导读 多模态特征嵌入:数据生成与技术前沿
本文系统阐述了大模型时代多模态表征学习的前沿进展,聚焦数据构建与模型架构两大挑战。文章指出,多模态特征嵌入是实现智能应用的基础,但 CLIP 模型存在语义理解瓶颈。对此,团队提出数据优化三路径:利用 LLM 重写文本提升质量、去冗余提升训练效率、挖掘图文交错文档构建 RealSyn 数据集。模型方面,团队推出 UniME 系列,通过知识蒸馏与困难样本挖掘优化训练,并借助 MLLM 筛选负样本,在多项任务中实现 SOTA。文章强调数据精耕与 MLLM 编码器的重要性,相关成果均已开源,为学界与工业界提供了重要参考。
本文主要介绍以下四个方面:
1. 研究背景
2. 数据生成
3. 多模态特征嵌入模型
4. 专业问答(Q&A)
分享嘉宾|冯子勇博士 格灵深瞳 技术副总裁、算法研究院院长
编辑整理|杨峰
内容校对|郭慧敏
出品社区|DataFun
核心问题:为什么需要关注多模态特征嵌入?
多模态特征嵌入技术旨在将图像、文本等不同模态的信息映射到统一的语义空间,是实现智能搜索、内容理解等应用的基础。其核心价值在于:
应用广泛:在电商(以文搜图)、安防(基于文本的行人追踪)、个人相册管理(自然语言检索)等领域有巨大应用潜力。技术瓶颈:尽管 CLIP 模型奠定了坚实基础,但其双塔架构、文本长度限制、全局对比学习带来的“词袋”问题等缺陷,限制了其对细粒度语义和复杂语境的理解。解决方案之一:高质量数据集的构建与优化本文前半部分重点论述了数据的重要性,并提出了三种提升数据质量的新范式:
数据“重写”(RWKV-CLIP):针对网络爬取文本噪声大、描述简单的问题,提出利用大语言模型(LLM)融合原始文本、检测标签等多源信息,生成多样化、语义丰富的图像描述,显著提升文本质量。数据“去冗余”(CLIP-CID):发现大规模数据集(如 LAION-400M)中存在大量语义冗余样本。提出一种简单的图像语义平衡方法,可剔除近一半(43.7%)的冗余数据,在保持性能的同时大幅提升训练效率。数据“新来源”(RealSyn):创新性地利用海量图文交错文档(Interleaved Documents)这类非成对数据,构建了高效的抽取、清洗与检索增强生成 pipeline,开源了高质量的 RealSyn 数据集,证明了其卓越的数据缩放与模型缩放能力。解决方案之二:新一代特征嵌入模型架构本文后半部分重点介绍了从传统双塔模型到基于多模态大模型(MLLM)的嵌入模型演变,并详细介绍了团队的UniME系列模型。
