相信许多玩家会发现很多机器硬件参数亮眼,但实际到手后,从开箱到真正跑起业务,中间往往隔着漫长的环境配置过程。但技嘉这台AI TOP ATOM带来的变化比较直接:它把本地大模型落地这件事,从需要大量手动调试的状态,推进到了开箱即用的阶段。核心原因在于,技嘉将趋境科技的AMaaS平台做了深度整合,硬件与软件之间的衔接环节,出厂前已经完成。

AI TOP ATOM搭载的是NVIDIA GB10 Grace Blackwell芯片,CPU和GPU封装在一起,x86架构里那种CPU先读数据再喂给GPU的流程被彻底砍掉。官方给出的AI算力为1 PFLOPS,即每秒一千万亿次,配合128GB的统一内存,显存和内存不再割裂。跑70B参数模型或者LoRA微调,显存被撑爆这种事基本不会发生。本地跑大模型踩过坑的都清楚,很多时候拦路的不是算力顶不上去,是显存先扛不住。ATOM这套配置直接把数据中心级的显存带宽和容量塞进桌面机箱,千亿参数模型推理随便接,轻量级全参微调也能稳住不崩。

硬件配置只是一方面,真正让这台机器与市面上其他高性能AI主机形成区隔的,是AMaaS平台的本地化落地。之前搞AI工作站,开箱第一周基本在跟驱动、环境、CUDA版本较劲,等到真正能跑模型,第二周都快过完了。技嘉跟趋境科技这次直接把AMaaS平台焊进ATOM,那些重复性劳动出厂前就清干净。AMaaS本身就是成熟的模型管理平台,之前更多在数据中心混,现在落地到本地端,模型部署直接切到图形界面操作。部署推理服务不用再手敲命令行,资源调度、模型切换、运行状态监控,全在一个界面里点完。
对那些做RAG和智能体开发的来说,这套组合直接命中痛点。以前本地搭知识库,链路拉得老长:先部署Embedding模型,再搭向量数据库,最后部署LLM做生成,节点一环扣一环,出问题得层层往下扒。现在ATOM加AMaaS,整套流程图形化编排,资源调度透明到一眼能看清每个模型占了多少显存,调试效率直接起飞。
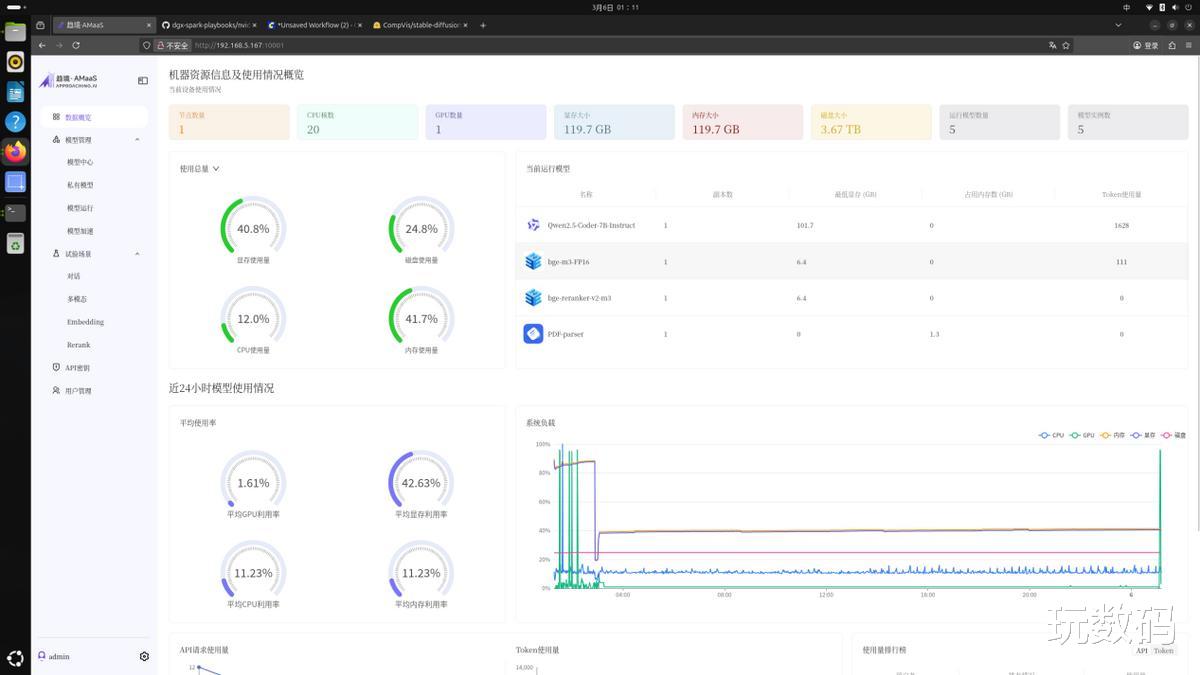
本地大模型落地过程中,真正的难点往往不是能否跑起来,而是跑起来之后如何管理,因此运维层面的改进同样值得关注。模型版本迭代快,业务需求说变就变,今天跑推理,明天要微调,传统模式下运维团队被折腾得够呛。AMaaS直接把资源调度和模型生命周期管理打包标准化,监控、调度、切换全塞进一个界面,终端窗口开一堆盯日志的日子翻篇了。
在本次合作中,趋境科技副总裁关嘉伟也给出了明确的判断:依托技嘉AI TOP ATOM提供的本地算力底子,加上AMaaS平台在模型管理层面的便捷性,双方合力推动大模型部署向低成本、高效率的方向落地,最终让更多个人和企业用户能够快速构建属于自己的本地大模型应用。

单就AI TOP ATOM这台机器而言,它确实是目前市场上少有的、从硬件到软件提前对接好、拿到手即可直接部署业务的设备,对于长期在桌面端跑模型的开发者来说,具备较高的入手价值。技嘉的最终目标也很明确——将大模型应用从少数场景拓展为更多用户日常可用的工具,让更多业务场景能够真正落地并稳定运行。