
昨天刷到 Deepseek 又搞事了,说实话,我看完论文那一刻有点懵
元旦刚过,Deepseek 就扔出来一篇技术论文,名字叫 mHC(流形约束超连接)。这名字听着就够劝退的,但看完之后,我算是明白了一件事: 中国 AI 公司这回是真的在「省钱」这条路上卷出花来了。
你或许会疑惑,训练 AI 模型难道不就是花大钱购置显卡?有啥值得去节省的?
嗯,这就是问题所在。
训练大模型,就像开一家永远在烧钱的店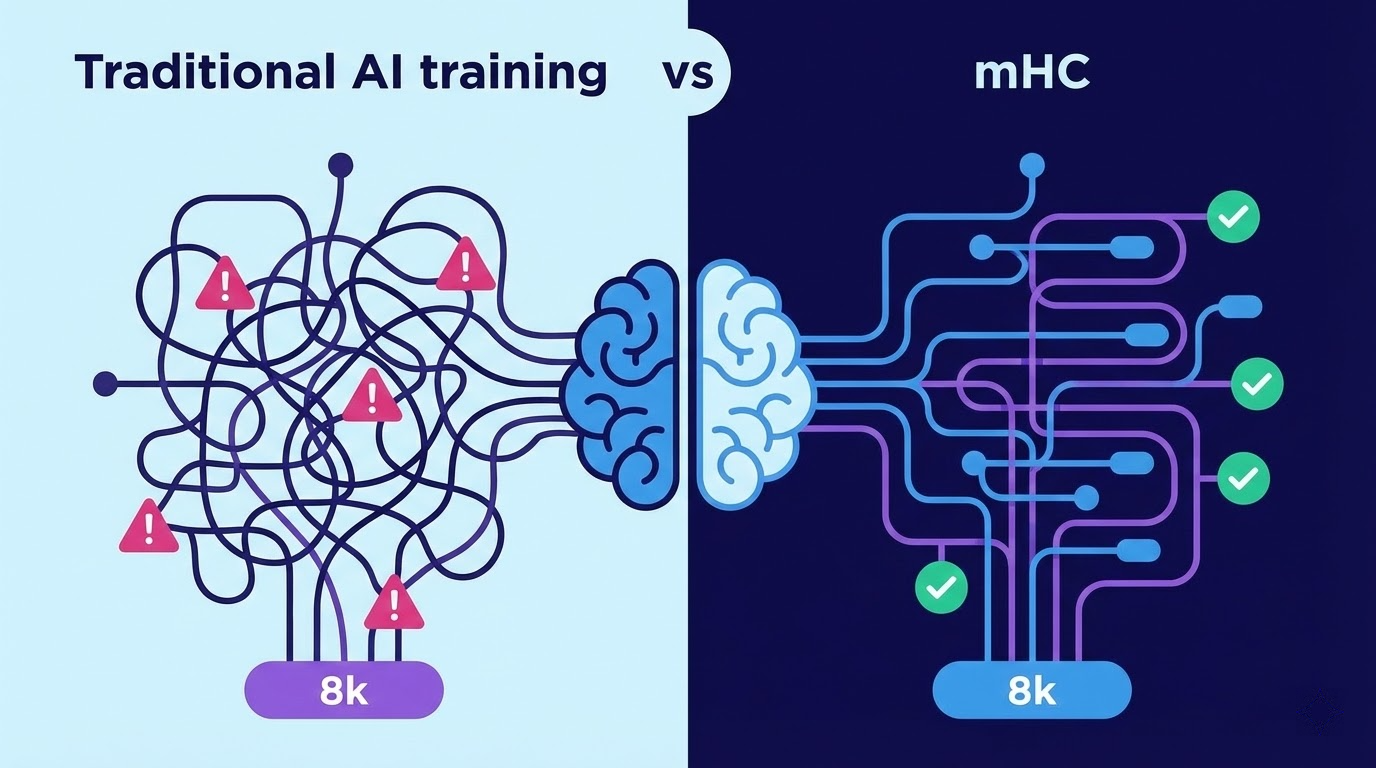
咱们先说说训练 AI 模型到底有多费钱。
你瞧瞧 OpenAI、谷歌这类巨头,单说 AI 基建一年就得砸好几百亿美刀。为啥?因为模型越大,参数越多,训练的时候就越容易出状况。打个比方吧,就像你盖房子,楼层越高,地基越不牢靠,稍微一个参数没弄对,整个训练过程就崩了,之前花的钱全打了水漂。
这事儿在技术层面被称作“梯度爆炸”或是“梯度消失”,简单来讲,就是信号在神经网络中不断传递,要不就放大得难以控制,要不就衰减得没了踪影。
此前字节跳动有过一项名为「超连接」(HC)的技术,初衷很不错:让信息在神经网络中多流转些路径,如此模型能学得到更快。不过,路径多了便易拥堵,在训练大模型的时候常常出状况。
Deepseek 这次的 mHC,就是专门来解决这个问题的。
他们是怎么做的?用数学把「路」给修好了
mHC 的核心思路,用人话讲就是: 给那些乱七八糟的信息通道加了个「限速器」。
从技术层面来讲,他们将超连接投射到某一特定的“流形”之上,使得信号在网络中传输时,既不会出现异常情况,也不会消逝不见。乍一听感觉很玄妙,其实不过是运用数学办法把信号给稳固住了。
最牛的是什么你知道吗?
他们对参数从 30 亿到 270 亿的模型开展测试,训练时长仅仅增加了 6.7%,然而信息流动的“通道”却增长了四倍。这般效率,竟好似在高速公路上跑出了地铁般的态势。
这事儿背后的真正意义: 不靠蛮力,靠脑子我为什么说这事儿重要?
