ArgoCD、KEDA、Crossplane 这些工具并非什么黑魔法,它们的核心都是CRD。一旦你理解了这一点,看待Kubernetes的视角将彻底被改变。

一、你已经用了很多年,却从未真正了解
大多数Kubernetes工程师每天都在使用CRD,但真正理解其原理与设计的人寥寥无几。
打开你的终端,运行以下命令:
kubectl 获取 crds现在暂停一下。
向下滚动。
观察显示了多少行内容。
数百行?
没错,这里有一个扎心的事实:
你用Kubernetes很多年了,却根本不了解它是如何实现自身拓展的。
这些:
Argo CD的ApplicationKEDA的ScaledObjectCrossplane资源cert-manager的Certificate它们本质上都是同一个东西:自定义资源定义(CRD)
二、让你真正 “悟透” K8s的那个瞬间
大多数人以为Kubernetes只是:
Pod部署服务然而,这只是表面现象。
底层的真相是:
Kubernetes不是一个平台,而是一种语言。
那CRD是什么?
CRD让你给这门语言添加新词汇。
好好想想:
你不是在“扩展”Kubernetes,你是在教它新的名词。例如:
DatabaseClusterMLModelTenantConfig一旦定义完成,它们就变成:
一级API对象可通过kubectl查询存储在etcd中采用RBAC进行安全保护像原生资源一样被监控你的构想,就此成为Kubernetes本身的一部分。
为什么这一点能颠覆一切?
大多数教程都忽略了这一点:
CRD不只是一项功能,它是整个云原生生态的基石。
你欣赏的每一款成熟的Kubernetes工具,都构建在它之上。
不是插件,不是黑科技。
仅仅是......一些新的名词而已。
三、从零开始创建一个CRD
我们来创建一个真实的例子:
DatabaseCluster,用于管理PostgreSQL或云数据库的抽象概念。
只需要关注以下3个核心点:
groupnameversionapiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinition
metadata:
name: databaseclusters.infra.example.com # 必须为:<复数>.<组>
spec:
group: infra.example.com # 您的 API 组(例如 apps、batch、networking.k8s.io)
scope: Namespaced # 或者:集群
名称:
复数: databaseclusters # kubectl get databaseclusters
单数: databasecluster # kubectl get databasecluster my-db
kind: DatabaseCluster # 用于 YAML 清单
shortNames:
- dbc # kubectl get dbc
versions:
- name: v1alpha1
serving: true # 此版本处于活动状态并接受请求
storage: true # 此版本用于 etcd 中的持久化
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties: {} # 我们将在下一步中填写
status:
type: object
properties: {}
分析一下其中的关键决策:
这一行代码:
名称: databaseclusters.infra.example.com这不仅仅是一个名字。
这是一个API端点。
Kubernetes刚刚创建了:
/apis/infra.example.com/v1alpha1/databaseclusters无需重启,无需安装插件,无需重建服务器。
你刚刚扩展了Kubernetes API。
范围:命名空间级(Namespaced) VS 集群级 (Cluster)
命名空间:资源位于命名空间内,绝大多数CRD属于此类。集群:全局资源,用于集群级概念,例如 cert-manager 的 ClusterIssuer或基于角色的访问控制 (RBAC)中的ClusterRole。服务(served)VS存储 (storage)
served: true:该版本对外提供API服务。storage: true:该版本数据持久化存储到etcd,有且仅有一个版本可设为storage: true。这种分离是实现安全多版本CRD的关键:可以同时提供v1 和 v1alpha1版本的API服务,但只存一份v1到etcd中。
注意:不做版本控制直接改schema会破坏现有资源。
四、CRD本身不执行任何操作
很多人在这里搞混。
必须明确:CRD只定义意图,不执行任何动作。
它不会:
