GPT-5.6。
看到这个名字,你的第一反应是什么?是"哇,GPT-5之后已经迭代到5.6了,进步真快",还是"等等,GPT-5不是还没正式发布吗,怎么就有5.6了?"
如果你产生的是后一种反应,恭喜你,你的直觉是对的。这正是目前AI圈最混乱、也最值得掰扯清楚的一件事。
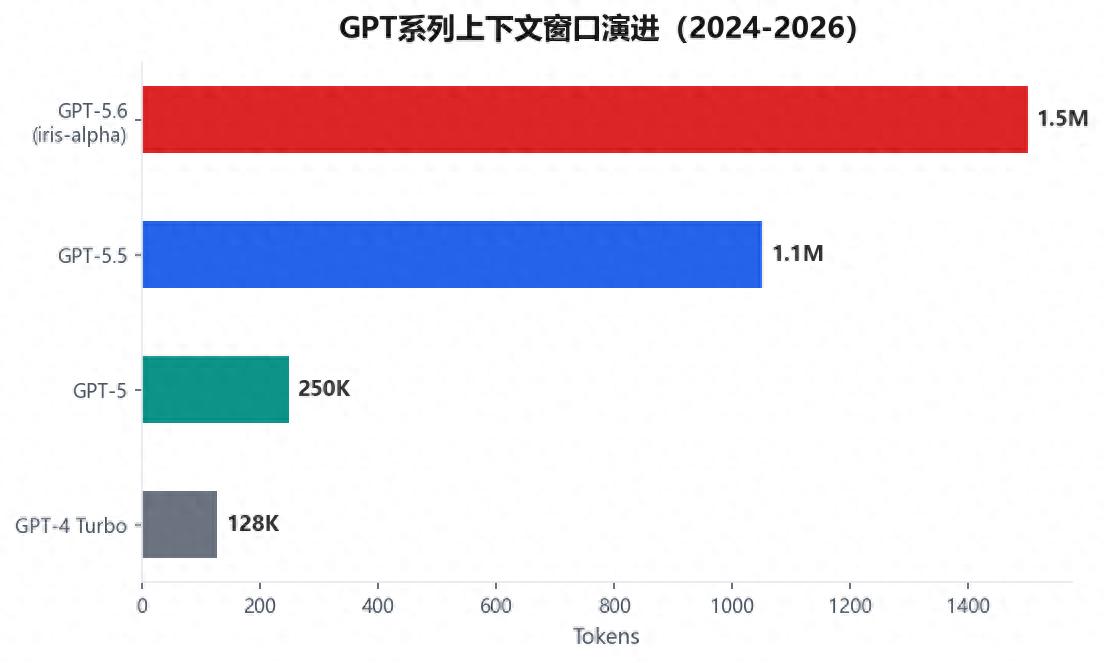
事情是这样的。最近有人在Codex的后端日志里发现了一个代号叫"Iris"的模型,各方证据指向它就是传闻中的GPT-5.6。这个发现之所以引发轩然大波,不仅仅是因为它的能力参数——150万token的上下文窗口,比GPT-4.1的100万提升了50%;更是因为它的命名本身,透着一股说不出的诡异。
GPT-5.2、GPT-5.3、GPT-5.5、GPT-5.6……这一系列版本号的变化,到底是技术迭代的真实写照,还是一场精心设计的命名游戏?
这就是今天要聊的核心争议:GPT-5.6的命名混乱,到底是技术突破的体现,还是OpenAI在用它掩盖某种进度上的落后?
支持方的观点:版本号不等于技术进步率
支持方认为,外界对版本号的焦虑,本质上是一种误解。大模型的版本号从来就不是一个精确的"代际标识",它更像是一个内部开发的里程碑标记。GPT-5.6之所以叫5.6而不是6.0或者GPT-6,可能是因为它在架构上仍然属于GPT-5系列,但在能力上已经有了质的飞跃。
最关键的证据就是那个150万的上下文窗口。
150万token意味着什么?意味着你可以把一整本几百页的书直接塞进去,让模型一次性读完并回答你关于整本书的问题。或者,你可以把一个大型代码库——比如Linux内核这种级别的项目——全部加载到上下文里,然后让模型帮你理解整个代码库的架构、找bug、甚至直接改代码。
这个能力,不是简单地"把上下文窗口拉长"就能实现的。上下文窗口越大,模型在推理时的注意力机制就越容易"迷失方向"——它可能会忘记最早输入的内容,或者在处理超长文本时出现逻辑断层。要把上下文窗口稳定地扩展到150万token,同时在质量上不下降,这需要模型架构、训练方法、推理优化多个层面的同步突破。
所以支持方的逻辑是:OpenAI之所以在版本号上看起来"跳来跳去",是因为他们在模型研发上采取的是并行推进的策略。5.2、5.3、5.5、5.6可能对应的是不同的实验方向或者不同的训练批次,最终哪个效果好,哪个就先发布。这种迭代方式虽然让外界看着眼花缭乱,但实际上反映了OpenAI在技术研发上的高强度投入。
况且,150万token这个数据本身就是硬实力的体现。不管你叫它GPT-5.6还是叫它西瓜哈密瓜,能处理150万token的上下文,就是比100万强。这才是用户应该关心的事,而不是纠结版本号叫什么。
反对方的观点:命名混乱背后是管理失序
反对方的核心理由是:命名混乱背后,反映的是OpenAI内部管理和发展战略上的深层问题。
首先是最直观的疑问:如果技术发展真的那么顺利,为什么版本号的跃迁看起来像是"拍脑袋决定的"?从5.2到5.6,中间跳过了一些版本号,又有些版本号据传被内部废弃了。这种不规律背后,有没有可能是某些版本的测试结果不达预期,不得不重新调整?