范式转变:研究从仅使用文本训练的 E5-V,到首次尝试用 MLLM 做嵌入的 VLM2Vec,社区开始探索 Decoder-only 架构在多模态表征学习中的潜力。UniME-V1:提出了两阶段训练框架。第一阶段通过知识蒸馏增强模型的文本判别能力;第二阶段引入困难负样本挖掘与假负样本过滤的指令微调,有效解决图文偏差问题,在 MMEB 基准上取得显著提升。UniME-V2:针对 V1 批次采样限制,创新性地提出 “MLLM-as-a-Judge” 框架,利用大模型自身的强大推理能力从全局候选集中筛选高质量困难负样本,并引入 Pairwise/Listwise 排序器进行训练,最终在组合理解、长短文本检索等复杂任务上实现了 SOTA 性能。核心结论与价值数据与模型同等重要:在大力改进模型结构的同时,对训练数据进行“精耕细作”(重写、去冗余、挖新源)是提升性能的关键且高效的路径。MLLM 是强大的特征编码器: 证明了基于MLLM的嵌入模型能够更好地理解细粒度、组合性语义,是超越传统CLIP模型的重要方向。开源贡献:文章介绍的 RWKV-CLIP、CLIP-CID、RealSyn 数据集、UniME-V1/V2 等多项工作均已开源,为学术界和工业界提供了宝贵资源和技术标杆。01研究背景本次分享将围绕多模态特征嵌入技术,从研究背景、数据生成方法以及特征嵌入模型三个部分,探讨其最新进展与应用前景。多模态特征嵌入技术在多个领域具有广泛的应用前景,其核心在于实现不同模态数据(如文本、图像)在语义空间中的对齐与交互。
1. 应用场景:电商
电商场景:传统电商搜索主要依赖关键词匹配或人工标注的商品类别。多模态特征嵌入允许用户输入复杂的自然语言描述(如“法式碎花连衣裙”),模型通过提取查询文本和库中图像的特征进行匹配,实现更精准的以文搜图。
2.应用场景:安防
安防场景:公安系统每日接收海量图像数据,传统方法依赖预定义属性(如衣服颜色)进行筛选,难以应对复杂、变化的描述(如“黑衣白裤戴帽子的拎箱男子”)。多模态嵌入技术可通过自然语言直接搜索目标,大幅提升检索效率与灵活性。
3.应用场景:相册
个人相册管理:多模态嵌入技术可以帮助用户通过自然语言描述(如“我和小狗玩耍的照片”)快速定位目标图像,无需手动翻阅整个相册。
 4.CLIP 模型的缺陷与挑战
4.CLIP 模型的缺陷与挑战技术基础与缺陷:上述应用多基于 CLIP(Contrastive Language-Image Pre-training)模型。然而,CLIP 存在明显缺陷:
双塔架构不支持多模态输入;文本编码器长度受限(如 77 个 Token);全局对比学习易导致“词袋”现象(Bag-of-words),即无法理解语序,造成“马吃草”与“草吃马”的语义混淆。02数据生成1.数据生成:RWKV-CLIP 论文里的数据制作方法(重写)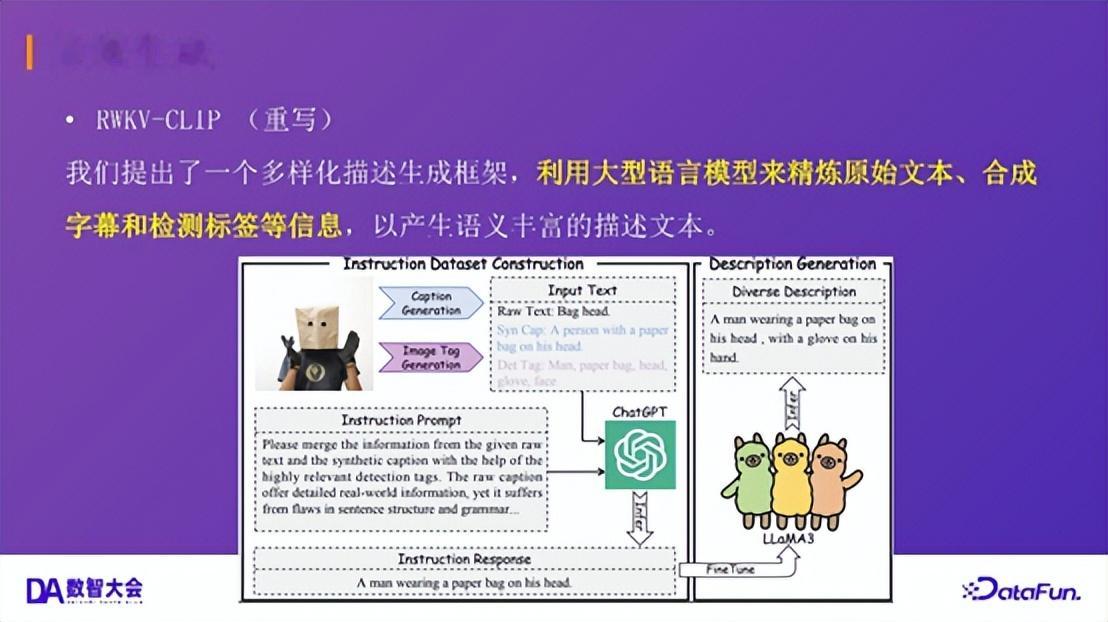
