在当代科技进步的浪潮中,人工智能正在成为推动行业变革的关键力量。作为AI技术的核心组成部分,大模型的应用范围持续扩大,已经渗透到了生活的各个领域和工作的关键环节,进一步促进了智能制造、医疗健康、智能交通等多个新行业的诞生与发展。不过,国际政治经济形势的变化,特别是针对高端人工智能芯片的出口限制和技术封锁,对国产显卡的国际化进程造成了阻碍。

由于大模型需要大量的计算资源来运行,而又当美国加强对这类芯片的出口管控时,国内计算资源明显不足,这种资源的短缺就如同施加了一种无形的限制,从而影响了模型性能的表现,降低了用户体验,进而对产业的发展形成了显著的制约。这一情况让许多企业在人工智能的研究道路上面临挑战。
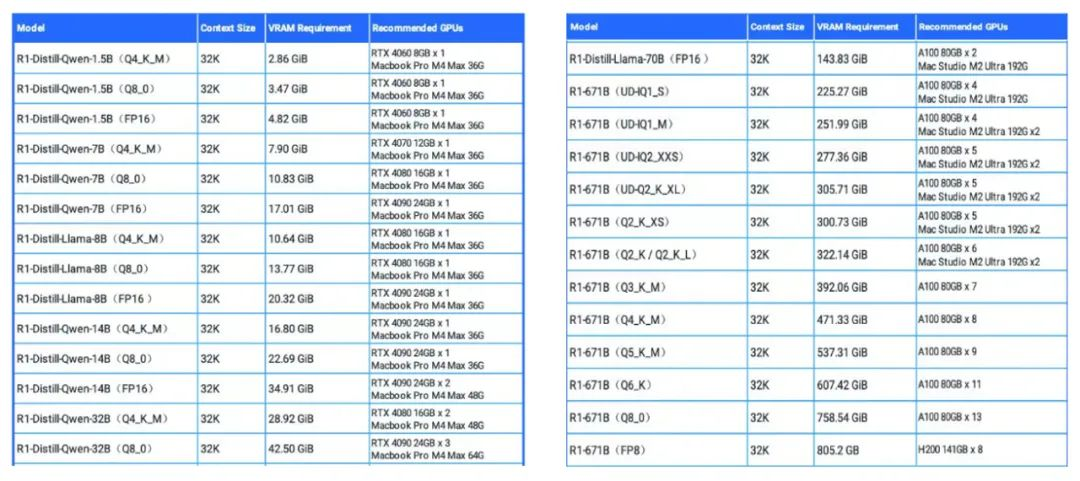
虽在发展上受限,但国内多家优秀的公司还是拿出了自己的代表作, 包括昆仑芯, 寒武纪, 壁仞, 华为, 燧原, 算能, 天数智芯, 瀚博半导体, 墨芯等, 以下表格为相关芯片产品数据, 数据主要是包括算力和显存, 其他还包括芯片型号, 制程, 尺寸, 任务类型等。
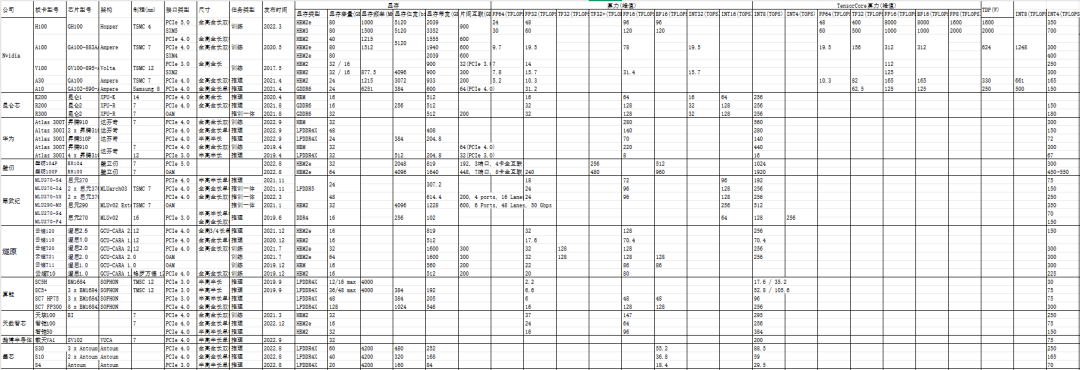
(数据来源:国产AI加速卡性能数据)