因为现在全球 AI 圈有个趋势,就是「肌肉男」路线: 谁显卡多,谁就牛。OpenAI 砸钱,谷歌砸钱,Meta 也砸钱,大家都在比谁家矿多。
但 Deepseek 这篇论文告诉你: 算法优化也能顶半边天。
尤其是在芯片出口限制的大背景下,中国 AI 公司拿不到最顶级的 GPU,那怎么办?只能在软件层面死磕,把每一块显卡的效率榨到极致。
这就像你开店,别人家有十个店员,你只有五个,那你就得想办法让这五个人干出十个人的活。mHC 就是这么个思路。
下一步呢?可能是 Deepseek-R2
业内有传闻,Deepseek 或许在春节前后推出新模型 R2,而且 mHC 很可能便是 R2 的技术根基。
如果真是这样,那可就有意思了。
你想啊,之前 Deepseek 的 R1 已经在推理能力上卷得 OpenAI 都有点慌了,现在又搞出个更高效的训练方法,这下一代模型得强成什么样?
当然,论文归论文,真正的产品还得看实际表现。但至少有一点可以肯定: 中国 AI 公司在「效率优先」这条路上,已经走出了自己的风格。
最后说两句看完这篇论文,我脑子里冒出来一个想法:AI 这场仗,可能真不是谁钱多谁就赢。
算法创新、工程优化与系统设计,这些“软实力”或许才是左右胜负的要害。Deepseek 此番的 mHC,便是个鲜活的例证。
简单来讲,这就是一场围绕“怎样用较少的资金,训练出更出色的模型”的竞赛。而且在这场竞赛中,中国 AI 公司正在彰显:节省资金,还能省出技术层面的含量。

参考来源
South China Morning Post: DeepSeek unveils new AI training methodHyperight: DeepSeek's mHC Architecture声明:本文内容 90% 左右为人工手写原创,少部分借助 AI 辅助,同时参考了 Contentany 的 AI 检测、同质化指标和人性化润色优化,以上所有内容和数据都经过本人严格审核和核对。