创建Pod供应数据库扩缩工作负载一句话总结:
CRD = 词汇Operator = 动作如果没有控制器,执行以下命令:
kubectl get dbc只会查到一堆静静躺在那儿的对象。
就这么一直等着,什么也不会发生。
五、构建生产级 DatabaseCluster CRD
让我们使其达到生产级别。
定义:
必填字段校验规则枚举默认值# database-cluster-crd.yamlapiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: databaseclusters.infra.example.com
annotations:
controller-gen.kubebuilder.io/version: v0.14.0
spec:
group: infra.example.com
scope: Namespaced
names:
plural: databaseclusters
singular: databasecluster
kind: DatabaseCluster
shortNames:
- dbc
versions:
- name: v1alpha1
serve: true
storage: true
# 启用状态子资源(对运维人员至关重要)
subresources:
status: {}
# kubectl get dbc 输出中显示的自定义列
additionalPrinterColumns:
- name: Replicas
type: integer
jsonPath: .spec.replicas
- name: Region
type: string
jsonPath: .spec.region
- name: Phase
type: string
jsonPath: .status.phase
- name: Age
type: date
jsonPath: .metadata.creationTimestamp
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
required: [ "engine" , "replicas" , "region" ]
properties:
engine:
type: string
enum: [ "postgres" , "mysql" , "mariadb" ]
description: "要使用的数据库引擎"
replicas:
type: integer
minimum: 1
maximum: 9
description: "数据库副本数"
region:
type: string
description: "AWS 区域或数据中心位置"
storageGB:
type: integer
minimum: 10
default: 20
description: "存储大小(GB)"
version:
type: string
description: "数据库引擎版本(例如,PostgreSQL 的 '16.2')"
status:
type: object
properties:
phase:
type: 字符串
描述: “当前生命周期阶段:待处理、配置中、就绪、失败”
端点:
类型: 字符串
描述: “集群就绪后的连接端点”
条件:
类型: 数组
项:
类型: 对象
属性:
类型:
字符串 状态
:
类型: 字符串
lastTransitionTime:
类型: 字符串
格式: 日期时间
原因:
类型: 字符串
消息:
类型: 字符串
六、为什么Schema至关重要
没有schema:Kubernetes几乎可以接受任何格式。有schema:Kubernetes变成第一道防线。无效的配置根本触及不了Operator。
将其应用到集群:
kubectl apply -f database-cluster-crd.yaml# 验证是否已注册
kubectl get crd databaseclusters.infra.example.com
# 创建于
# databaseclusters.infra.example.com 2026-03-31T16:00:00Z
应用此配置之后,Kubernetes会立即注册新API端点,无需重启。
七、创建第一个自定义资源
现在CRD已经存在,你可以创建它的实例,就像创建任何其他Kubernetes对象一样:
# my-postgres.yamlapiVersion: infra.example.com/v1alpha1
kind: DatabaseCluster
metadata:
name: production-postgres
namespace: databases
spec:
engine: postgres
replicas: 3
