Augmenting Greybox Fuzzing with Generative AI
Jie Hu (University of California Riverside), Qian Zhang (University of California Riverside), Heng Yin (University of California Riverside)
引用
Hu J, Zhang Q, Yin H. Augmenting greybox fuzzing with generative ai[J]. arXiv preprint arXiv:2306.06782, 2023.
论文:https://arxiv.org/abs/2306.06782
摘要
在现实世界中,要求结构化输入的程序通常都会有一个格式解析阶段来限制它进入程序内部,无法通过格式解析的输入将无法进入程序内部,因此生成符合格式的输入时这种程序的必要阶段。但是无论是基于突变的方法还是基于生成的方法,都无法提供既有效又可扩展的解决方案。目前经过大量自然语言语料库预训练的大语言模型(LLM)能够十分高效地理解隐含的格式语法并生成符合格式的输入。所以本文基于此提出了CHATFUZZ,一个通过生成式人工智能增强的灰盒模糊测试器。作者进行了大量实验,探索了利用生成式LLM模型增强模糊测试的能力。实验结果表明,在12个目标程序(来自三个经过充分测试的基准测试)的边界覆盖率上比SOTA灰盒模糊测试器(AFL++)提高了12.77%。漏洞检测方面,CHATFUZZ在具有明确语法规则的程序上表现与AFL++相当或更好,但对于具有非平凡(non-trivial)语法的程序则表现一般。
1 引言
近年来,模糊测试已成为测试软件系统的常用技术,它能高效地发现应用程序中的关键安全漏洞。通常,模糊测试使用种子输入运行一个程序,通过变异种子输入以提升给定的引导指标(如分支覆盖率),然后重复这个变异输入和执行目标程序的过程。
模糊测试使用生成的大量测试输入执行目标程序,并监视运行时行为以发现漏洞。为此,生成能够有效覆盖广泛的执行路径和程序行为的测试案例至关重要。这种全面的覆盖能够彻底探索程序的功能,并有助于发现潜在的漏洞。模糊测试的简单性使其成为大规模软件系统中常用的测试程序;然而,模糊测试的有效性是基于一个固有但容易被忽视的假设:一组任意的输入变异都能产生有意义的输入。但是之前的研究表明,这种假设通常对以高度结构化数据作为输入的软件系统并不成立。为了沿着执行路径探索程序状态,所以需要确保测试输入符合有效格式。因为任何格式破损的输入都将在程序的格式解析阶段被立即拒绝,从而限制了对更深层程序状态的探索。目前已经有大量简化高度结构化数据生成的研究工作。现有的输入生成工作可以分为两组:基于变异( mutation-based )的方法和生成式(generative)的方法。即使使用最先进的技术,也难以在这两个类别中生成结构化输入。
