Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models
Yinlin Deng1, Chunqiu Steven Xia1, Haoran Peng 2, Chenyuan Yang 1, Lingming Zhang 1
1University of Illinois Urbana-Champaign,2University of Science and Technology of China
引用
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. 2023. Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models. In Proceedings of ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2023)
论文:https://dl.acm.org/doi/abs/10.1145/3597926.3598067
摘要
近年来,深度学习系统在研究和日常生活中的使用率急剧上升。这些系统通常基于TensorFlow和PyTorch等流行的深度学习库构建。因此,检测这些深度学习库中的缺陷对于确保系统的有效性和用户安全至关重要。然而,由于深度学习程序的输入必须符合编程语言的语法和语义规则以及API的输入限制,传统的模糊测试技术在应对此类深度学习库时通常效果有限。为了克服现有的局限性,作者提出了TitanFuzz。它直接利用大语言模型生成用于深度学习库模糊测试的输入程序。实验结果表明,TitanFuzz在TensorFlow/PyTorch上的代码覆盖率比现有最先进的模糊测试工具高出30.38%/50.84%。此外,TitanFuzz成功检测到65个错误,其中41个已被确认为新发现的错误。
1 引言
深度学习(Deep Learning,DL)技术在自动驾驶、医疗保健和金融等行业正不断取得突破性的进展。这些系统的构建依赖于TensorFlow和PyTorch等深度学习库,开发者通过组合这些库所提供的API(通常是Python语言)来创建模型和执行计算任务。鉴于这些深度学习库中缺陷检测和修复的重要性,研究人员已经运用了多种自动化缺陷发掘技术来对它们进行测试和分析,其中模糊测试(Fuzzing)是一种流行的方法,它涉及生成大量的输入数据并输入到库中以寻找潜在的缺陷。
关于深度学习库的模糊测试任务主要分为两类:API级别的模糊测试和模型级别的模糊测试。API级模糊测试专注于对单个库API进行测试,通过为每个目标API生成多种不同的输入来发现潜在的崩溃或结果不一致问题。而模型级别模糊测试则专注于生成多样化的完整深度学习模型,并通过比较不同后端上的模型输出来寻找潜在的缺陷。虽然模型级别和API级别模糊测试在发现缺陷方面已经显示出效果,但它们仍然存在一些限制:
缺乏多样化的API序列。目前的API级别模糊测试工具主要关注于单独对每个深度学习库API进行测试。这些工具试图通过简单的变异规则生成多种不同的输入来针对特定API进行测试。然而,这些输入通常仅由单行代码构成(如随机初始化一个具有特定数据类型和大小的张量),无法揭示由链式API序列引起的错误。尽管模型级别的模糊测试工具可能用于测试API序列,但这些技术的变异规则通常存在严格的限制。因此,模型级别的模糊测试工具仅能覆盖有限模式的有限API集;无法任意生成代码。由于深度学习库API对用户暴露的是Python语言,而Python并非静态类型语言,因此直接获取输入和输出参数类型较为困难。此外,库API通常处理输入张量,如果张量的形状不匹配(例如,矩阵乘法时维度不匹配),则可能导致运行时错误。因此,现有的模糊测试工具无法全面探索深度学习库存在的巨大搜索空间。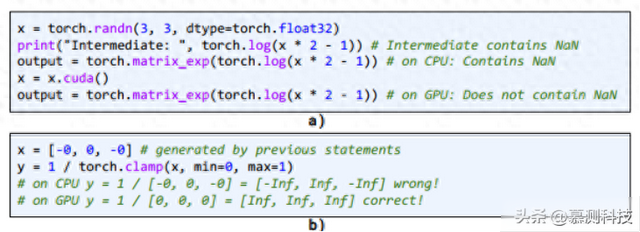
图1:深度学习库中的bug
图1(a)展示了一个在PyTorch中通过API序列揭示出的错误实例。代码通过创建一个随机输入并调用log API来生成一个中间变量。对于负数输入,log函数会产生NaN值。按照理论,应用matrix_exp后,结果也应包含NaN值。但在GPU上运行这段代码时,并未出现任何NaN值。更有趣的是,如果直接将含有NaN的中间张量传递给matrix_exp,而不是通过log API,那么在GPU上的这种不正确行为就无法复现。这个错误仅在执行API序列时由于同步错误而被触发。先前的API级模糊测试工具无法检测到此错误;模型级别的模糊测试工具同样难以发现此错误,因为在构建深度学习模型时,log函数后紧跟matrix_exp的情况很少见。
图1(b)展示了一个在PyTorch中通过先前模糊测试工具难以发现的错误案例。该错误发生是因为clamp函数在CPU上未能将负零转换为正零。尽管这个错误仅涉及一个API,但由于“负零”与“零”非常接近,传统技术无法有效识别。
作者提出了TitanFuzz —— 这是第一个利用大语言模型(Large Language Models,LLMs)对深度学习库进行全自动模糊测试的方法。如前所述,直接应用传统的程序合成方法生成语法/语义有效的深度学习程序具有不小的挑战。此外,深度学习库API往往涉及复杂的输入/形状约束,这些约束在没有额外人工修改的情况下很难得到满足。大语言模型因此成为了一个自然而合适的解决方案,它们基于Transformer架构,支持“自回归生成”或“填充生成”,并利用数十亿个token进行训练,以生成类人的程序。现代的大语言模型在其训练语料库中包含了众多使用各种深度学习库的代码片段(例如,GitHub上超过40万个TensorFlow/PyTorch项目),这使得它们能够隐式地学习Python的语法/语义以及深度学习API的复杂类型/约束,从而直接生成和变异出有效的深度学习程序,以进行深度学习库的模糊测试。
在TitanFuzz中,作者首先利用大语言模型和分步输入提示词来生成模糊测试的种子程序。为了进一步丰富测试程序的库,作者采用进化策略,利用大语言模型自动变异种子程序以产生新的测试程序。变异过程使用多个变异操作符,这些操作符设计用于利用填充LLM来替换种子程序中的一部分代码。为了生成更复杂和多样的API调用关系,作者设计了一个适应度函数,该函数根据数据依赖深度和唯一库API的数量来优先选择种子或变异的测试程序。最后,作者使用差分测试在不同的后端上执行生成的测试程序以检测错误。图1中的两个错误都无法被任何先前的深度学习库模糊测试工具检测到,但它们却能够被TitanFuzz检测到,并被开发者确认为新的错误。作者基于Codex和InCoder构建该技术,因为它们分别显示了在生成和填充任务方面的优秀能力。此外,作者在两个最受欢迎的深度学习库:TensorFlow和PyTorch上进行了评估。
总的来说,本文的主要贡献是:
本研究为模糊深度学习库开启了一个新的维度,即直接使用大型语言模型作为生成引擎,首次证明大语言模型能够直接执行基于生成和基于变异的模糊测试。另外,该方法可以轻易扩展到其他应用领域的软件系统(如编译器、解释器、数据库系统、SMT求解器以及其他流行库);作者实现了TitanFuzz,这是一个针对深度学习库的完全自动化的模糊测试工具。首先,作者利用擅长生成的大语言模型Codex生成高质量的种子输入,然后结合擅长填充式的大语言模型InCoder和进化算法,指导生成更多有效多样的深度学习程序;作者对两个最受欢迎的深度学习库:PyTorch和TensorFlow进行了评估。结果显示,TitanFuzz能够覆盖PyTorch和TensorFlow上的1329/2215个API,覆盖率分别为20.98%/39.97%,在API覆盖率上比最先进的模糊工具提高了24.09%/91.11%,在代码覆盖率上提高了50.84%/30.38%。此外,TitanFuzz能够检测到65个错误,其中41个被确认是新发现的错误。作者还进一步进行了广泛的消融实验,验证了TitanFuzz中组件设计的有效性。2 本文方法