训练数据的质量至关重要。我们首先提出了一个多样化描述生成框架,利用大型语言模型来精炼互联网爬取的原生文本(通常存在噪声或过于简短),并融合图像标题、检测标签等信息,生成语义更丰富、更准确的描述文本。

训练 CLIP 需要高质量的图像-文本对,但网络爬取的数据常存在噪声、描述简略或不准等问题。我们在 RWKV-CLIP 论文中提出了一个多样化描述生成框架。该框架利用大型语言模型(LLM),融合图像的原始文本、合成字幕和检测标签等信息,生成语义丰富、准确的高质量文本描述。该方法在生成质量和下游任务性能上均优于之前的 CapFusion 等方法。
2.数据生成:CLIP-CID(去冗余)
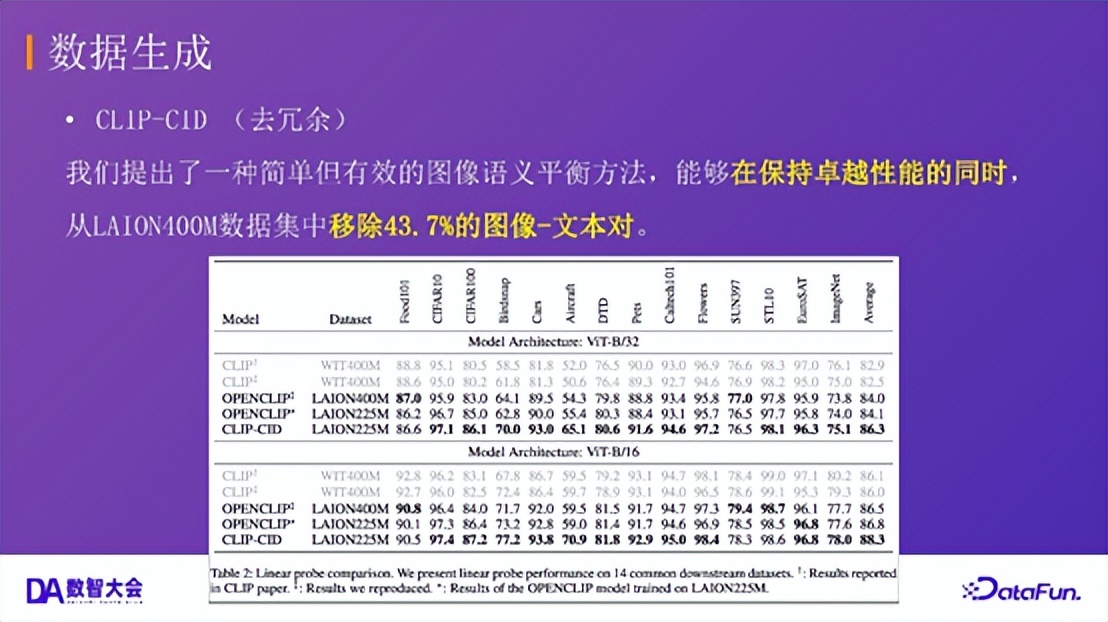
大规模数据集(如 LAION-400M)中存在大量语义冗余的样本,降低了训练效率。我们提出了一种简单高效的图像语义平衡方法 CLIP-CID。该方法是一种基于聚类簇-实例判别的高效知识蒸馏方法,过滤掉冗余样本,成功从 LAION-400M 数据集中移除了 43.7% 的图像-文本对。使用去冗余后的 LAION-225M 数据集训练,模型性能不仅未下降,在多类任务上反而有显著提升。
3.数据生成:RealSyn(交错文档利用)
我们探索了如何利用互联网上存在海量的图文交错文档(Interleaved Image-Text Documents),将其转化为可用于 CLIP 训练的高质量成对数据的方法 RealSyn,该方法可以扩充数据的多样性与规模,提升 CLIP 预训练效果。

数据构建:我们构建了完整的数据抽取与清洗 pipeline,从交错文档中提取出高质量的图像和句子库,并进行了严格的质量过滤(如去除表情符号、URL)和冗余过滤(感知与语义冗余)。

检索增强生成:基于构建的库,我们设计了检索增强生成框架:为每一张图片,从真实世界文本库中检索匹配的句子,并结合大模型合成生成描述,最终融合形成高质量的图文对。

开源与效果:我们构建并开源了 RealSyn 数据集(15M/30M/100M 三个规模)。实验证明,RealSyn 在 Linear Probe、Transfer 和 Robustness 等评估维度上均优于 LAION 数据集,并展现出良好的数据缩放与模型缩放能力。所有数据、代码和模型均已开源。
03多模态嵌入模型1.多模态特征嵌入模型:研究背景随着技术的发展,Decoder-only 架构的大语言模型在特征嵌入学习(如 MTEB 榜单)中展现出强大潜力。与此同时,多模态大模型迅速发展。一个核心问题随之产生:如何利用 MLLM 学习统一的多模态特征嵌入?