基于变异的方法中,程序输入是通过变异现有种子来生成的。属于这一类别的有灰盒模糊测试工具,如American Fuzzy Lop(AFL)及其变种,白盒模糊测试工具如SAGE,SymSan,以及像QSYM这样的混合模糊测试工具。它的问题在于它们通常会生成大量语法无效的输入。AFL++和SymSan生成的用于xml解析器libxml2的种子,2小时内有效的xml文件比例分别为0.82%和16.93%。也就是说,在格式解析阶段之后的深层程序状态可能会被忽视。以前使用生成式方法的工作是根据潜在测试案例的指定语法从头开始构建结构化输入。然而,为每种不同的数据格式构建语法需要手动进行,这将耗费大量时间,并且构建的语法往往不够完整。为了解决这个问题,有研究者提出了一种基于学习的方法,如TreeFuzz。TreeFuzz生成的JavaScript程序符合语言的语法的占比达到96.3%。然而,生成式方法忽略了可以使用来自程序运行时的反馈来改进输入生成过程。在测试过程中对程序状态的探索可能不够完整,因为这些生成式方法不利用运行时信息来优化输入生成。
使用预训练的大语言模型(LLMs)进行文本生成已变得越来越普遍。LLMs将自然语言规范和指令转换为具体代码方面也非常有效。本文奠定了一个AI增强的模糊测试技术的基础以生成有效和真实的输入。作者观察到LLMs能够理解提供的示例的结构并生成具有相同结构的变体。这一观察形成了基于AI的输入变异的基础。
基于这一观察,作者提出了一个新的模糊测试框架,将生成式AI与灰盒模糊测试相结合,并进一步实现了一个名为CHATFUZZ的系统。CHATFUZZ的工作流程如下:除了灰盒模糊测试的典型工作流程外,一个对话变异器将从种子池中选择一个种子,并提示一个ChatGPT模型端点以获取类似的输入。这些输入然后由灰盒模糊测试工具评估,并且其中一些将被保留作为进一步探索的新种子。
种子质量生成的对话变异器非常依赖于ChatGPT模型的配置。作者确定了与对话变异器性能相关的五个超参数:1)模型端点选择;2)模型提示设计;3)模型响应长度;4)完成选择的数量;5)采样温度。作者进行了实验,探索不同的超参数配置。
为了评估新方法的有效性,作者基于AFL++和ChatGPT实现了一个原型CHATFUZZ。并在12个期望基于文本的输入的程序上评估了CHATFUZZ。评估结果表明,与原始的AFL++相比,CHATFUZZ平均提高了12.77%的边界覆盖率。CHATFUZZ平均贡献了模糊测试工具队列中12.77%的种子。而且,CHATFUZZ对于语法明确的程序表现特别好。
本文的贡献如下:
确定生成符合格式输入的生成是基于变异的方法和生成式方法的一个主要难点。提出将生成式人工智能与灰盒模糊测试相结合,并提供了详细的实验,探索最佳方法。评估了CHATFUZZ,以证明新方法的有效性。2 技术介绍
CHATFUZZ是一个基于AFL++实现的生成式人工智能增强型灰盒模糊测试工具。如图1所示,CHATFUZZ由两个主要组件组成:1)灰盒模糊测试工具,即AFL++,和2)对话变异器(Chat Mutator),即一种AI增强型的种子变异器。
在测试过程开始时,对话变异器从模糊测试工具的种子池中随机选择一个种子作为示例输入,以提示ChatGPT模型端点进行变异。然后解析响应,将每个变异作为一个种子存储在AI种子队列中。CHATFUZZ可以使用任何灰盒模糊测试工具进行测试,它将从种子池中选择一个种子进行变异,并评估变异后的种子,保留那些触发新代码区域的种子,最后从对话变异器生成的种子将定期扫描,将新覆盖种子导入到模糊测试工具的种子池中。
