必须预测完成注释所需的令牌。这意味着我们必须构建一个训练数据集,其中代码注释链接到文档的代码的相关部分(即上下文)。我们通过在注释中随机掩蔽令牌来预训练T5,要求模型猜测被掩蔽的令牌。这建立了共享的知识,然后我们专门从事两个微调任务,即内部注释任务和Javadoc任务,包括分别预测内部注释和Javadoc注释的缺失部分。
C.数据集准备
我们从代码搜索网数据集开始,提供来自开源项目的6M个函数。我们只关注由约1.5M个方法组成的Java子集。我们使用文档字符串(即方法的Javadoc)和函数字段来提取实例集。然后,我们运行一个预处理,旨在准备我们的数据集。
3 实验评估
本研究的目的是实验T5模型和n-gram模型是否可以通过支持代码注释完成来帮助开发人员更快地编写注释。
特别是,我们回答了以下研究问题:在多大程度上可以利用T5和n-gram模型来支持代码注释的自动完成?
我们使用209,222个测试集实例作为我们的研究背景来回答这个研究问题。这意味着两个训练过的模型(即T5和n-gram模型)将在相同的测试集实例上运行,以预测代码注释的掩码部分。T5模型已经进行了训练,而在下面我们将解释我们如何实现和训练n-gram模型。我们研究中使用的代码和数据都是公开可获得的。
A. N-Gram模型
n-gram模型可以预测前面n−1个标记之后的单个标记。我们在Python中公开发布了n-gram模型的实现。我们通过使用用于微调T5的相同实例来训练n-gram模型,但是,不使用掩蔽标记。我们对n实验了三个不同的值(即n = 3,n = 5和n = 7)。尽管n-gram模型旨在预测给定的n−1个标记之前的单个标记,但我们为掩蔽多个标记的场景设计了一个公平的比较。
B.评估指标
我们使用6个指标来比较T5模型和5-gram模型:完美的预测、BLEU得分、Levenshtein距离、重叠度量、置信度分析、对预测结果的定性分析。
结果讨论
图1描述了T5和5-gram模型在完美预测、BLEU-A得分和用于预测不同长度(k)的Levenshtein距离方面获得的结果。其他度量标准(例如,BLEU-1到BLEU-4)的结果可以在我们的复制包中找到。图1的中间和底部分别显示了Javadoc任务和内部注释任务的结果,而顶部汇总了两个数据集的结果。

图1:T5模型对5-gram模型的性能
在评估任务(即Javadoc任务和内部注释任务)以及总体上,T5在我们研究中考虑的所有指标上都显著优于5-gram模型。当这两个模型需要在开发人员已经在代码注释中编写过一些标记之后再预测有限数量的标记(k≤6)时,这一点尤其正确。例如,当只需要预测后续的单词(即k = 1)时,T5可以在Javadoc任务中实现50%以上的完美预测,在内部注释任务中实现25%以上的完美预测。在这两种情况下,5-gram的模型都只能达到不到16%的完美预测。
Javadoc任务的性能差异尤其显著,相比内部注释任务,T5模型在Javadoc任务中获得了更好的结果。这样的发现可能是由于两个重要的因素。首先,用于Javadoc任务的微调数据集比用于内部注释任务的数据集大,因此可能为模型提供更多关于Javadoc注释中开发人员通常采用的词汇表的知识,以及更多关于这个特定任务的知识。其次,Javadoc具有一种更规则的结构,利用标签(例如,@param),可以帮助模型更好地预测注释,特别是考虑到T5模型在预测过程中利用了相关的代码上下文。尽管如此,即使在内部注释任务中,预测多达7个标记时,T5模型在完美预测方面超出5-gram模型3倍多(图1的左下角)。
当需要预测的标记数量增加时,两种方法之间的性能差距就会更小。在最复杂的场景中,模型预测超过10个标记,T5总体上实现了13%的完美预测,而不是5-gram模型的3%。
内部评论任务的差异较小,最好的方法(T5)也只能达到1%的完美预测。
McNemar的检验总是表明T5和5-gram模型在完美预测方面存在显著差异,内注释任务的ORs为8.04,Javadoc任务的ORs为17.56(整个数据集的OR为16.79)。我们采用的其他评价指标,即BELU-A和Levenshtein距离,证实了T5的性能较好。T5和5-gram在BLEU-A上的差距达到了5倍,证实了两种模型在性能上的显著差异。在Javadoc任务中,T5的BLEU-A分数总是高于5-gram至少约16%,这与两个模型被要求预测的令牌数量无关。正如已经在完美预测中观察到的那样,在内部注释任务中,BLEU-A的差距要小得多,但是仍然显示T5支持多达6个令牌。性能上的差异往往会减少,而要预测的标记数量也会减少。
通过关注Levenshtein距离(图1右侧,越低越好),我们可以观察到,正如预期的那样,当预测到更多的标记时,将预测转换为参考模型所需的标记级编辑数量都趋于增加。对这两个任务(即Javadoc任务和内部注释任务)的分析指出,T5需要开发人员干预的情况数量低于5-gram。然而,一个明确的结论可以通过看图1右边的三个图:当两个模型不能生成一个完美的预测,开发人员将预测转换为他们真正想要写的注释所需要的努力可能太高了。例如,当预测开发人员可能输入的下5个令牌时,T5平均需要更改到预测标记的3.2个。
在T5和5-gram之间的比较中要讨论的一个重要点是用于它们训练的不同数据集。事实上,T5受益于一个训练前阶段,在这个阶段中,它利用了训练期间5-gram没有提供的额外代码。因此,我们对T5模型进行了消融研究,去除其训练前步骤,并检查其在多大程度上是由于训练前的优越表现。虽然细节可以在我们的复制包中找到,但我们可以总结我们的发现如下:训练前阶段提高T5的完美预测范围从~0.5%到~2%,这取决于任务和k值。因此,虽然预训练是有益的,T5的性能仍然优于5-gram模型,即使两种模型都只在微调数据集上进行训练。
表1报告了我们计算的重叠指标的结果。对于Javadoc任务,只有17.06%的完美(即正确)预测由两个模型共享,而75.87%仅由T5模型正确生成。5-gram负责其余7.07%的完美预测,这些预测被T5忽略了。这表明,至少对于Javadoc任务,模型之间存在有限的(但存在的)互补性。对于内部评论任务,也得到了类似的结果。这两个模型共享19.70%的完美预测,其中67.78%的模型仅被T5正确预测。5-gram模型贡献了剩余的12.52%,再次显示出模型之间的一些互补性。
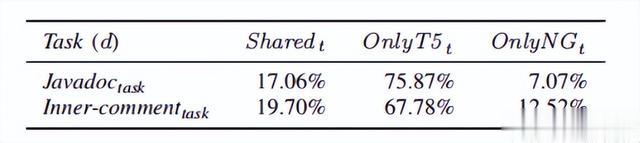
表1:T5和5-gram之间的完美预测重叠
图2显示了POS分析(即每种POS类型的正确预测百分比),证实了T5在所有被调查的POS类别中的优越性:独立于预测的单词类型,T5优于5-gram模型。此外,正如预期的那样,Javadoc任务的表现更优越。不出所料,决定者是正确预测百分比最高的人。然而,像名词、形容词和动词这样的词型类型,虽然预测起来更具挑战性,但仍然表现出很好的正确预测。这个分析,结合之前显示模型在不同k值下的性能的分析,表明两个模型(特别是T5)获得的完美预测不仅是简单的涉及单一的POS类型的单字(k = 1)预测结果,还包括更具挑战性的预测场景。