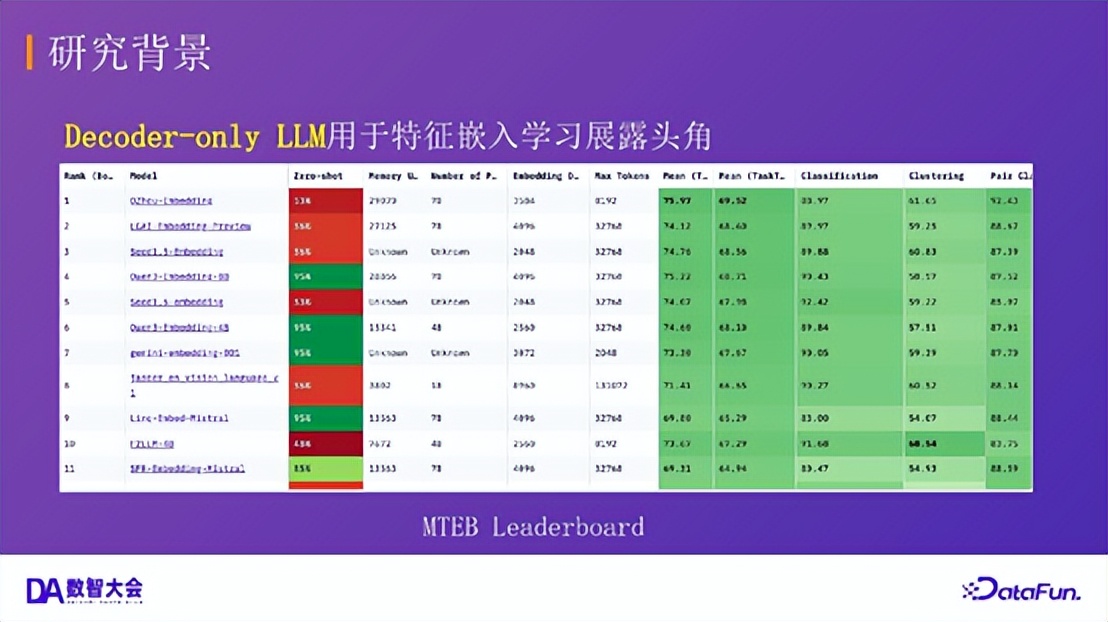
范式转变:在大语言模型(LLM)领域,Decoder-only 架构(如用于特征嵌入的模型)在 MTEB 等榜单上展现出强大性能。这启示我们探索类似的架构用于多模态嵌入。
 2.多模态特征嵌入模型:E5-V 的启发
2.多模态特征嵌入模型:E5-V 的启发E5-V 工作提供了一个重要思路:仅使用文本对数据(如 NLI 数据集)对 MLLM 中的语言模块进行训练,即可让其初步具备多模态特征嵌入的能力。这为后续研究打开了新的方向。
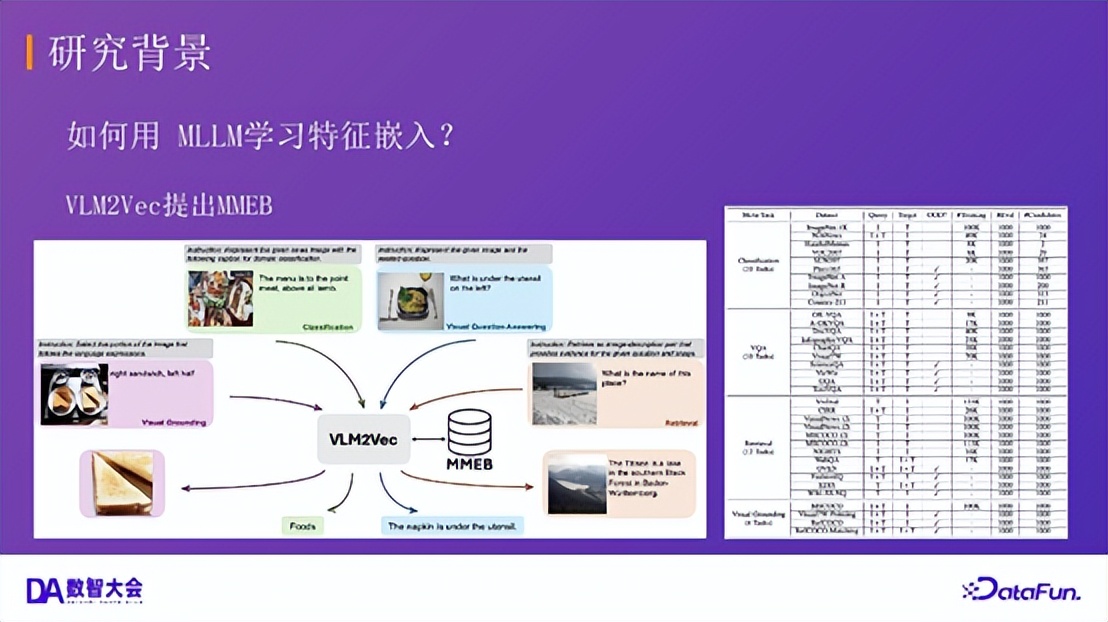 3.多模态特征嵌入模型:VLM2Vec 与 MMEB 基准
3.多模态特征嵌入模型:VLM2Vec 与 MMEB 基准VLM2Vec 工作在此基础上,提出了首个全面的多模态嵌入基准 MMEB,涵盖分类、VQA、检索、定位等 4 大类共 36 个数据集。同时,它提供了一个简单的基线方法,确立了该领域的基本评估体系。
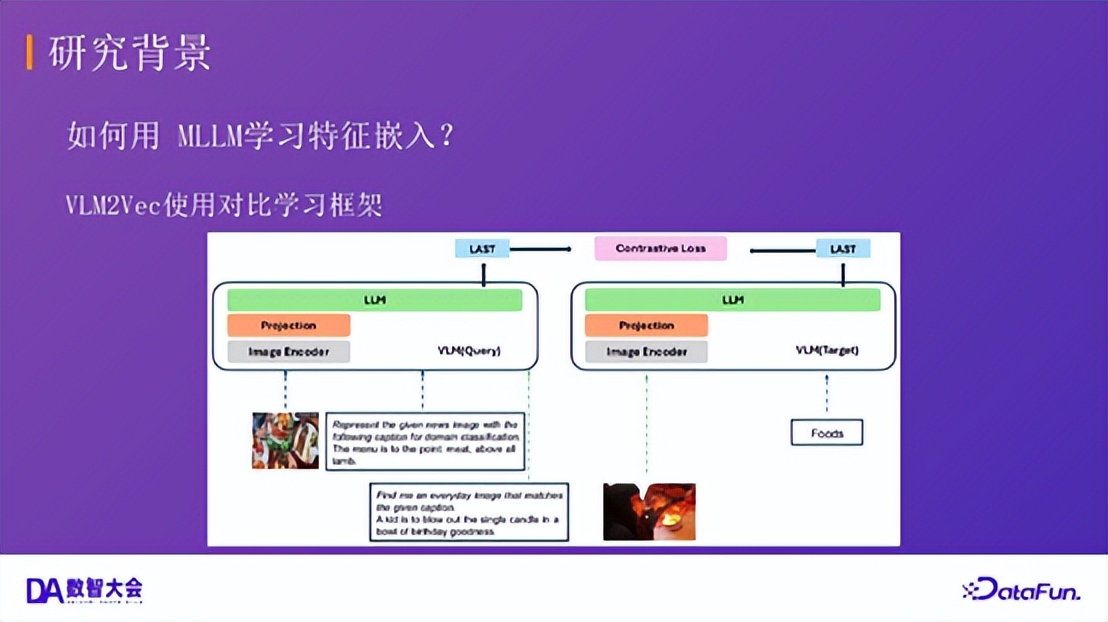
VLM2Vec:该工作首次尝试使用多模态大模型(MLLM)进行特征嵌入学习。它提出了多模态嵌入基准 MMEB,并采用对比学习框架,为后续研究提供了重要的基线。
4.多模态嵌入模型:UniME-V1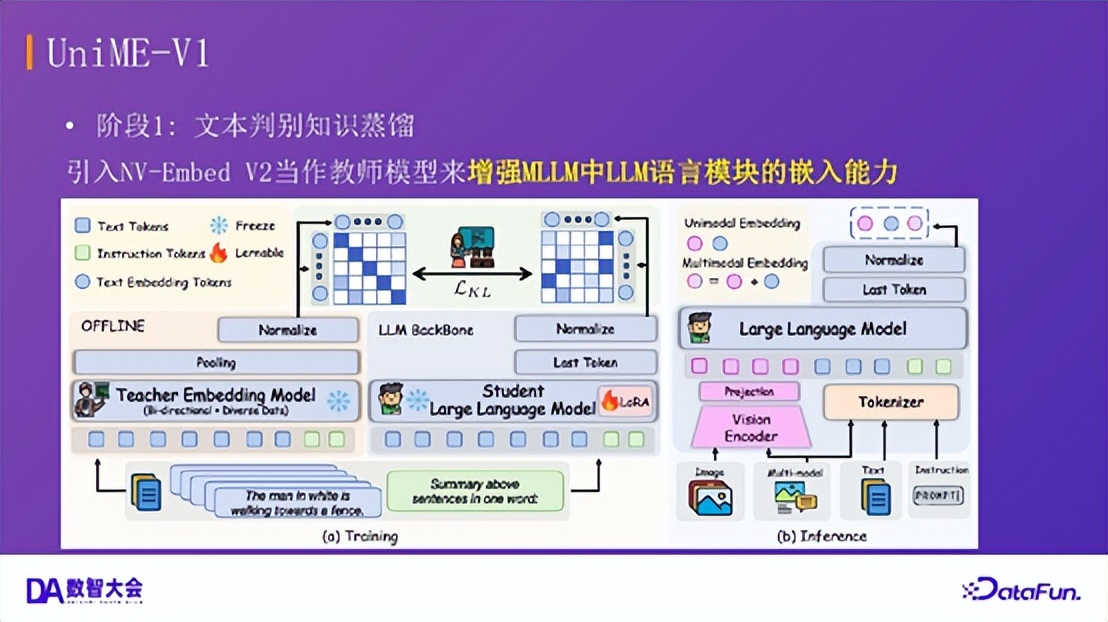 UniME-V1:阶段一(文本判别知识蒸馏)