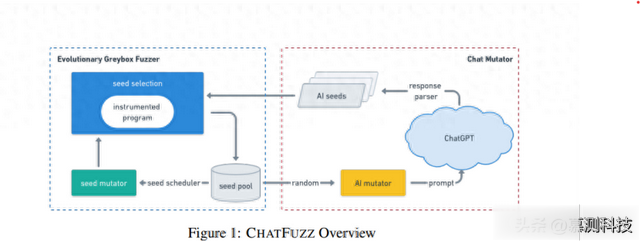
图1:ChatFUZZ整体工作流程
CHATFUZZ的性能取决于两个对应部分生成的种子的质量。为了找到最佳的对话变异算子配置,作者将AFL++替换为AFL-cmin,这样就可以通过其边覆盖来过滤对话变异器生成的种子。本节将讨论ChatGPT的五个主要超参数。为了避免过拟合,作者在四个程序上进行实验:jq、php、mujs和xml。其中,mujs接受JavaScript源代码作为输入,而其余三个目标接受各种格式化的数据文件(json、php、xml)作为输入。本文评估了边覆盖率的增长(通过AFL++ 4.03a中附带的AFL-cmin工具进行评估),测试用例的唯一性比率(通过md5sum校验和验证)以及句法有效比率。
2.1 模型端点选择
根据输入类型和完成任务的性质,OpenAI API提供了各种模型端点。本文专注于变异文本数据形式的示例输入。因此有两个模型端点供评估:1)对话模型(chat model)和2)完成模型(completion model)。
对话模型。给定描述对话的消息列表,对话模型将返回一个响应。在此类别下的模型有gpt-4、gpt-4-0314、gpt-4-32k、gpt-4-32k-0314、gpt-3.5-turbo和gpt-3.5-turbo-0301。效果最好的模型是gpt-3.5-turbo。作者在接下来的讨论中评估了这个特定的模型,并使用标签CT表示它。
完成模型。使用完成模型就可以为模型提供一个提示,以返回一个或多个预测的完成。在此类别下有text-davinci-003、text-davinci-002、text-curie-001、text-babbage-001和text-ada-001。作者进行了一项小规模测试,检查这些模型的延迟以及生成的有效种子的比率。最终选择了text-curie-001作为完成模型(CT)进行评估的后续步骤。与CT模型相比,CP效率更高,但更昂贵。
2.2 提示设计
查询ChatGPT模型的提示词的设计是确保响应质量的核心。作者期望通过将生成式LLM模型作为额外的变异器,将其融入到灰盒模糊测试中来生成更加真实的输入,从而改进灰盒模糊测试。因此,作者让模型以特定格式生成样本输入的变体。为了评估不同提示词对生成的测试用例的影响,作者评估了两种模型端点的三种不同配置的提示词,如表1所示。将样本输入或新测试用例的预期格式之一作为输入。结果看来,具有样本输入和已知文件格式的AI模型配置是最好的选择。作者添加了配置AI_noINPUT,即输入中不加入样本输入,以了解样本输入是否对于生成更好的灰盒模糊测试用例起到作用;又配置了AI_noFORM,即样本中不加入输入预期格式以查看是否需要提供输入的预期格式以生成符合格式的测试用例。

表1:提示词模板
2.3 max tokens-最大Token数