region: ap-south-1
version: "16.2"
应用与操作:
kubectl apply -f my -postgres.yaml# 像操作任何原生资源一样操作它
kubectl get dbc -n databases
# NAME REPLICAS REGION PHASE AGE
# production-postgres 3 ap-south-1 <none> 10s
kubectl describe dbc production-postgres -n databases
kubectl delete dbc production-postgres -n databases
你不再只是简单使用Kubernetes,而是在塑造它的API体系。
此时Phase列为 <none>,因为没有控制器更新状态。
注意:仅有CRD而没有控制器,是没有任何作用的。
八、CRD如何融入Kubernetes架构
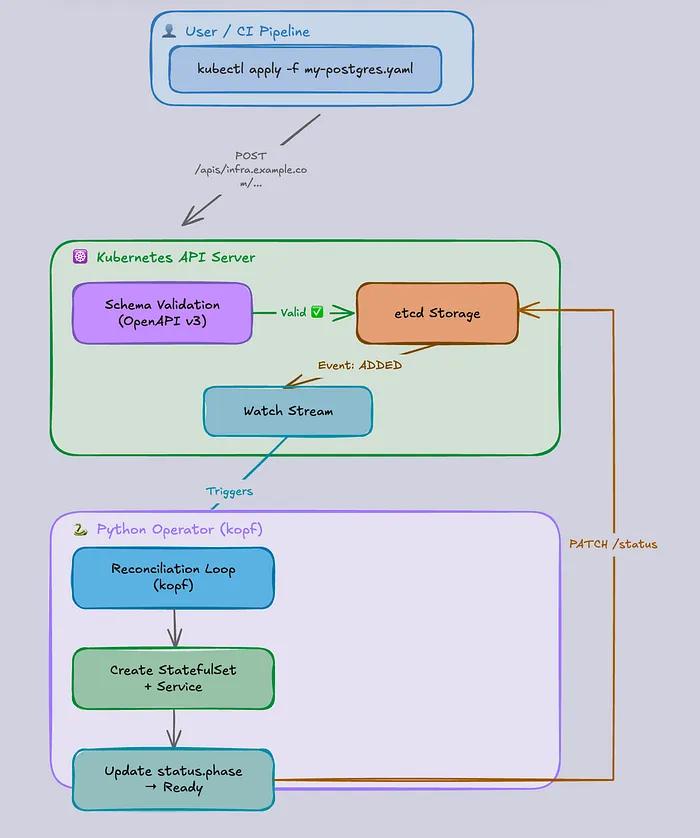
此图展示了CRD在Kubernetes架构中的完整生命周期:
应用DatabaseCluster YAMLAPI server 按 OpenAPI schema 校验存入etcd一个controller监视它controller让实际状态匹配你的期望状态Kubernetes 并非在执行 YAML,它是在调和你的意图。
一旦你理解了这一点……
其它一切:operators、controllers、自动化等等,都变得显而易见了。
九、为什么 status 子资源如此重要
这一点能区分新手与平台工程师。
添加:
subresources:status: {}
现在,神奇的事情发生了。
如果没有它:任何人都能覆盖系统状态有了它:只有Operator能修改实际状态想想看:
spec:用户定义期望状态status:Operator上报真实状态并且Kubernetes在API层强制执行这种分离。
这不是惯例,而是架构层面的强制性规定。
在你的Python operator中,将像这样更新status :
只有操作员才能写入 /status — 用户无法覆盖此设置。patch.status[ 'phase' ] = 'Ready'
patch.status[ 'endpoint' ] = f"postgres. {name} .svc.cluster.local:5432"
status包含两种类型的信息:
1)简单字段(实际是什么?)
这些字段回答:“当前状态是什么?”
2)条件数组(健康状况如何?)
这些条件回答:“一切正常吗?当前情况如何?”
一个condition就像指示每个方面的交通信号灯。
十、通过Python与CRD交互
先来了解如何使用官方kubernetes Python client与自定义资源进行交互。这一方法适用于脚本编写、CI流水线以及数据迁移任务。
# pip install kubernetesfrom kubernetes import client, config
# 加载 kubeconfig(如果运行在 pod 中,则加载集群内配置)
config.load_kube_config()
# 使用动态客户端访问自定义资源
dyn_client = client.ApiClient()
custom_api = client.CustomObjectsApi(dyn_client)
GROUP = "infra.example.com"
VERSION = "v1alpha1"
PLURAL = "databaseclusters"
NAMESPACE = "databases"
# 列出所有 DatabaseCluster 资源
clusters = custom_api.list_namespaced_custom_object(
group=GROUP,
version=VERSION,
namespace=NAMESPACE,
plural=PLURAL
)
for cluster in clusters[ "items" ]:
name = cluster[ "metadata" ][ "name" ]
phase = cluster.get( "status" , {}).get( "phase" , "Unknown" )
replicas = cluster[ "spec" ][ "replicas" ]
print(f "{name}: phase={phase}, replicas={replicas}" )
# 以编程方式创建一个新的数据库集群
new_cluster = {
"apiVersion" : f "{GROUP}/{VERSION}" ,
"kind" : "DatabaseCluster" ,