更关键的一个证据是知识截止日期。根据泄露的信息,GPT-5.6的知识截止日期是2025年5月。这意味着,这个模型的训练,至少在数据层面,是在一年多之前就完成了的。如果它在2026年6月才发布,那就意味着从训练完成到正式发布,中间隔了一年多的时间。
一年多的时间,在AI这个"三个月等于一年"的行业里,基本上等于一个世纪。
反对方认为,这个时间差说明OpenAI在模型完成训练之后,花了大量时间去做的不是"进一步提升能力",而是"确保安全性和合规性"——或者说得直白点,是在应对监管压力、做对齐训练、以及处理各种内部审查。这些工作当然重要,但它们也客观上拖慢了模型走向市场的速度。
而在这个空窗期里,竞争对手没有闲着。谷歌的Gemini在不断迭代,Claude的能力在稳步提升,甚至连开源模型都在快速追赶。OpenAI的领先优势,正在被一点点蚕食。
更让反对方感到不安的,是OpenAI在沟通策略上的变化。回想起GPT-3和GPT-4发布的时候,OpenAI虽然也比较低调,但至少技术报告写得还算详细,社区讨论也比较开放。但到了GPT-5这个系列,信息泄露、版本号混乱、发布时间一拖再拖,给人一种"他们在内部也在摸索,外面的人看到的只是混乱的投影"的感觉。
我的判断
我觉得反对方说的可能更接近真相。OpenAI确实在技术上仍有领先优势,但这种优势正在从"压倒性"变成"微弱"。命名混乱不是什么高深的战略,它更像是一个公司在快速扩张和高压竞争下出现的某种"内部失序"的症状。
但话说回来,即使OpenAI真的在管理上有些混乱,它仍然是最有可能第一个推出成熟的下一代大模型的组织之一。GPT-5.6如果能在6月如期发布,并且150万token的上下文窗口经得起实际使用的检验,那短期的命名争议其实不重要。
重要的是,OpenAI能不能在竞争对手全面发力之前,重新建立起那种让人信服的技术领导力。
从目前的情况看,这件事的难度,可能比他们自己预想的要大得多。
顺便说一句,我觉得整个AI行业在版本号这件事上都应该更规范一些。现在各家都在自己的版本号体系里玩,用户根本搞不清楚谁比谁强、哪个版本对应哪个能力水平。如果有一个统一的、基于基准测试成绩的版本标识体系,可能比现在这种各玩各的要透明得多。
当然,这事短期内不可能发生。因为版本号混乱对厂商来说是有利的——你可以把自己的产品包装成"最新最强",而不用担心用户拿你的版本号去跟竞争对手做精确对比。
所以,GPT-5.6的命名混乱,大概率会成为一个持续性的话题,直到OpenAI自己站出来做一个详细的技术解读为止。而那个解读什么时候来,以及它能不能真正打消外界的疑虑,目前来看还是个很大的未知数。
说到这里,其实还有一个被很多人忽略的角度:Siri换底这件事,对苹果长期战略的影响,可能比表面上看到的更深远。
苹果过去十几年一直在坚持的一个方向是"端侧AI"——也就是把模型运行在iPhone、iPad、Mac本地,而不是发送到云端处理。这个方向的好处是隐私保护更好(数据不用离开设备),坏处是本地设备的算力有限,能运行的模型规模也有限。
Siri换成Gemini之后,这个"端侧AI"的优先级会不会下降?我的判断是:短期会,长期不会。
短期来看,Gemini是一个云端模型,Siri调用它的时候,数据是要发送到谷歌的服务器处理的。这跟苹果一直强调的"隐私优先"多少有点矛盾。苹果可能会用一个"混合方案"来缓解这个矛盾:简单的请求在本地处理(用苹果自己的小模型),复杂的请求才发送到Gemini云端。
但长期来看,苹果绝对不会放弃"端侧AI"这个方向。原因很简单:如果Siri的大脑永远在谷歌的云端,那iPhone的"智能"就永远依赖网络连接和谷歌的服务可用性。这不是苹果能接受的事。
所以,更可能发生的事是:Siri在iOS 27里暂时用Gemini顶着,同时苹果悄悄训练自己的下一代端侧模型。等自己的模型够强了,再悄悄换回来。这种"借力打力"的打法,其实挺符合苹果的一贯风格的。
最后说一句:Siri从2011年发布到现在,已经15年了。一个人的年龄到15岁,刚好是青春期结束、成年开始的节点。Siri的15岁,是以"换掉自己的大脑"这种方式度过的。这件事,不管最后成不成功,都注定会被写进AI行业的教科书里。
至于换脑之后的Siri能不能真的变聪明,咱们2026年9月见分晓。