UniME-V1:阶段一(文本判别知识蒸馏)我们提出了 UniME-V1 模型,其训练分为两个阶段: 阶段一:文本判别知识蒸馏。引入 NV-EmbedV2 作为教师模型,通过知识蒸馏增强 MLLM 中语言模块的文本嵌入能力,使模型初步具备判别力。

UniME-V1:阶段一的局限性
然而,仅使用文本训练会导致图文对齐出现偏差,且通用的指令模板难以满足丰富多样的下游任务需求。

UniME-V1:阶段二(负样本增强的指令微调)
阶段二:负样本增强的指令微调。阶段一仅使用文本训练,导致图文对齐存在偏差。本阶段引入负样本增强机制,核心是困难负样本挖掘与假负样本过滤。通过筛选具有高语义相似性的困难负样本和移除错误标注的假负样本,为模型提供更有效的监督信号,显著提升模型表征能力。
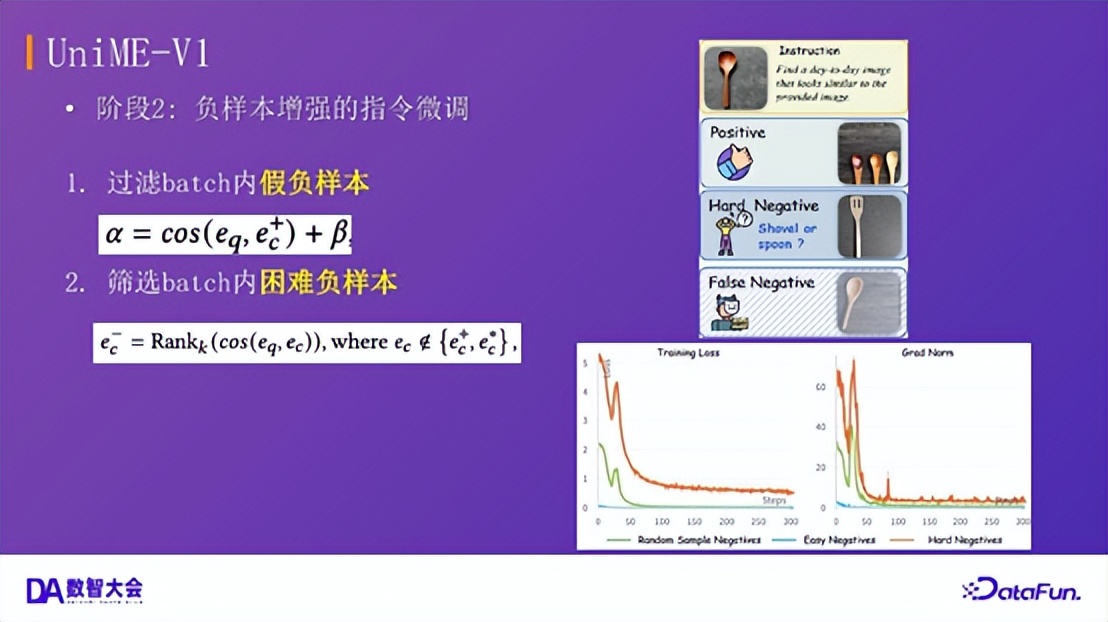
UniME-V1:困难负样本挖掘技术
我们提出了两种核心技巧:
假负样本过滤:通过设定相似度阈值来识别并过滤掉批次内被错误标记为负样本的正样本。困难负样本筛选:根据特征相似度对批次内负样本排序,选择最困难的样本参与训练。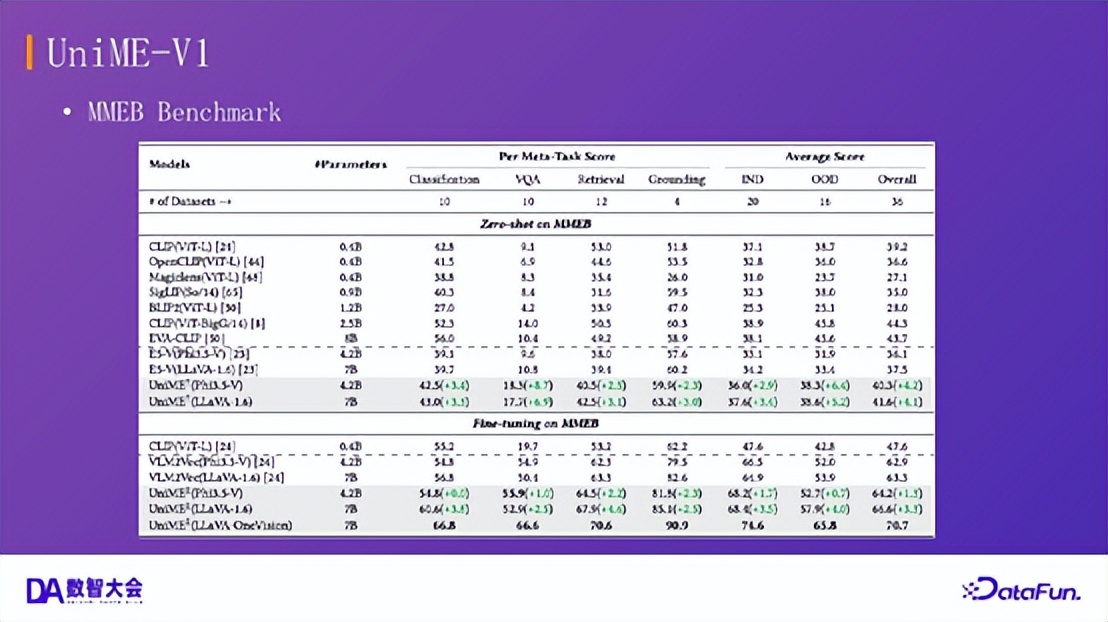
UniME-V1:MMEB 基准性能
在 MMEB 基准上,UniME-V1 在零样本和微调设置下均显著优于 VLM2Vec 等基线模型,证明了我们方法的有效性。

