在华为中央研究院的实验室深处,一场算力革命正在悄然发生。面对传统电子芯片逼近物理极限的困境,华为CRI光计算团队另辟蹊径,将目光投向光子——这个速度更快、能耗更低的信息载体。其研发的硅光芯片技术,正成为突破AI算力瓶颈的关键路径。

随着半导体工艺逼近物理极限,著名的摩尔定律逐渐失效。传统电子芯片面临两大核心挑战:
发热密度剧增:制程微缩后,单位面积功耗不降反升,散热成为芯片性能提升的致命瓶颈。
数据搬运能耗高:冯·诺依曼架构下,数据在处理器与存储器间频繁迁移,能耗占比高达60%以上。
与此同时,AI大模型训练所需算力呈指数级增长。以华为盘古大模型为例,其早期因依赖传统NPU硬件,面临算力不足与能效低下的双重压力。业界亟需一种颠覆性技术,从根本上重构计算架构。
二、光计算的颠覆性突破华为CRI光计算团队提出“光电协同”的系统性方案,核心创新在于利用光子特性重构计算单元:

原理:通过微纳光学元件(如衍射光栅、波导阵列)直接完成矩阵乘法,规避电子传输延迟
性能:实验显示,光学矩阵乘加单元能效较传统GPU提升10-100倍,延迟降低至纳秒级
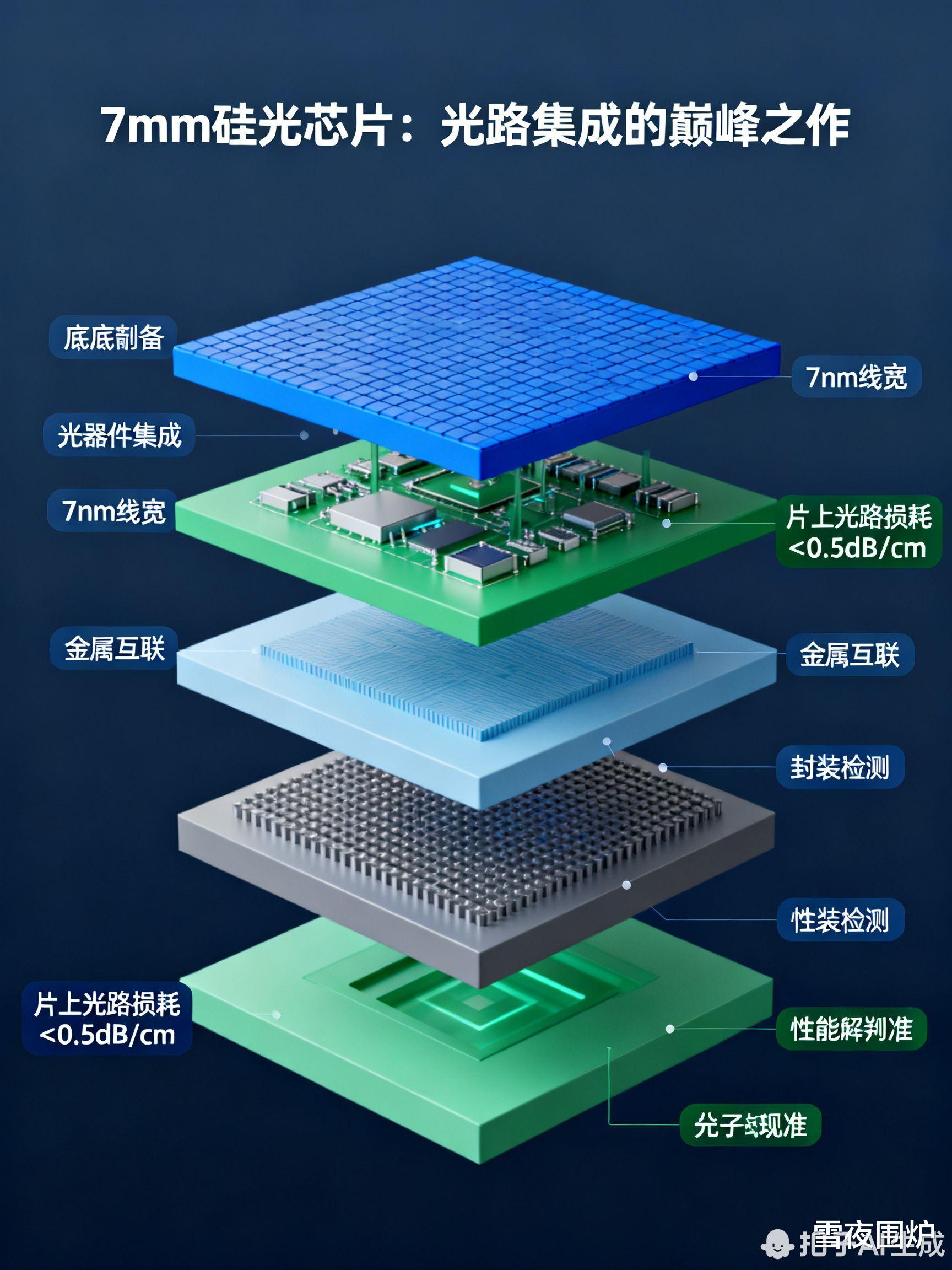
集成化:团队将菲涅尔透镜等光学元件蚀刻在硅基芯片上,实现片上光路集成(技术路径指向7nm工艺)
2.光学蓄水池计算:时序数据处理利器架构创新:利用光学散射介质或延时环路构建固定权重的“蓄水池层”,仅需训练输出层权重
优势:大幅减少训练参数,对语音识别、金融预测等时序任务效率提升显著。

应用场景:专为组合优化问题设计(如物流路径规划、芯片设计)
性能:基于参量振荡的光学系统,求解速度较传统CPU提升数个数量级
三、实测数据:从实验室到产业落地华为已将光计算技术融入昇腾AI算力平台,实现性能跨越式升级:
昇腾384超节点:采用3168根光纤构建光互联网络,总带宽达1229TB/s
算力对比:较英伟达H100 GPU提升107%,大模型推理能耗降低18%
能效比:光子卷积单元在图像识别任务中,能效为电子芯片的10-100倍
这一突破的直接价值是降低AI使用门槛。昇腾384量产后,预计使国内大模型训练成本下降40%,加速AI在医疗、制造等领域的普惠化。
四、未来挑战与战略意义尽管前景广阔,光计算仍面临三大挑战:
光电转换效率:电信号到光信号的转换损耗仍需优化
集成度提升:7nm硅光芯片的大规模量产良率攻关
算法适配:需重构AI模型以匹配光学计算特性
华为的布局已超越单一技术突破。通过光计算、昇腾AI集群及鸿蒙生态的协同,中国正构建自主可控的算力底座。正如昇腾芯片工程师所言:“我们陪着昇腾一步步从充满bug走到今天,付出的代价巨大,但意义更深远。”
产业启示录:光计算并非替代电子,而是通过“光进电退”重构算力范式。当英伟达CEO黄仁勋公开承认昇腾384“参数超越英伟达尖端技术”时,一个属于光子的AI算力时代已拉开帷幕。
更多技术细节可参考:华为CRI光计算团队论文《现代计算与光学的跨界机遇》昇腾光互联技术解析:知乎专栏《性能超英伟达1.7倍!华为甩出"算力炸弹"》
评论列表