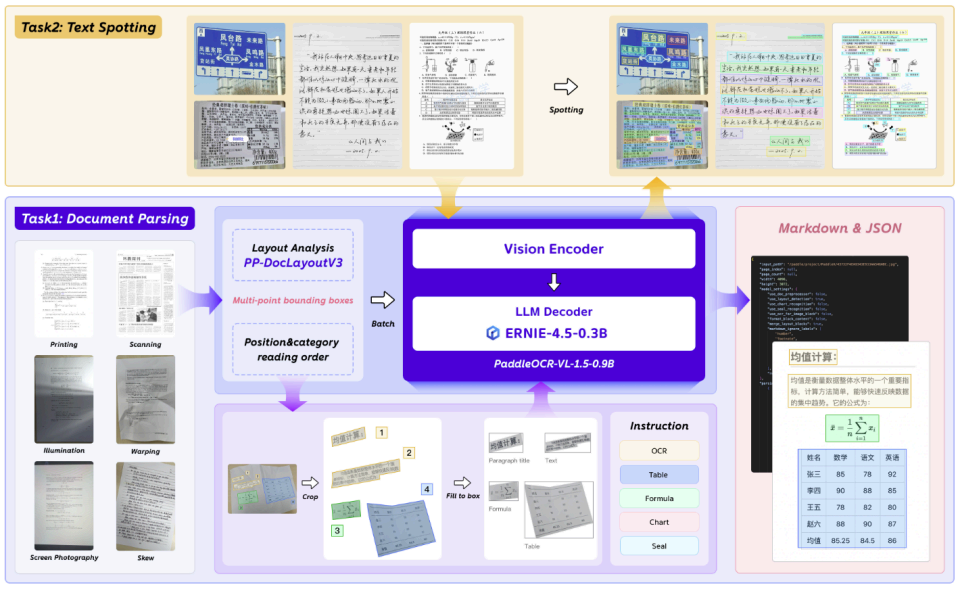
【百度发布的PaddleOCR-VL-1.5:专治“拍歪了”表格再乱也能理清】
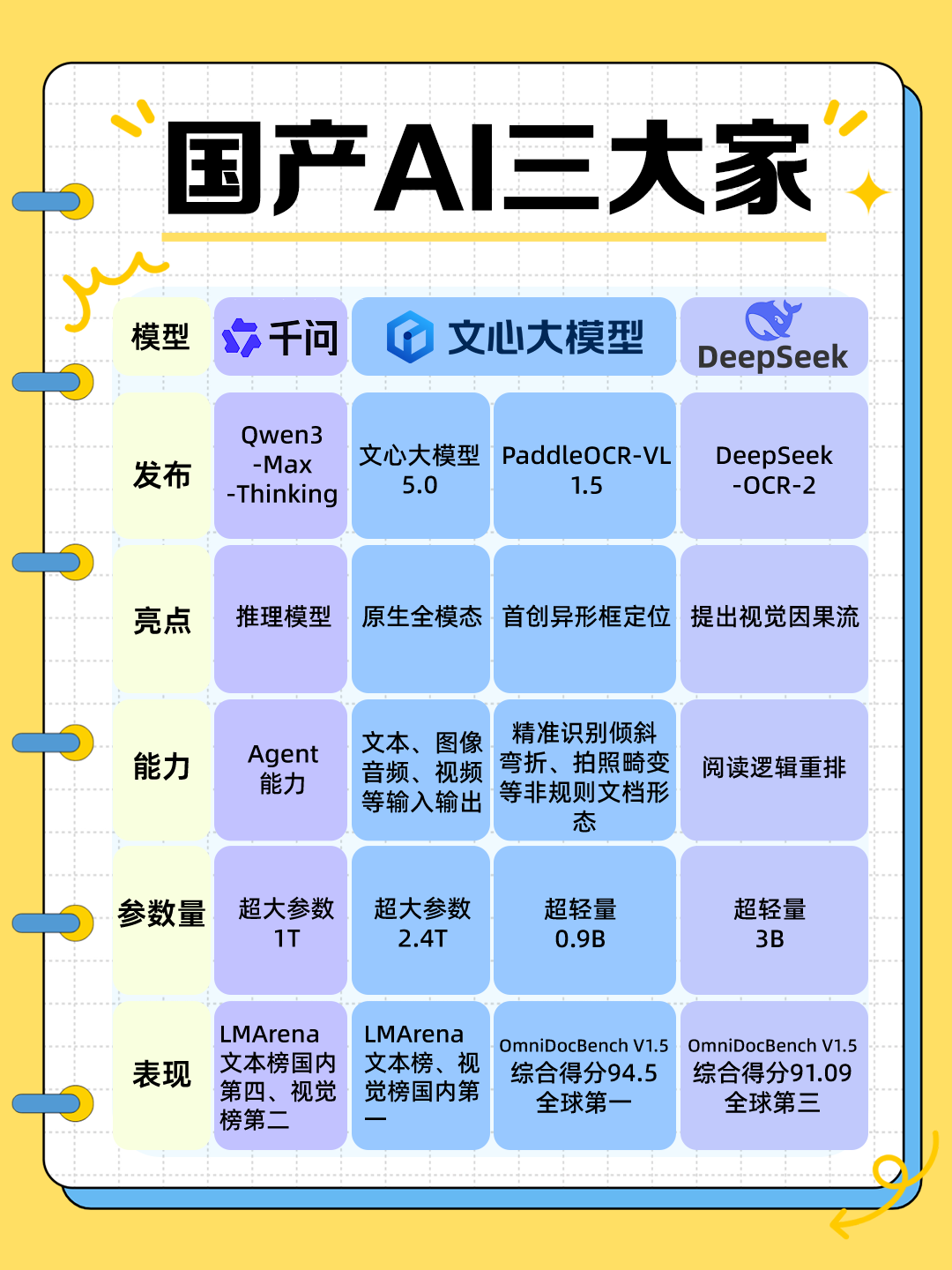
今天,中国AI在解决一个“老大难”问题上,又迈出了扎实的一步——1月29日,百度发布了其新一代文档解析模型PaddleOCR-VL-1.5。PaddleOCR-VL-1.5以0.9B参数的轻量架构在OmniDocBench V1.5上拿到了取得全球综合性能第⼀成绩,更重要的是它攻克了一个关键的工程落地难题:让OCR彻底告别“纸上谈兵”,能规模化处理现实中那些“不规整”的文档了。
百度的“异形框定位”可能是自OCR技术诞生以来,对“真实世界文档”最友好的一次进化。过去的OCR,文档必须要平整规则,可我们生活中的文档呢?手机随手一拍,角度歪了;纸张皱了,画面有折痕;对着电脑屏幕拍,有反光有摩尔纹……传统技术在这里就“懵”了,字或许能认,但整页的逻辑结构全丢。
