
在医疗信息化浪潮席卷全球的当下,临床数据正以指数级速度增长。这些分散在诊疗全流程中的数据,既是医学研究的 “富矿”,也因格式不一、标准缺失等问题,让科研工作者面临 “采矿无门” 的困境。而科研专病库的出现,正为破解这一难题提供了关键方案。作为医疗大数据时代的核心基础设施,它如何整合多模态数据、赋能临床科研?又将为精准医学发展带来哪些新可能?我们一起深入探讨科研专病库的建设现状与未来方向。
建设科研专病库:政策与临床的双重驱动
科研专病库并非凭空出现,而是政策导向与临床需求共同催生的必然结果。
从政策层面看,国家卫健委在《全国医院信息化建设标准与规范(试行)》中明确提出,要借助大数据、人工智能等技术提升临床科研能力。传统科研模式中,数据碎片化、质量参差不齐的问题长期存在 —— 某家医院的检验数据格式与另一家不同,电子病历中的非结构化文本难以直接调用,这些都严重拖慢了研究进度。而专病库通过标准化的数据治理,能将分散的数据 “拧成一股绳”,从根本上解决数据利用难的痛点,成为响应国家医疗信息化政策的重要实践。
从临床需求出发,专病研究对数据的 “深度” 和 “广度” 有着极高要求。以肿瘤研究为例,不仅需要患者的门诊、住院诊疗记录,还需影像报告、基因测序数据、长期随访结果等全生命周期信息。过去,科研人员往往要花费大量时间从不同系统中手动整理数据,甚至因数据不全导致研究中断。专病库以特定疾病为核心,整合多模态数据,既满足了精准医学研究对 “全景式数据” 的需求,也为个性化治疗方案制定提供了数据支撑,彻底改变了科研数据 “供不应求” 的局面。
技术如何落地?揭秘科研专病库的建设核心
一座高效运转的科研专病库,背后离不开成熟的技术架构与科学的建设策略。上海藤核智能科技有限公司在参与相关项目时,深刻意识到“数据整合 + 质量把控 + 高效采集” 是建设成功的关键三要素。
1
多模态数据整合:打破数据“语言壁垒”
专病库的数据来源极为广泛,既有结构化数据(如检验指标、用药记录),也有非结构化数据(如电子病历文书、影像报告)。为了让这些数据 “互联互通”,我们采用自然语言处理(NLP)技术,将病历中的文本信息转化为可分析的结构化数据;同时借助知识图谱技术,梳理疾病、症状、治疗方案之间的关联,构建标准化的数据体系。
2
数据治理与质控:AI 赋能,守护数据质量
数据质量是专病库的 “生命线”。我们以 OHDSI(数据管理能力成熟度评估模型)等为标准,建立了全流程的数据质量管理机制:从元数据管理(明确数据来源、格式),到术语归一化(统一疾病、药品名称),再到患者主索引、就诊索引的构建,确保每一条数据都 “可追溯、可验证”。
更重要的是,我们引入 AI 大模型优化质控环节 —— 通过算法自动校验数据的完整性(如是否缺失关键检验值)、准确性(如年龄与病史是否匹配),并针对医疗场景设计专属逻辑规则(如术后用药与手术类型是否相符)。相比传统人工质控,AI 不仅有效降低了误差率降,还大幅提升了质控效率,让数据质量更有保障。
3
可视化采集系统:让数据采集省时又省心
临床医生是数据采集的核心参与者,但繁琐的操作往往导致他们参与度不高。为此,我们打造了可视化采集系统,通过两种方式解决这一问题:
◎ 院内数据 “自动采”:通过与医院 HIS、LIS 等系统对接,采用 ETL 技术实现数据实时或 T+N(如 T+1,即次日更新)自动采集,无需人工录入;
◎ 院外随访 “便捷采”:设计自定义表单,医生可根据研究需求灵活调整采集字段,同时借助实时同步技术,将原本需要 30 分钟的数据整理时间缩短至 10 分钟。这一优化让医生的工作效率显著提升,也让随访数据的完整性得到了保障。