虽当前国产卡在推理能力和速度方面虽然取得了一定的进展,但相较于国际先进水平,但仍存在许多局限,如推理精度不足、吞吐量限制、并行处理能力不足、能效比不高、显存宽带瓶颈及硬件加速单位的限制等都限制着国内卡的推理速度。尤其对于满血版大模型来说推理速度更加局限,其中的原因也是多方面的,涉及到设计、制造、优化、市场定位等多个层面。
不过,现在有了新的解决方案 ——Lag [i]一款能解决国内算力难题而研发的大模型好助手。企业在大模型应用上普遍面临的问题是较高的AI技术门槛和算力门槛。因而在大模型研发厂商和企业之间构建一条跨越鸿沟的桥梁,这个桥梁就是大模型中间件Lag [i]。
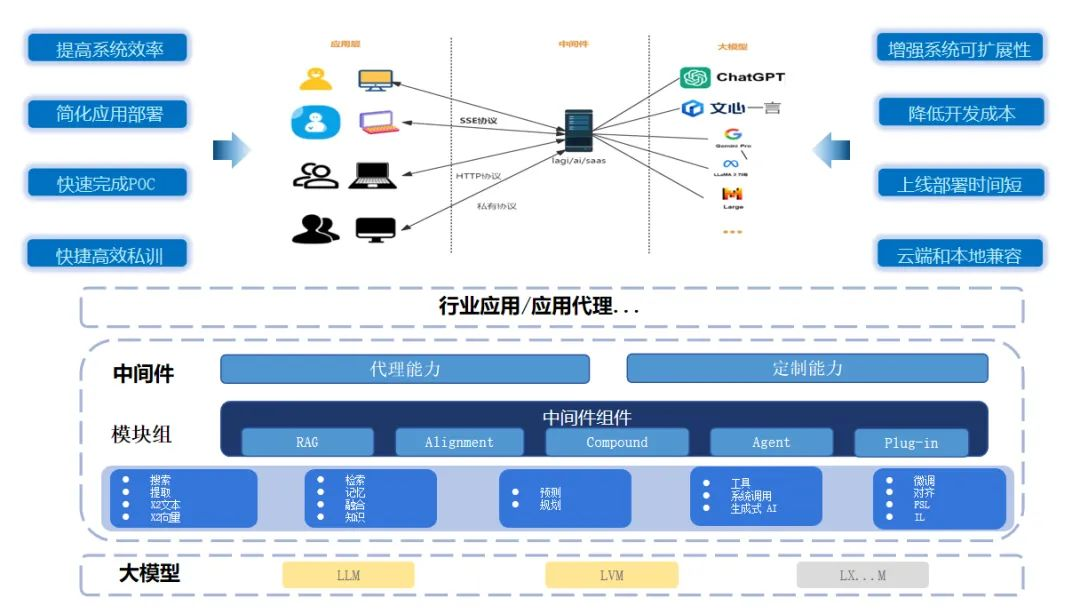
Lag[i]中间件是一款真正为开发者着想的便捷产品。我们希望即使是初学者,也能通过Lag[i]中间件快速上手,开发出适应性强的应用。Lag[i]中间件以业务落地为核心,还拥有更快、更准、更强、更稳、更易的特点。Lag[i]不仅使科研和开发环境更加智能化、自动化和简单化,更能在各种商业和生产环境中发挥简单高效又灵活的作用。

Lag [i] 中间件创新性地引入了Medusa 技术,该技术具备卓越的数据提前加载能力,可大幅削减等待时长。这一突出优势,对于需要处理大规模数据集以及执行复杂计算任务的大模型而言,意义非凡。在其加持下,Lag [i] 中间件得以更充分、高效地调配计算资源,全方位提升模型性能,为开发流程注入强大动力,显著加快开发效率。