Max tokens可以是任意正整数值,它表示模型响应的最大长度。数值较小可能导致生成的测试用例被截断,从而导致格式错误。而较大的值意味着模型完成请求并生成响应需要更长的时间。然而,良好格式的测试用例并不一定具有固定长度。对于json、php、JavaScript、xml等数据格式,有效的种子可以具有各种长度。较大的max tokens值有助于生成更多有效的种子。然而,对于灰盒模糊测试而言,重要的是在短时间内生成尽可能多的变异。因此,研究者需要在效率和种子质量之间取得平衡。

图2:不同max_tokens值对模型延迟的影响
为了找到最佳的超参数配置,作者研究了不同max tokens值的模型延迟,范围从16(默认值)到1024,分别针对具有对话模型(即AI CT)和完成模型(即AI CP)的AI配置。对于每个程序,作者使用相同的种子提示相应的对话变异器,并记录延迟。重复每次查询10次以减少随机性,并绘制箱线图,如图2所示。此外作者还绘制了每个max tokens值选择的平均模型延迟,每个程序一个。每个程序使用一个语法上有效的种子进行此实验。作者评估这些样本输入的长度,如表2所示。模型AI CP随着max tokens值的增加,四个测试程序的模型延迟总体上增加。而模型AI CT,趋势不太明确。最后将max tokens取值为256。

表2:不同数据格式的样本输入长度
2.4 n-完成选择数
该超参数决定每次模型查询要生成多少个完成选项。n的值是介于1到128之间的整数。每次查询的响应时间将随着n值的增加而延长。此外,每个模型查询都有一个上下文长度的限制。上下文包括提示/输入和响应/输出。随着更多的响应选择被生成,如果上下文长度达到限制,将不再生成更多的响应选择。为了找到n的最佳值选择,作者进行了以下实验:对于每个程序评估使用不同AI模型端点(即CT和CP)时,n从1到128的每个模型查询的延迟以及每个生成的测试用例的平均延迟,并重复10次以减少随机性。这个实验使用了表2中的相同样本输入集。结果显示在图3中,分别为模型AI CT和AI CP。
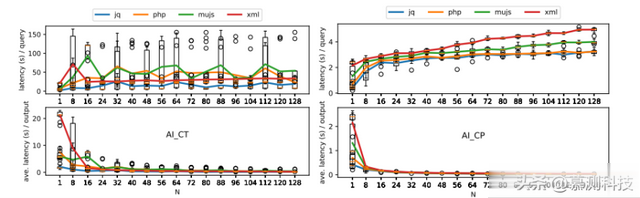
图3:模型延迟与n值
根据结果,随着n值的增加,每次查询的成本增加,这意味着每个输入种子的耗时更长,而生成一个测试用例的平均成本正在降低,即效率更高。为了推进模糊进程并有效地发现新的覆盖范围,对话变异器应该具有短的响应时间,以便尽快为模糊器队列生成更多种子。最后确定n取值为20。
2.5 temperature-采样温度
这个超参数表示用于查询模型的采样温度的值。它的范围是0和2之间的浮点数,默认为1。较低的温度值意味着模型更加集中和确定,而较高的值会使输出更加随机。当温度值较低时,模型更加聚焦,有时会生成与样本输入相似甚至相同的响应。当温度值较高时,输出变得过于随机,使得输出的格式不再符合语法规则。为了找到最佳的温度值选择,作者进行了以下实验:
对于每个目标程序,让AI CT和AI CP两个模型,连续运行两个小时。每个模型将采样温度配置为在0到2之间每隔0.25取一次值。在每次试验结束后使用三个指标评估生成种子的质量:1)种子唯一比率,2)种子有效比率,以及3)代码覆盖率。通过结果讨论如何确定最佳的采样温度。