图2:词性标签分析:ADJ=形容词、ADV=副词、DET=决定词、PRN=代词、OTH=等,包括连词、数字、粒子、加词和X,其中X是不能被指定为词性类别的词
请注意,对于第一个问题,5-gram不会产生任何可能的预测,因为作为输入提供的4-gram在训练集中从未遇到过。相反,T5正确地猜测了我们掩盖的14个注释中随后的12个标记(因此,当考虑k=12时,这是一个完美的预测)。第三个定性的例子是一个由这两种技术都失败了的预测,由T5模型生成的注释更类似于参考模型。最后,底部的两个预测代表了5-gram模型正确地完成了注释,而T5注释失败的情况。在这种情况下,两个例子中的第一个来自Javadoc任务,而第二个表示内部注释任务。
总体而言,我们的定量分析显示了T5模型在代码注释完成任务中的优越性。然而,需要提到的是,T5模型在预测过程中利用了我们提供的作为输入的上下文(即,可能与特定注释相关的代码)。这意味着,从实际的角度来看,只有假设开发人员首先编写代码,然后编写注释,才可以利用这样的模型来完成代码注释。显然,情况并非总是如此,并限制了我们所实验的T5模型的适用性。这样的问题在n-gram模型中不存在,只要在触发第n个标记的预测之前,只要存在n−1个标记,就可以应用。集成到IDE中以支持代码注释完成的工具可以利用这两种模型:如果不能为正在编写的注释捕获上下文,则可以触发n-gram模型,而T5可以在存在相关代码时执行预测。
图3描述了T5(红线)和5-gram(橙色)模型的完美(连续线)和错误(虚线)预测的平均置信水平。可以看出,这两种模型的置信度都能很好地反映出预测的质量。对于t5尤其如此,我们可以看到,正确的预测对所有k值的置信度都大于0.5,而当k增加时,错误的预测的置信度接近0.0。因此,可以在IDE工具中使用一个基于置信度的阈值,以避免推荐可能是错误的预测。

图3:根据令牌长度预测的置信水平
最后,与代码注释生成的任务相比(即,给定一个代码作为输入,从头开始生成注释),在完美预测方面实现的性能要高得多。事实上,当观察一个类似的模型(T5)在Javadoc生成的背景下实验时,它实现了~10%的完美预测。图1中的结果显示,根据Javadoc任务上的预测长度,对于代码注释完成,相同的模型可以实现~16-55%的完美预测。因此,对于这样一个(更简单的)问题,开发可以支持开发人员日常编码活动的工具可能更可行。
转述人:张雅欣