特别值得一提的是,Lag [i] 凭借预读缓存加速机制,在融入 Medusa(美杜莎)技术之后,更是将等待时间压缩到极致。其核心思想主要体现在以下方面:
智能缓存,即问即答
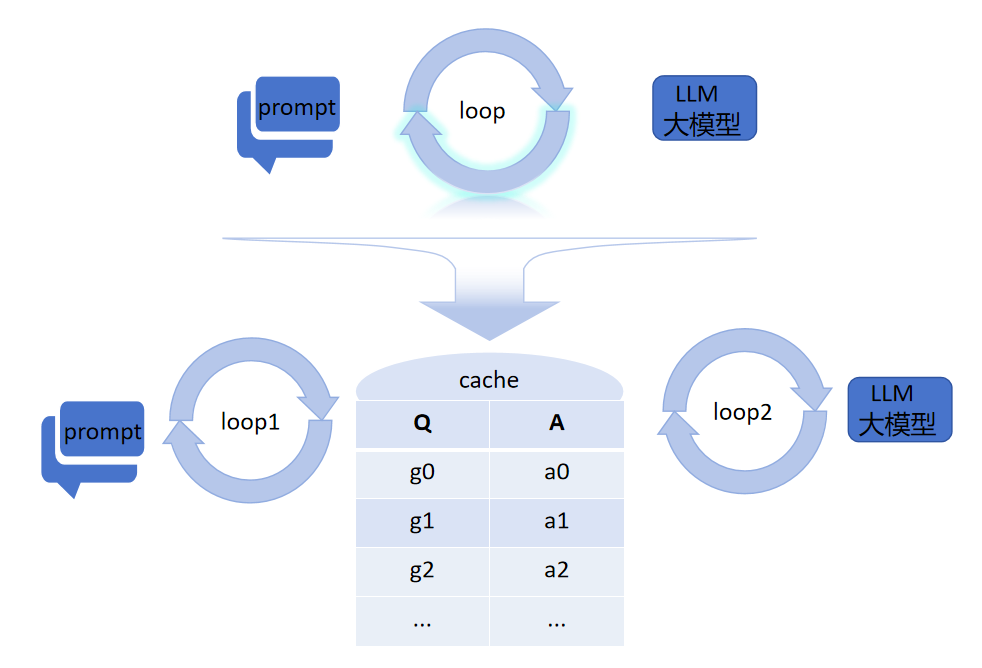
大模型中间件Lag [i]调用大模型时,它会智能地分析数据流向和计算需求。对于频繁调用且相对固定的问题,Lag [i]会将其缓存起来。下次再有相同或相似的请求时,Lag [i]无需重新调用大模型进行复杂生成式处理,而是直接从缓存中快速提取结果,大大减少了计算时间和对显卡算力的依赖。
精妙解耦,各司其职
Lag [i]对人机交互和机模交互进行了巧妙的分离。人机交互时,只需从缓存 中获取数据,就像从自家的小仓库里拿东西一样方便快捷;而缓存的数据来源则是大模型,这就如同小仓库的货物是从大工厂补充进来的。这种解耦方式,使得人机交互不再直接依赖大模型的实时运算,避免了大模型在高并发交互时的压力过载,让交互过程更加流畅,各司其职,协同高效。
异步处理,后台加速
当你向大模型提问时,Lag [i]的异步机制开始发挥神奇作用。提示词的答案直接从缓存中获取,而缓存的数据填充工作,则由其他进程或线程在后台默默进行。它们异步地访问大模型,将新的答案源源不断地存入缓存。这就像你点外卖,不用一直等着厨房做菜,先吃着冰箱里已有的零食,同时外卖在配送途中,等你吃完零食,外卖也刚好送达,丝毫不会让你饿肚子,让大模型在不影响当前交互的前提下,持续更新和优化缓存内容。