种子唯一比率。如图4所示,对于AI CT模型,随着温度的增加,唯一种子的比率增加。当采样温度低于0.25时,超过一半的生成种子是重复的。通常情况下,采样温度越高,就能够生成更多的唯一种子。对于jq和xml程序,使用AI CP模型时,种子唯一比率在采样温度从0增加到1.25时增加,当温度高于1.25时会下降,。作者发现在这个温度范围内会生成更多格式不正确的种子,这些种子只有几个字节长。此外,与AI CP模型相比,由AI CT模型生成的种子具有更高的唯一比率。

图4:种子唯一比率与温度关系
种子有效比率。作者评估了在不同采样温度设置下,所有生成种子中语法有效种子的比率。根据图5中的结果,随着采样温度的升高,有效种子的比率降低。原因在于,采样温度越高,模型的输出越随机,更有可能违反语法规则。此外,AI CT模型对于jq、mujs、xml具有更高的种子有效比率,而对于php则较低。
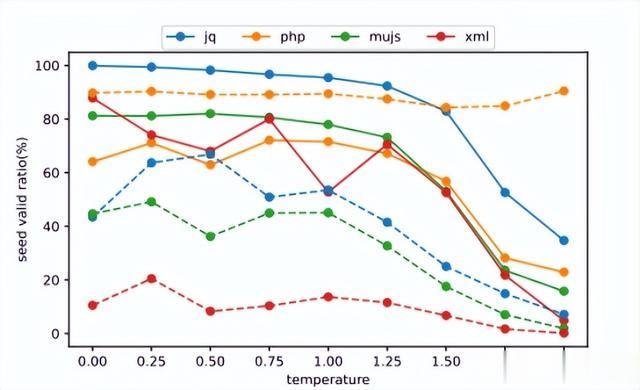
图5:种子有效比率与温度关系
覆盖率提升。对于每个模型,作者评估了从0到2的不同采样温度,步长为0.25。对于每个配置,评估了九个不同的温度值。在2小时的模糊测试试验结束时,作者收集了所有生成种子的分支覆盖率,并计算了相对于初始语料库的改进比率,如图6所示。作者进一步研究了不同采样温度下对四个测试程序的代码覆盖率改进比率的统计排名,并在表4中呈现。

图6:种子覆盖增长比率与温度关系
根据结果,AI CT在温度为1.50时具有最高的代码覆盖率增长,而AI CP在温度为1.25时表现最佳。采样温度较低时,模型会生成大量重复种子,因此代码覆盖率改进较低。采样温度较高时,模型会生成更多语法无效的种子,这会违背利用LLM生成语法有效种子的初衷。

表3:覆盖率增长排名
在比较AI CT和AI CP之间的结果时,从AI CT生成的种子质量更好,因为种子有效比率和唯一比率都高于AI CP。然而,在代码覆盖率改进比率方面,AI CT优于AI CP。这是因为AI CT模型的效率远高于AI CP。在2小时的模糊测试试验时间内,AI CP模型生成的种子数量是AI CT的15.91倍到99.31倍。
2.6 提示词切除研究
样本输入。此处作者讨论在模型提示符中包含示例输入的必要性。对于每个程序,作者评估了对话模型(即CT)和完成模型(即CP)的配置AI和AI noINPUT,并评估了8小时内边覆盖的增长。
根据图7所示的结果,在四个被测试的程序中,AI始终比模型提示符中不包含示例输入的AI noINPUT表现得更好。结果表明,样本输入对于生成AI模型生成触发新代码覆盖的种子至关重要。
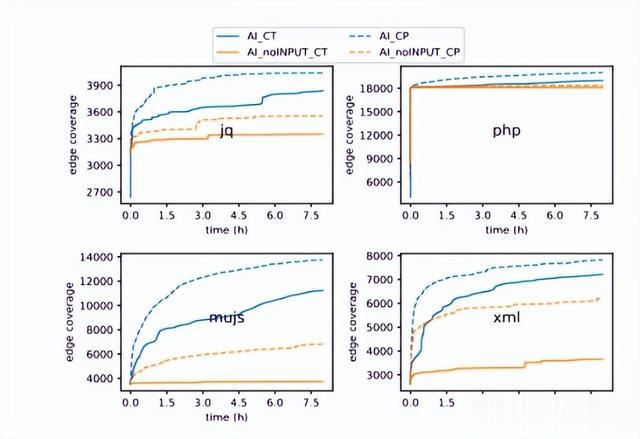
图7:样本切除与覆盖率的影响
在模型端点方面,CP模型的表现始终优于CT模型。表4中显示了了试验结束时的边覆盖率。对于CT模型,当样本输入从模型提示符中移除时,代码覆盖率平均下降了15.98%。对于CP模型,从模型提示符中删除样本输入导致代码覆盖率下降22.88%。
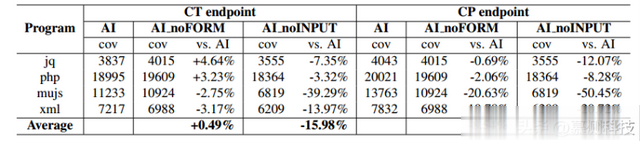
表4:各端点的边覆盖率
输入格式。此处作者讨论在模型提示符中指示测试用例格式的必要性。对于每个程序,作者对CT对话模型和CP完成模型的AI noFORM配置AI进行了评估。8小时连续模糊结果如图8所示。