UniME-V1:零样本图文检索性能
在零样本图文检索任务上,UniME-V1 在短文本、长文本检索以及组合理解任务(如 SugarCrepe)上均表现优异,尤其展示了强大的组合理解能力,超越了 EVA-CLIP 等大型模型。
效果:如表所示,UniME-V1 在 MMEB 基准的各项任务上均显著超越基线模型。同时在零样本长短文本检索、组合理解(Compositional Retrieval)等任务上也优于 EVA-CLIP-8B 等大型模型。

UniME-V1:模型学到了什么?
可视化分析表明,训练前模型更关注全局抽象概念。经过第一阶段训练后,表达具体语义的词汇重要性提升。第二阶段指令微调后,模型对具体语义词汇的响应概率显著增大,证明其学到了更精细的多模态理解能力。

UniME-V1 的不足
UniME-V1 的困难负样本挖掘受限于训练批次大小和初始检索模型的效果,这为后续改进提供了方向。
5.多模态嵌入模型:UniME-V2 UniME-V2:动机
UniME-V2:动机UniME-V1 的负样本挖掘受限于训练批次(Batch)大小和检索模型的效果。为此,我们提出 UniME-V2,UniME-V2 的核心思路是更充分地利用 MLLM 自身的强大理解能力来优化表征学习,引入了类似搜索系统中的重排序思想。


UniME-V2:MLLM 作为评判者进行困难负样本挖掘