"metadata" : { "name" : "staging-mysql" , "namespace" : NAMESPACE},
"spec" : {
"engine" : "mysql" ,
"replicas" : 1,
"region" : "ap-south-1" ,
"storageGB" : 20,
"version" : "8.0"
}
}
custom_api.create_namespaced_custom_object(
group=GROUP,
version=VERSION,
namespace=NAMESPACE,
plural=PLURAL,
body=new_cluster
)
print( "已创建 staging-mysql 数据库集群" )
#修补状态
(通常仅由操作员执行)
status_patch = { "status" : { "phase" : "Provisioning" }}
custom_api.patch_namespaced_custom_object_status(
group=GROUP,
version=VERSION,
namespace=NAMESPACE,
plural=PLURAL,
name= "staging-mysql" ,
body=status_patch
)
这是原始的API交互层。
十一、隐藏的仪表盘技巧
添加:
additionalPrinterColumns:现在运行:
kubectl get dbc输出示例:
名称 副本数 区域 阶段 时间production-postgres 3 ap-south-1 就绪 2天
staging-mysql 1 ap-south-1 配置中 5个月
你刚刚把kubectl变成了一个仪表盘。
无需UI和额外工具,考的仅仅只是巧妙的API设计。
十二、导致系统崩溃的常见错误
在构建自己的CRD之前,请避免以下情况:
没有 schema → 会接收无效或错误的输入数据没有 status 子资源 → 用户可覆盖系统状态破坏性修schema 变更 → 破坏现有资源忘记写 Operator → 不会执行任何实际操作大多数CRD问题不是Kubernetes本身的问题,而是API设计问题。
十三、你真正学到了什么
让我们把视角拉远一些。
这篇文章讲的不仅仅是YAML,而是了解Kubernetes的演进方式。
你学到了:
工具的实际构建方式API的扩展方式平台的设计方式更重要的是:
你不再只是Kubernetes用户,而是开始像平台工程师一样思考。
十四、接下来会讲什么
目前,你的CRD仍然存在一个缺陷。
任何人都可以这样操作:
副本数:0而Kubernetes会照单全收。
在API服务器内部运行的验证规则:
不需要webhooks,不需要额外的服务。
仅仅只是靠API层面的强制约束。
十五、最后,还有一个问题
假设你要创建一个系统,让用户可以通过声明式的方式定义数据库备份。他们不用写脚本,而是编写YAML文件即可。
用户想要输入的内容如下:
apiVersion: backup.example.com/v1kind: DatabaseBackup
metadata:
name: my-postgres-daily
spec:
database: "postgres-prod"
schedule: "0 2 * * *" # 每天凌晨 2 点
执行 retention: 7 # 保留 7 个备份
请思考:
1、这里的期望状态(DESIRED state)是什么?(用户表达了哪些需求?)
我希望备份按指定的计划执行我希望保留指定数量的备份还可以补充什么?
2、实际状态(ACTUAL state)是什么?(Operator会在集群中检查哪些信息?)
当前实际存在多少个备份?上一次备份是什么时候?上一次备份是成功还是失败?还有哪些信息值得跟踪?3、还可以增加哪些字段?(用户可能还想指定什么?)
备份存储位置(S3、GCS、本地存储)?备份类型(全量、增量)?成功或者失败通知?其它内容?作者丨Ramesh 编译丨dbaplus社群
来源丨网址:https://medium.com/@rameshavutu/kubernetes-crds-08bb705ed406
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn
活动推荐
5月22日,2026 XCOPS 智能运维管理人年会「广州站」重磅来袭!聚焦大模型迭代、AI Agent 深度应用等技术热点,邀请一众行业领军人物、技术大咖,从技术架构、实战案例到科研成果,与大家一起探索AI应用于智能运维与数据库的最佳方式,共同破解垂类智能体落地、多Agent协同、数据库自治技术工程化、核心系统信创与智能化平衡等现实难题。
点击链接即可报名: