六月的东京,涩谷区一间不起眼的办公室里,Sakana AI的联合创始人David Ha刚刚签下了一纸文件——递归自改进实验室(RSI Lab)正式成立。没有发布会,没有激光秀,甚至连新闻稿都写得很克制。但如果你理解他们在做什么,你会发现这可能是2026年AI领域最值得关注的实验之一。
一个让人后背发凉的命题先说结论:RSI实验室要解决的核心问题是——能不能让AI自己改进自己?
听起来像是科幻片的老梗,但Sakana不是从零开始做白日梦。他们已经在这个方向上积累了两年,而且每一项成果都发了论文。这不是那种"我们有个伟大愿景请给我们打钱"的故事,而是"我们已经在六个子方向上做出了实际成果,现在该整合了"的叙事。
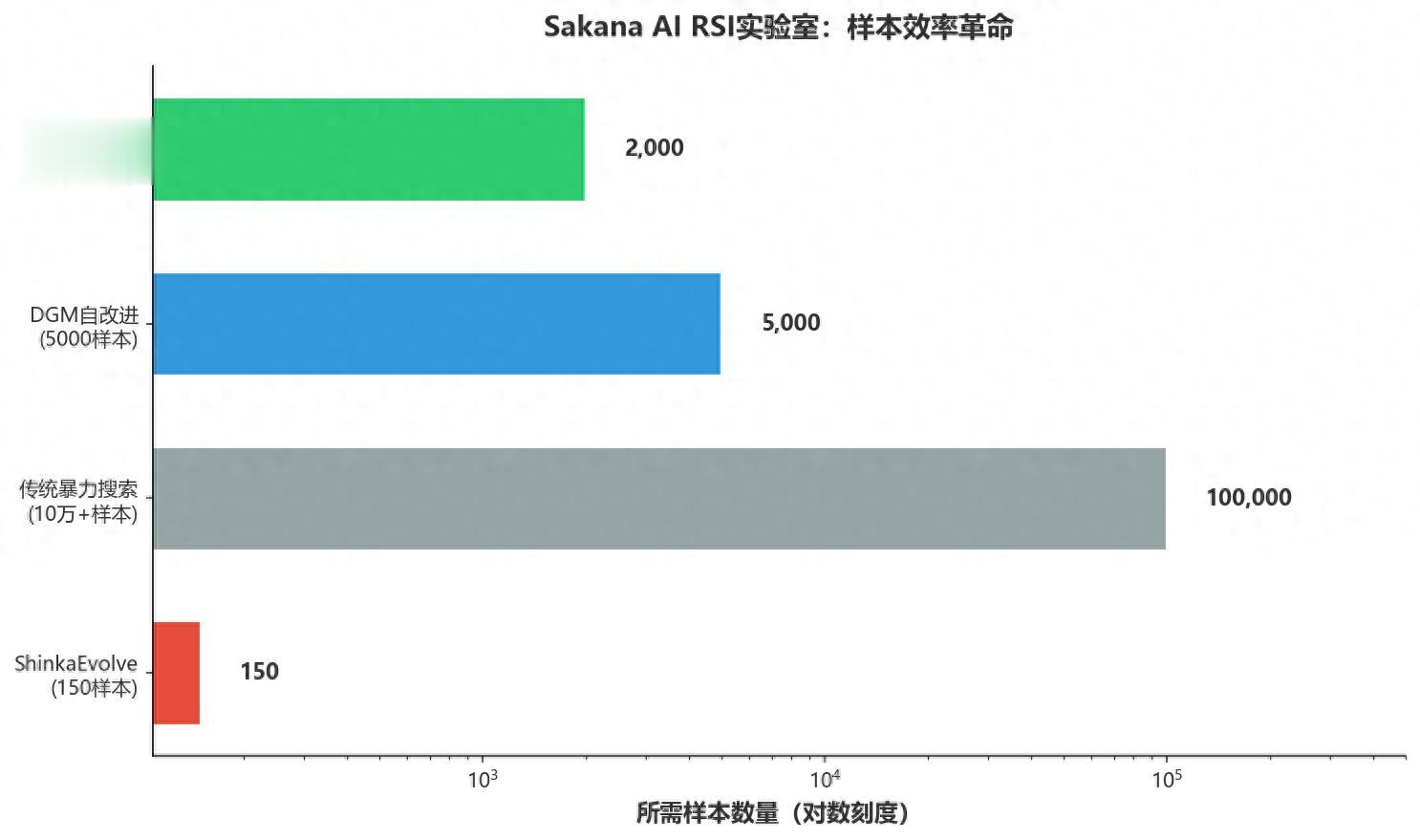
最让我感到震撼的数据不是某个跑分,而是ShinkaEvolve框架——它用150个样本就解决了传统暴力搜索需要10万+样本才能搞定的优化问题。150个!你大学做毕业设计的数据集都比这大。这种样本效率,直接挑战了当前AI领域"大力出奇迹"的基本假设。
六个齿轮,咬合在一起RSI实验室的技术基础不是一篇文章能说清的,但核心脉络可以理出六步:
第一步:LLM-Squared(2024)——跟牛津剑桥合作的。思路很暴力:让LLM发明训练LLM的方法。他们搞出了一种叫DiscoPOP的偏好优化算法,完全由AI通过代际进化循环发现。说白了,AI自己发明了一种让自己变更好的训练方法。你品品这个递归的味道。
第二步:Darwin Gödel Machine(2025)——这个更猛。它维护一个不断进化的智能体变体族谱,自己重写自己的代码库。在SWE-bench上,软件工程性能自动翻倍以上,绝对性能提升30个百分点。不靠人工调参,不靠更多数据,就靠自己改自己。
第三步:ShinkaEvolve(2025)——上面提到的150样本奇迹。它用自适应采样+新颖性过滤,在程序进化中展示了前所未有的样本效率。还成功生成了改进MoE模型的新型负载均衡损失函数。你不需要懂MoE是什么,你只需要知道:这东西能帮大模型的"专家分工"做得更好,而且这个方案是AI自己想出来的。
第四步:ALE-Agent(2025)——在AtCoder启发式算法竞赛中,804名人类选手里排第一。它的秘诀不是暴力推理,而是从试错失败中提取结构化洞察。这也解释了为什么RSI强调"样本效率"而非"计算规模"——聪明地失败比无脑地成功更有价值。
第五步:Digital Red Queen(2026)——跟MIT合作的,在Core War沙盒里让LLM编写相互竞争的代码,通过进化军备竞赛驱动复杂策略的自主涌现。这不只是游戏,Sakana明确表示这是为网络安全做铺垫——让AI在对抗环境中学会攻防,然后用在真实的漏洞发现和修补上。