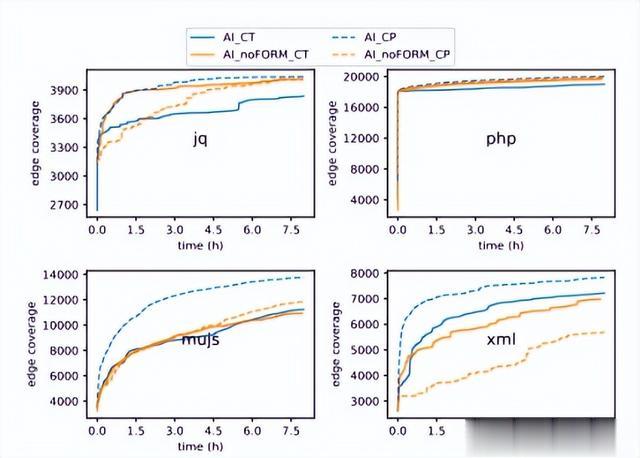
图8:输入格式切除与覆盖率的影响
根据结果,从CT配置的模型提示符中删除数据格式信息不会对覆盖率发现产生实质性影响,因为四个程序与AI模型的覆盖率差异小于5%。对于CP配置,四个测试程序的代码覆盖率平均下降了8.54%。
3 实验评估
在本节中,作者通过回答以下研究问题来评估他们提出的方法的有效性:
RQ1:覆盖效率。CHATFUZZ能为端到端灰盒模糊测试带来多少覆盖率改进?RQ2:变异有效性。CHATFUZZ能否为具有不同输入格式的所有程序生成高质量的种子?RQ3:安全应用。CHATFUZZ是否更有效地检测漏洞?3.1 评估计划
为了更好地回答上述研究问题,作者使用如下中列出的以下基线配置:
AFL++. 原始的 AFL++ 模糊器。使用版本AFL++ 4.03a,没有对话变异器。CHATFUZZ。完整的 CHATFUZZ 模型集成了 AI CP 和 AFL++。在这个配置中,对话变异器随机选择一个来自模糊器队列的种子作为样本输入,以触发 CP 模型使用最佳参数配置生成新的变异。对话变异器生成的所有种子都会定期由 AFL++ 检查,以导入任何触发新边缘覆盖的种子到模糊器队列中。CHATFUZZ-F。此模型将 AFL++ 与 AI noFORM CP 集成。与完整的 CHATFUZZ 相比,它从模型提示中删除了数据格式信息。CHATFUZZ-C。此模型将 CHATFUZZ 中的 CP 模型替换为 CT 模型。CT 模型的延迟明显高于 CP 模型,但能够生成更少的重复项和更多的有效种子。CHATFUZZ-CF。通过此模型,移除了 CHATFUZZ-C 模型的对话变异器的模型提示中的输入格式信息。目前,CHATFUZZ 支持接受基于文本格式的目标程序。作者检查了来自先前工作中大量评估的三个基准测试 Unibench、Fuzzbench 和 LAVA-M 中的 45 个程序,并在表5中列出了 CHATFUZZ 可以为其生成真实输入的 12 个程序。作者将这 12 个目标分为三类,基于输入种子的格式:1) 格式化的数据文件;2) 不同编程语言中的源代码; 3) 没有显式语法规则的文本。

表5:实验程序集
实验设置。所有实验都在一台工作站上进行,该工作站配备了两个插槽、48核、96 线程的 Intel Xeon Platinum 8168 处理器,该工作站配备768G内存,操作系统为 Ubuntu 18.04,内核版本为 5.4.0。每次模糊化试验都会分配一个专用核以确保公平。
RQ1 覆盖率效率
为了展示 CHATFUZZ 相对于 AFL++ 的覆盖率效率,作者对 12 个程序进行了连续 8 小时的模糊化活动,测量了边缘覆盖率。结果如图 9 所示。第一列显示了四个以 json、php、xml 和 JSON 格式的数据文件作为输入的程序的结果。中间一列显示了四个以程序源代码文件(JavaScript、sql、C 和 lua)作为输入的程序的结果。最后一列显示了以文本文件作为输入且没有明确语法规则的程序的结果:HTTP 响应、DER 证书、.b64 文件以及 md5校验和。

图9:CHATFUZZ边覆盖