PaddleOCR-VL-1.5能精准感知并勾勒出文字行、表格单元格、公式区域在变形画面中的实际多边形轮廓。无论是倾斜、弯折还是透视畸变,它都能把内容“一格一格”地摘出来,还原出本来的文档结构。这意味着什么?意味着拍照、识别、归档这个流程,终于可以摆脱对“完美扫描件”的依赖,在绝大多数真实场景下稳定跑通了。而对于金融行业,海量的变形发票、票据自动录入成为可能;对于政务和档案部门,历史档案、老旧文件的数字化效率和准确率将大幅提升;对于法律、教育等领域,复杂版面资料的电子化也不再是噩梦。
更难得的是,实现如此突破性能力的模型,参数仅0.9B,非常轻量高效。这得益于它“名门出身”——它是基于百度文心大模型开发的,继承了强大的多模态理解与生成能力,并通过创新的模型架构,在极小消耗下实现了极高的精度。
值得一提的是,一月的AI圈很热闹,中国科技公司正在各个层面展开扎实的创新竞速。百度PaddleOCR-VL-1.5的发布,正是这种趋势的缩影:不追求参数的盲目膨胀,而是聚焦于一个具体且广阔的产业痛点,用扎实的技术将其击穿。
这不仅仅是一个模型的胜利,更是一种研发思路的体现:最好的AI,不是实验室里的分数冠军,而是能走出实验室,稳稳地解决我们现实生活中那些“不完美”问题的得力助手。当AI开始真正理解和处理这个“不规整”的世界时,它所释放的价值,才是巨大的。