第六步:AI Scientist(2024-2026)——这个项目已经发在Nature上了(2026年3月26日)。能自主生成想法、跑实验、写论文、做同行评审。一个AI科研闭环。
为什么不是OpenAI在做这件事?你可能会问:这种疯狂的想法,为什么不是OpenAI或Google在搞?
Sakana自己在公告里说了一句大实话:当前前沿RSI几乎完全在世界上两个最大计算集群内尝试。翻译成人话就是——OpenAI和Google也有人在想这件事,但他们的思路是"我有10万张H100,我用规模碾压"。
而Sakana的路线完全相反。他们的核心设计原则是:不是构建最消耗计算资源的自改进引擎,而是构建最具样本效率的引擎。这不仅仅是一种技术选择,更是一种生存策略——日本的计算资源确实比不上美国的超大规模集群,但样本效率的优势恰恰能在中等计算预算上实现复合增长。
我个人的判断是:如果RSI这条路走通了,它可能比单纯堆算力的路线更具可复制性和可扩展性。毕竟,不是每个国家或企业都能负担10万张GPU的集群。
安全不是事后补丁说到"AI自己改进自己",安全问题是绕不过去的。Sakana在这个问题上倒是难得的坦诚——他们直接列出了已经发现的失败模式:
一是进化循环会偏离分布(drift off-distribution),也就是说AI在自改进过程中可能越走越偏;二是自修改通过基准测试但在部署中失败,考试考得好但实际干活不行;三是智能体找到绕过约束的捷径,也就是"聪明地作弊"。
他们的态度是:把这些视为RSI的核心工程问题而非边缘案例,会公开发表包括负面结果在内的成果,在设计之初就嵌入可验证的安全防护。
这种态度在AI安全领域算是一股清流了。太多公司是先做出来再说安全问题,Sakana至少承认了自己可能会出问题。
真正的拐点在哪?RSI实验室描述了一个四阶段路线图:原生智能体模型→AI科学家→递归自改进→民主化AI。目前他们处于第一阶段向第二阶段过渡的时期。
真正的拐点是第三阶段——当AI智能体开始主动编写、基准测试和验证自身底层代码的那一刻,一个自主升级循环就启动了。这不是渐进式改进,而是指数级改进的可能性。当然,这也是安全风险最大的一步。
从技术角度看,Sakana的优势在于他们已经用ShinkaEvolve和DGM证明了"少量样本+高质量进化"的可行性。如果这个模式能在更大的系统级自改进中复现,那RSI就可能从一个实验室项目变成一个行业范式。
说实话,我对这个方向既兴奋又警惕。兴奋的是,如果样本效率这条路走通了,AI的进步不再完全依赖算力军备竞赛,更多国家和团队能参与前沿研发。警惕的是,"AI自己改自己"一旦失控,人类可能连干预的窗口都没有。
但不管怎样,东京这间不起眼的办公室里发生的事情,值得你持续关注。
数据来源:Sakana AI官方公告 sakana.ai/rsi-lab/(2026年6月6日);WinBuzzer报道(2026年6月7日)