我们提出了“MLLM-as-a-Judge”的困难负样本挖掘框架:
首先,使用一个现成的嵌入模型为每个 Query 检索出 50 个潜在困难负样本。然后,使用一个强大的 MLLM(如 Qwen2.5-VL)作为评判者,根据 Query 与 Candidate 的语义匹配程度进行打分和排序,最终筛选出最困难的 8 个负样本,此过程能有效过滤假负样本。这取代了 V1 中依赖于相似度函数的简单方法。6.多模态嵌入模型:UniME-V2 训练与结果 UniME-V2:训练与重排序
UniME-V2:训练与重排序训练:UniME-V2引入了UniME-V2-Reranker,使用MLLM生成的语义匹配分数作为软标签(Soft Label),并采用Pairwise和Listwise相结合的方式进行训练,损失函数为JS散度。
重排序:额外训练一个 UniME-V2-Reranker 模型,采用 pairwise 和 listwise 的联合训练方式,对初步检索结果进行精细化重排。

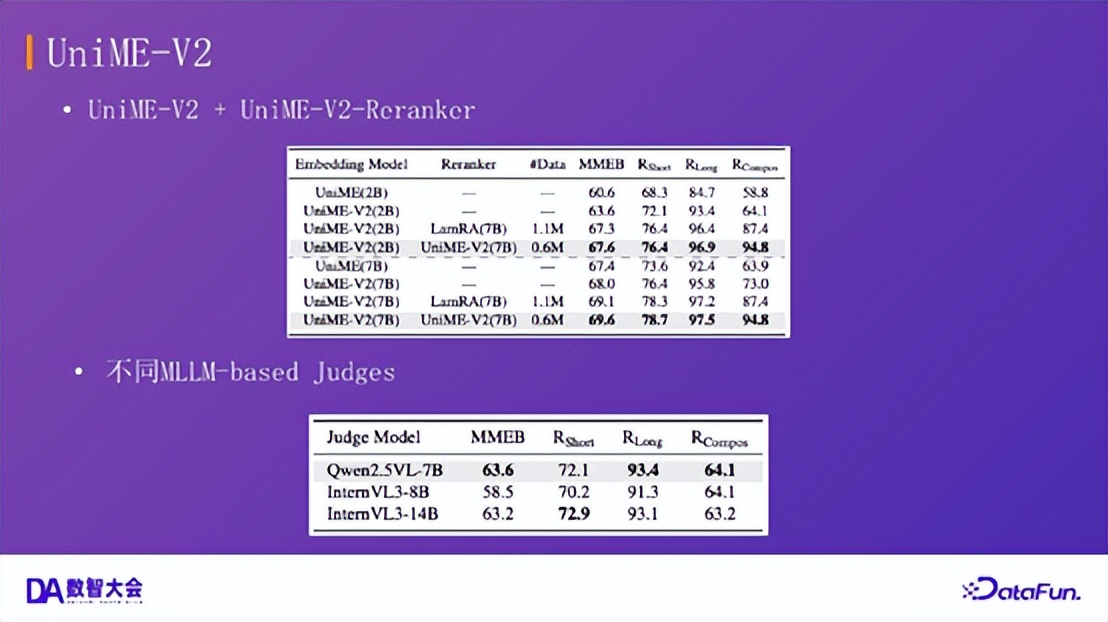
UniME-V2:MMEB 基准性能
在更新的 MMEB 基准上,UniME-V2 在不同规模的基座模型(如 Qwen2-VL 2B/7B)上均实现了稳定提升,证明了新框架的有效性。

UniME-V2:零样本图文检索性能
UniME-V2 在长短文本检索上持续进步,并在组合理解任务上取得了显著提升,表明基于 MLLM 评判的困难负样本挖掘策略对此类复杂任务尤为有效。