在这 12 个目标程序中,CHATFUZZ 找到的边覆盖 AFL++ 多了 11.04%。具体来说,对于程序 xml、mujs、ossfuzz 和 md5sum,CHATFUZZ 分别比 AFL++ 多找到了 24.30%、76.75%、13.40% 和 8.92% 的边覆盖。在jq、php、jsoncpp fuzzer、lua、curl 和 base64这六个程序中,CHATFUZZ 对 AFL++ 的改进在 5% 以内。对于程序 cflow、openssl x509 和 base64,差异小于 1%。
此外,作者评估了 CHATFUZZ-F 在相同一组目标上的覆盖发现来验证构建无格式信息的灰盒模糊器的潜力。在实际程序模糊测试中,有些情况下输入格式没有明确指示。借助像 ChatGPT 这样功能强大的生成型 AI,模型可能会检测到样本输入的格式,并利用这些信息来生成新的变异。作者在表6中报告了 CHATFUZZ-F 的 8 小时代码覆盖率。平均而言,它比 AFL++ 能够找到 6.11% 更多的覆盖率。这表明,即使不提供预期的输入格式,CHATFUZZ 仍然能够改善灰盒模糊测试。

表6:CHATFUZZ 8小时代码覆盖率
正如前面实验所示,相较于CP端点,CT 端点生成的重复项较少,更有可能产生有效的种子。因此,作者评估了 CHATFUZZ-C 和 CHATFUZZ-CF,它们使用了 CT 端点,除此之外基本上等同于 CHATFUZZ 和 CHATFUZZ-F 模型。作者在表6中报告了 8 小时的模糊测试结果。根据结果,CHATFUZZ-C 和 CHATFUZZ-CF 找到的边缘比 AFL++ 多了 7.61% 和 6.89%。结果接近于无格式信息的 CHATFUZZ 模糊器,即 CHATFUZZ-F。
这些结果表明,CHATFUZZ 的覆盖率效率高于 AFL++。
RQ2 突变效果
在本小节中,作者调查了生成型 AI 增强的种子变异器对代码覆盖率的贡献。在表 7 中,作者报告了 CHATFUZZ 系统的 AFL++ 对应部分保留的模糊器队列长度,以及从对话变异器导入的种子数量,以及导入种子占模糊器队列的比例。CHATFUZZ 的对应部分触发尚未发现的新边覆盖时会导入对话变异器生成的种子。此处作者使用导入种子的比率作为评估生成型 AI 增强变异器的有效性和贡献度的指标。

表7:导入种子占模糊器队列的比例
如图,CHATFUZZ 中平均有 12.77% 的模糊器队列种子是从对话变异器导入的。对于三个程序:mujs、ossfuzz 和 lua,对话变异器贡献了超过 30% 的种子。值得一提的是,这三个程序都接受来自各种编程语言的源代码作为输入。对于另外三个测试程序:jq、php、xml,它们都接受格式化的数据文件作为输入,CHATFUZZ 为模糊器队列贡献了超过 10%。对于表 5 中列出的第三类程序,CHATFUZZ 对灰盒模糊器的贡献较少甚至没有。这是因为这些程序的输入格式相对复杂。在图 10 中,作者展示了除了四个程序(curl、openssl x509、base64、md5sum)之外的数据集中 AFL++ 和 CHATFUZZ 模糊器队列中有效种子的比率。这些程序的输入既不是简单的格式,也不符合明确的语法规则。根据结果,在所有目标程序中,CHATFUZZ 中的模糊器队列中的语法有效种子比例高于 AFL++。对于 jq,CHATFUZZ 和 AFL++ 的模糊器队列中分别有 393 和 392 个有效种子。对于 CHATFUZZ,28.24% 的有效种子是从对话变异器导入的。