专病库有何价值?科研到临床的全方位赋能
经过多年建设实践,科研专病库的应用价值已在多个场景中凸显,成为推动医学发展的 “加速器”。
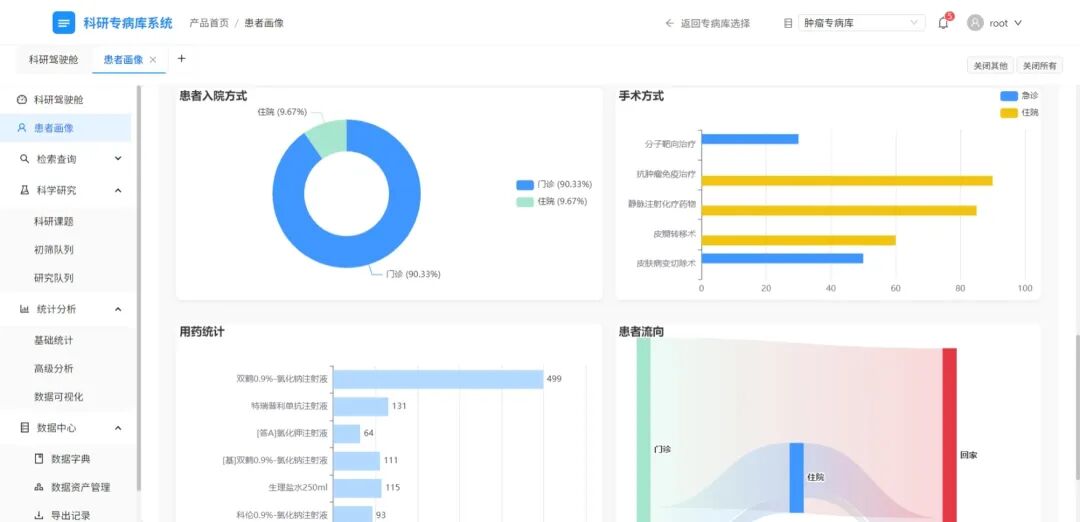
1
提升科研效率,加速成果转化
以往开展多中心研究时,科研人员需要逐个医院对接数据,仅病例筛选就可能花费数月。而专病库的智能病例检索功能,能根据研究需求快速筛选出符合条件的病例,同时支持动态分析—— 比如某团队研究 “某药物对肺癌患者的疗效”,通过专病库可一键调取不同医院的患者数据,自动分析用药后的生存率、不良反应等指标,大幅缩短研究周期。此外,专病库还能实现患者智能招募,为新药研发、临床试验提供精准的受试者群体,加速科研成果从实验室走向临床应用。
2
支撑临床决策,改善患者预后
基于专病库积累的海量真实世界数据,我们可以构建疾病预测模型,基于专病库的预测模型准确率达90%。医生可根据模型结果,为高风险患者制定更密集的随访计划和个性化治疗方案,有效降低复发率,改善患者预后。这种 “数据驱动” 的决策模式,让临床治疗更精准、更科学。
3
推动学科联动,实现 “临床科研一体化”
专病库的建设打破了学科间的 “数据壁垒”。比如糖尿病专病库,不仅整合了内分泌科的诊疗数据,还纳入了眼科(糖尿病视网膜病变)、肾内科(糖尿病肾病)等相关科室的数据。这种跨学科的数据整合,让医生能从更全面的视角研究疾病,推动多学科协作(MDT)模式发展,同时也让临床问题能快速转化为科研课题,科研成果又能反哺临床治疗,形成 “临床 - 科研” 的良性循环。
未来可期:科研专病库的三大发展方向
随着技术的不断进步,科研专病库的建设不会止步于 “数据整合”,而是朝着更智能、更开放、更规范的方向迈进。
1
多中心协作+隐私计算:安全共享数据
目前,多数专病库仍局限于单一医院或区域,数据规模和覆盖面有限。下一代专病库将通过隐私计算技术(如联邦学习、同态加密),在保障患者隐私的前提下,实现跨机构、跨区域的数据共享。比如,北京某医院的肿瘤专病库与上海某医院的同类库,可在不交换原始数据的情况下联合建模,提升模型的泛化能力,让多中心研究真正 “无界”。
2
智能化升级:让数据 “主动说话”
未来的专病库将不再是 “数据仓库”,而是 “智能助手”。我们计划结合 AI 技术,构建动态知识库—— 实时更新国内外最新的诊疗指南、研究成果,并与库内数据关联;同时开发自动化分析工具,比如医生上传患者数据后,系统可自动生成诊疗建议、科研假设,甚至预测疾病进展。这一升级将让数据从 “被动调用” 变为 “主动赋能”,大幅降低科研和临床的工作成本。
3
标准化 + 伦理规范:筑牢发展基石
数据标准不统一,仍是制约专病库发展的重要因素。未来,我们将推动完善数据标准体系,比如统一使用 ICD-10 疾病代码、LOINC 检验项目代码,让不同专病库的数据 “可互通、可对比”。同时,还将建立符合伦理的数据使用机制,明确数据的使用范围、授权流程,确保每一次数据调用都符合法律法规和伦理要求,守护患者的隐私与权益。
以专病库为钥,开启精准医学新未来
科研专病库的建设,是医疗大数据从 “量的积累” 走向 “质的飞跃” 的关键一步。它不仅解决了临床数据利用难的问题,更成为连接临床与科研、推动精准医学发展的核心纽带。
作为深耕医疗信息化领域的企业,上海藤核智能科技有限公司始终致力于以技术创新赋能医疗发展。我们相信,随着多模态数据整合、AI 智能化升级、跨机构安全共享等技术的落地,科研专病库将为健康中国战略提供更坚实的数据支撑,为医学研究开辟新路径,为患者带来更优质的医疗服务。
未来已来,我们共同期待科研专病库解锁更多医疗大数据价值,书写精准医学新篇章!