前瞻预读,未雨绸缪
为了进一步提升效率和命中率,Lag [i]还具备了预读能力。当遇到问题时,它会像一个聪明的预言家,提前预测相关的提示词以及后续可能的连续问话。然后,直接调用大模型将这些可能用到的答案准备好,放入缓存中。这样,当后续真的问到这些问题时,答案就可以从缓存中直接返回,仿佛提前知晓你的心思,一切都已准备就绪,大大提高了交互的连贯性和效率。
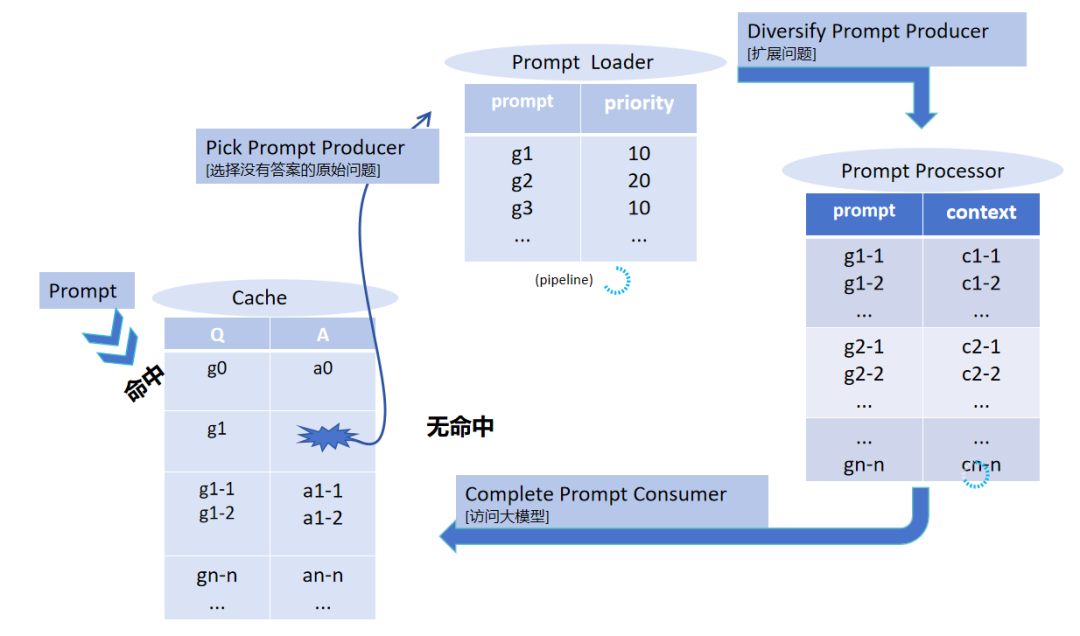
并发拓展,丰富缓存
从一个问题出发,可能有多种方法生成预判预读的提示词。Lagi会将这些方法并行使用,如同多管齐下,全面撒网。通过这种并发的方式,确保预读的提示词足够丰富多样,从而使缓存中的内容更加充实。缓存内容丰富了,在后续问答过程中,就更容易命中问题,为用户提供准确的答案,让大模型的表现更加出色。
Lag [i]究竟怎么使用呢?
您只需要开放本地部署的模型端口或去官网申请一个key就可以实现多模型自由调用。
然后通过以下流程进行部署使用:
安装配置向量数据库→开放本地部署的模型访问地址或申请API密钥→填入配置文件并启用该模型→启用该模型并设置优先级和输出形式→完成即可打开页面正常访问了!
以下是启用后的首页界面:
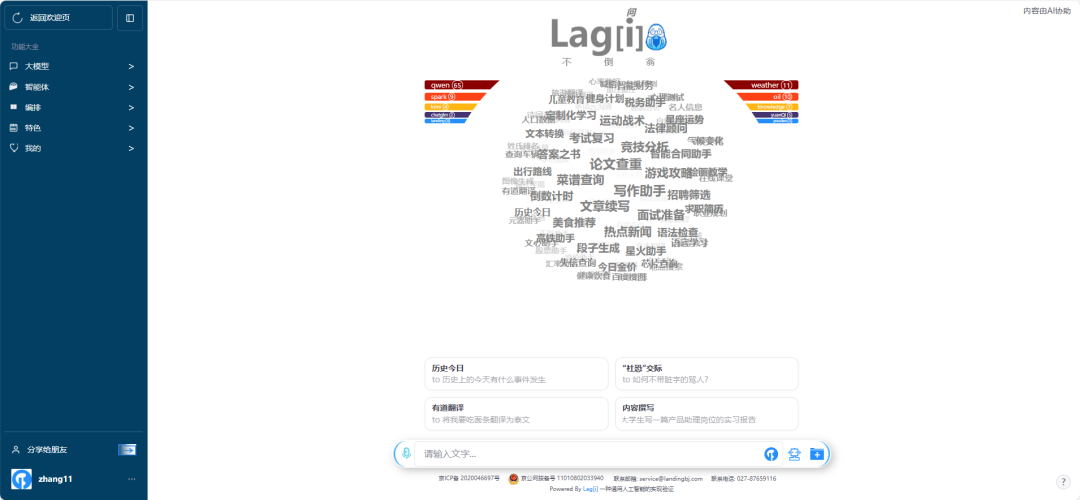
下面我们来介绍一下美杜莎(Medusa)加速器的使用与配置吧!
美杜莎加速器是中间件中的关键组件,它通过优化计算资源分配和算法执行流程,显著提高了数据处理速度。在处理大规模数据集时,这种加速效果尤为明显,能够在短时间内完成复杂的数据分析和预测任务,可以应用于各种架构的大模型。
而我们的大模型中间件Lag [i]已为您接入完毕,您只需要修改lagi.yml文件,将medusa的enable修改为true即可无缝地集成到现有 LLM 系统中。

Lag [i]的预读缓存加速,在引入Medusa(美杜莎)后,将大大减少等待时间,其中实时加速引擎后能够提供实质性帮助包括:
·提高处理速度:通过硬件加速和优化算法,实时加速引擎显著提高了数据处理速度。
·降低延迟:在需要快速响应的应用中,实时加速引擎减少了处理时间,从而降低了系统延迟。
·提升能效比:相比传统的CPU处理,加速引擎通常具有更高的能效比,减少了能耗。
·增强系统性能:实时加速引擎可以释放CPU资源,让系统可以处理更多任务或更复杂的计算。
·优化用户体验:在用户交互密集的应用中,实时加速引擎提供了更快的响应时间和更流畅的体验。
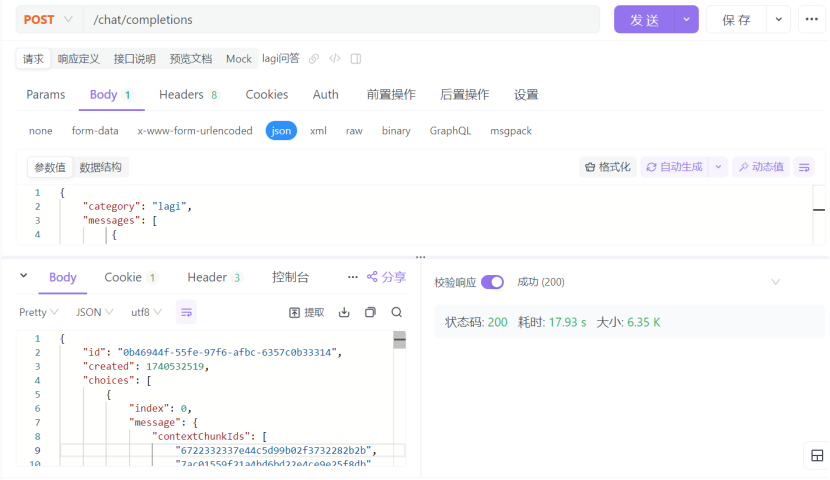
以下是开启Medusa(美杜莎)之前和开启之后的对比图
开启前
调用耗时:17.93s,返回数据为6.35k
开启后
调用耗时:53ms,返回数据为6.66k
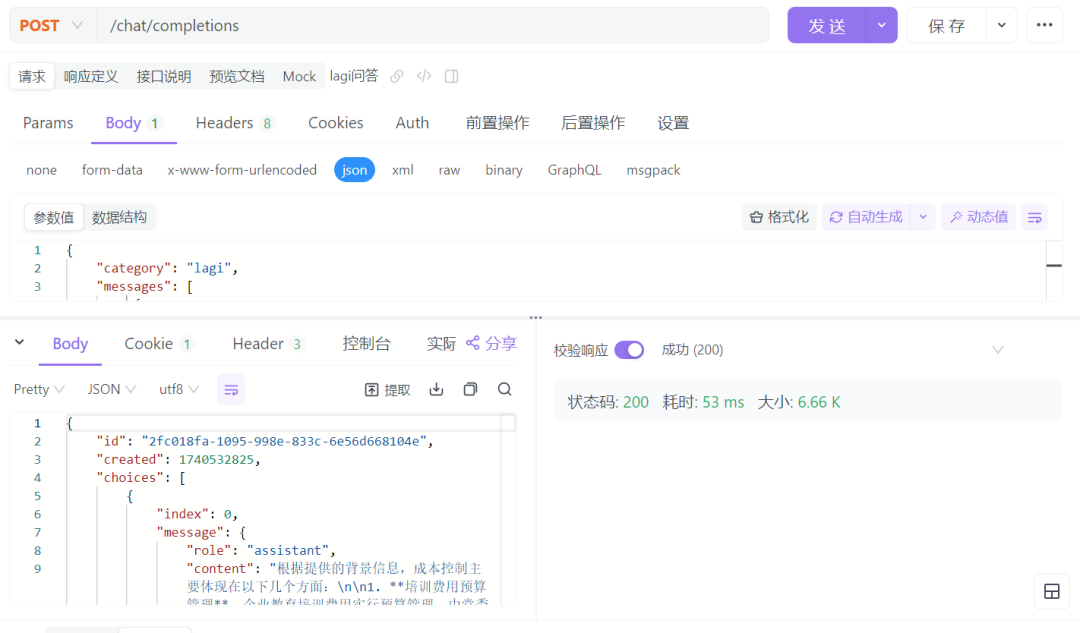
对比上述运行图,效果一目了然:开启 Medusa(美杜莎)后,运行速度一跃迈入毫秒级。在命中特定情况时,速度更是呈爆发式增长,瞬间提升达 338 倍之多。以 100 个问题的处理为例,命中率为60%整体提速幅度稳定保持在 4 至 5 倍区间。这也表明通过其创新的技术和设计,为大型语言模型的生成提供了显著的速度提升和性能优化,同时也具备高度的实用性和易用性。总之,实时加速引擎通过其高效的计算能力,为各种实时数据处理需求提供了强大的支持,对于提升系统性能和用户体验起到了关键作用。
人工智能产业要想实现稳健发展,就必须要注重满足市场的真实需求,通过Medusa(美杜莎)的引入构建起了一个强大的大模型加速体系,将有效解决国内算力有限带来的大模型运行不畅问题。它就像一位贴心的伙伴,为大模型的高效运行保驾护航,让我们在人工智能的探索之路上能够更加顺畅地前行。
结语
Lag [i],以其革命性的缓存加速技术以及对国产显卡的深度适配与优化,为我国计算力瓶颈下的大模型应用带来了一剂强效解药。它不仅确保了大模型在受限算力环境中依然能高效运转,更促进了国产显卡在人工智能领域的深度融入与广泛应用。此刻,正是变革的时刻!如果您也正为算力短缺导致的大模型运行不畅而感到困扰,不妨立即体验Lag [i]的卓越性能。点击下方链接,深入了解Lag [i]的无限可能,踏上高效大模型应用的新征程。让我们携手突破算力限制,乘着人工智能的浪潮扬帆远航,共同开创更加辉煌的未来!
联动中间件项目已开源。
地址:
https://github.com/landingbj/lagi

社会犹如一条船,每个人都要有掌舵的准备。
——易卜生