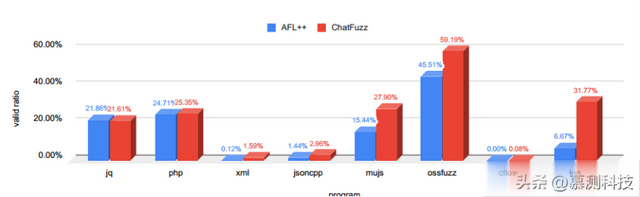
图10:模糊器队列中有效种子的比率
实验结果表明,Chat Mutator能够生成更多有效的种子,并对灰盒模糊器做出贡献。
RQ3 漏洞检测能力
在本节中,作者评估了 AFL++ 和 CHATFUZZ 的漏洞检测能力。作者通过检查了六个程序的崩溃输入,包括 UniBench 基准测试中的四个程序和 LAVA-M 数据集中的两个程序。在表8中,作者展示了每个基准测试在 8 小时内检测到的独特漏洞数量。根据结果,在 jq、mujs、ossfuzz 或 md5sum 中,AFL++ 和 CHATFUZZ 都无法触发任何漏洞。对于程序 cflow,CHATFUZZ 能够发现比 AFL++ 更多的漏洞。对于程序 md5sum,CHATFUZZ-CF 能够发现 12 个漏洞。
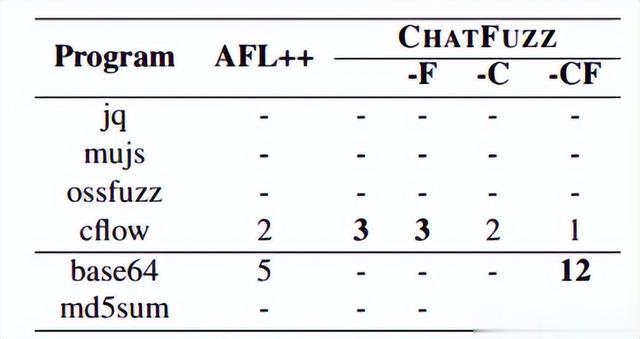
表8:程序8 小时内检测到的独特漏洞数量
4 局限性
目前,CHATFUZZ 可用于对执行基于文本格式的输入的程序进行模糊测试。不支持其他数据格式,例如图像、视频、音频或需要特定数据加载器的数据格式,如 PDF、WOFF 或压缩文件。CHATFUZZ 受限于对话变异器中使用的 AI 模型。如果使用支持更多数据格式的生成式 AI 模型,例如 DALL·E,CHATFUZZ 将能够生成图像格式的测试用例。对于没有明确语法规则的基于文本的输入,例如哈希值,生成式 AI 很难找出文本的基本规则,因此对话变异器可能对灰盒模糊器的贡献较低或无贡献。
CHATFUZZ 目前是使用 OpenAI API 服务构建的,与本地 LLM 模型相比具有较高的延迟。与 API 服务相关的其他限制,例如上下文长度、查询速率,也会影响 CHATFUZZ 的性能。在只能通过极长输入触发程序状态的情况下,模型无法生成该输入。此外,模型不会自动记忆过去的提示。因此,它无法直接用于模糊测试网络协议等具有状态的目标程序。
先前的工作表明,应动态地优先考虑不同的变异器,以提高覆盖效率。不同参数配置下的对话变异器实际上是不同的变异器。具体来说,当用较低的采样温度提示 AI 模型时,样本输入与新种子之间的差异较小,而在高采样温度下则相反。
5 总结
在本文中,作者针对性地对接受高度结构化数据作为输入的真实世界程序的灰盒模糊测试问题进行了研究。并确定符合格式的输入生成是基于变异和生成方法的主要限制之一。因此,作者提出利用生成型大型语言模型的能力来生成格式良好的程序输入,以改善灰盒模糊测试。作者基于此实现了CHATFUZZ,并在先前研究中广泛测试过的三个基准测试中评估了12个目标程序。结果证明,CHATFUZZ比最先进的灰盒模糊测试工具AFL++具有更高的覆盖效率。它能够生成更多的语法有效种子,从而探索更深层次的程序空间。
转述:李顺