UniME-V2:消融实验与分析
消融实验证实:
引入重排序模型能带来巨大增益。困难负样本挖掘的效果高度依赖于评判 MLLM 的能力,模型越强,挖掘的负样本越有效。结论:UniME-V2 在 MMEB 基准上的表现全面优于 UniME-V1。特别是在短文本检索(Short Caption)和组合理解(Compositional Retrieval)任务上提升显著,这证明了更优质的困难负样本对于模型理解细粒度语义至关重要。
UniME 系列(V1 & V2)的论文、代码和模型权重均已开源,我们希望推动多模态嵌入领域的发展。未来,我们将继续探索更高效的训练方法和更强大的模型架构。
致谢与推广: 感谢大家的关注。我们(灵感实验室)将持续深入探索相关技术方向。欢迎大家关注我们在B站的节目,以轻松的方式分享更多技术观点。
04
专业问答(Q&A)
Q1:数据筛选是自动化还是人工完成的?
A1:数据筛选流程是自动化的。通常会先在少量数据上人工验证规则或阈值的有效性,之后扩展到全量数据时则完全依靠自动化流程。
Q2:假负样本是如何产生的?
A2:假负样本的引入原因复杂。由于数据主要通过自动化流程构建,在标注或清洗过程中,某些语义上本应匹配的样本对被错误地标记为不匹配,从而形成了假负样本。我们通过设置置信度(如 90%)来控制质量,但无法绝对保证完美。
以上就是本次分享的内容,谢谢大家。