0. 论文信息
标题:Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
作者:Jingfeng Yao, Xinggang Wang
机构:Huazhong University of Science and Technology
原文链接:
代码链接:
1. 导读
Transformer架构的潜在扩散模型擅长生成高保真图像。然而,最近的研究揭示了这种两阶段设计中的优化困境:虽然增加视觉标记化器中每个标记的特征维度提高了重建质量,但它需要更大的扩散模型和更多的训练迭代来实现可比的生成性能。因此,现有系统经常满足于次优解决方案,或者由于标记化器内的信息丢失而产生视觉伪像,或者由于昂贵的计算成本而不能完全收敛。我们认为,这种困境源于学习无约束高维潜在空间的内在困难。为了解决这个问题,我们建议在训练视觉标记器时,将潜在空间与预训练的视觉基础模型对齐。我们提出的VA-VAE(视觉基础模型对齐变分自动编码器)显著扩展了潜在扩散模型的重建-生成边界,使得扩散变换器(DiT)能够在高维潜在空间中更快地收敛。为了充分发挥弗吉尼亚-VAE的潜力,我们建立了一个增强的DiT基线,它具有改进的训练策略和架构设计,称为LightningDiT。该集成系统在ImageNet 256x256代上实现了最先进的(SOTA)性能,FID分数为1.35,同时通过在短短64个时期内达到FID分数2.11展示了非凡的训练效率-与原始DiT相比,收敛速度提高了21倍以上。
2. 效果展示
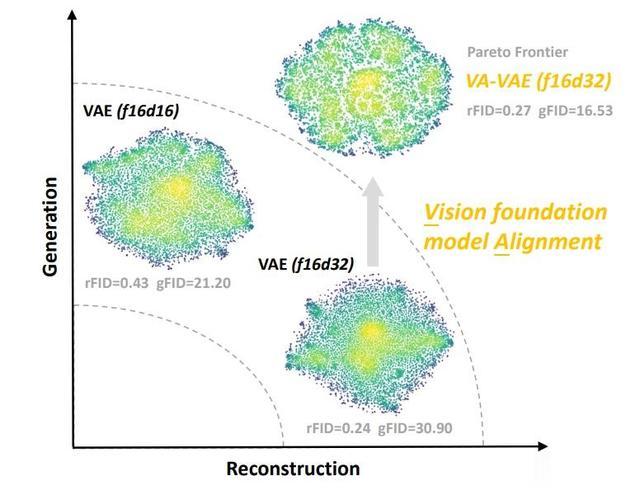
隐式扩散模型中的优化困境。在隐式扩散模型中增加视觉分词器的维度可以增强细节重建,但会显著降低生成质量。

潜在扩散模型的重建-生成。VA-VAE改进了高维潜在特征分布。通过与视觉基础模型对齐,我们扩展了潜在扩散模型中重建和生成之间的前沿。
生成结果:

3. 主要贡献
拟议的 VF 损失有效地解决了潜在扩散模型中的优化困境,使得使用高维分词器进行 DiT训练的速度提高了 2.5 倍以上;
该集成系统在仅64个训练周期内达到2.11的FID,与原始DIT相比,收敛速度提高超过21倍:
该集成系统在ImageNet-256图像生成上达到了最先进的FID分数1.35。
4. 方法
如图3所示,我们的架构和训练过程使用VO-GAN模型架构具有连续隐空间,受KL损失约束。我们的主要贡献在于设计视觉基础模型对齐损失,即VF损失,它在不改变模型架构或训练管道的情况下极大地优化了隐空间,有效地解决优化困境。
VF损失由两个部分组成:边际余弦相似度损失和边际距离矩阵相似度损失。这些部分被精心设计成一个简单、可插拔的模块,与VAE架构解耦。我们将在下面详细解释每个部分。

5. 实验结果


6. 总结 & 未来工作
本文主要关注扩散系统中的优化困境。为了解决这个问题,我们提出了VA-VAE,这是一种与视觉基础模型对齐的VAE,以及LightningDiT,这是一种结合了先进设计策略的优化DiT。在VA-VAE中,VF损失函数包括边际余弦相似性和距离矩阵损失-使VAE 的潜在空间与可视化模型保持一致,从而产生更均匀的特征分布和高达 2.8 倍的收敛速度。通过 Light-ningDiT,我们整合了先进的训练技术和架构改进,以实现更快的 DiT 融合。将 VA-VAE (rFID=0.28)的高重建能力与 Light-ningDiT 的快速收敛相结合,我们的方法在lmageNet 256 上实现了最先进的 1.35 FID。此外,我们的方法在仅使用64个epoch的情况下实现了2.11 FID,比原始DiT提高了21.8倍的速度。据我们所知,这是第一次有隐式扩散系统在无需额外训练成本的情况下实现优越的重建和生成性能。我们希望我们的工作能帮助后续对隐式扩散系统的研究。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。