图2:TitanFuzz的总体框架
图2展示了TitanFuzz的总体框架。对于任何给定的目标API,TitanFuzz首先利用生成式大语言模型生成一系列高质量的模糊测试种子程序。对于生成的种子,作者进一步采用进化模糊测试算法,迭代生成新的代码片段。在每次迭代中,作者从种子库中选择一个具有高适应度评分的种子程序。作者使用不同的变异操作符替换所选种子的部分内容,以产生包含有占位符(或者说遮蔽)的输入。变异操作符是使用“多臂老虎机”算法选择的,目的是生成尽可能多的有效和唯一的变异输入。作者利用填充式大语言模型来填充之前被占位符占据的区域(遮蔽区域)来生成新的代码。对于每个生成的变异体,作者首先过滤掉任何执行失败的变异体,并使用适应度函数对每个变异体进行评分。然后,作者将所有生成的变异体放入种子库中,对于未来的变异轮次,作者优先选择具有更高评分的种子,从而生成一组更丰富的高质量代码片段用于模糊测试。最后,作者在不同的后端(CPU和GPU)上执行所有生成的程序,以识别潜在的错误。
2.1 初始种子生成

图3:Codex生成样例
为深度学习API生成初始的种子程序,作者首先使用分步式的提示词(prompt)向Codex模型提出查询,并从中抽取多个完成的样本。Codex模型通过因果语言建模进行训练,其目的是根据之前的生成预测下一个token。假设给定一个训练序列 T = {t1, t2, …, tn},其中 T<m = {t1, t2, …, tm−1} 表示到目前为止生成的token序列(m ≤ n),而P是Codex模型输出生成一个特定token的概率。Codex的损失函数定义如下:
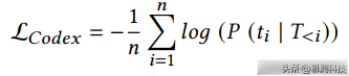
图3展示了构建提示词和模型输出的示例。作者将目标库(例如TensorFlow)和目标API签名(例如tf.nn.conv2d(input, filters, …))包裹在提示词中。API签名是通过一个HTML爬虫自动从API文档中提取的。作者还设计了一个分步指令(如图3中的Task 1、Task 2、Task 3)来提高模型的性能。作者指导模型依次执行三个任务:1)导入目标库;2)生成输入数据;3)调用目标API。作者构建的提示词作为Codex的初始输入,从Codex中采样来获得原始的种子程序。
2.2 进化模糊测试算法

算法1描述了TitanFuzz的核心进化模糊测试算法。作者首先使用Codex生成的种子初始化种子库(第2行)。种子库包含了迄今为止生成的代码片段列表。随后,作者为每个变异操作符设定了一个先验分布,这些分布将在主循环中用于选择变异操作符(第3行)。接着,进入生成循环,根据适应度评分选择一个当前的种子进行变异(第5行)。在选择种子时,作者首先优先考虑具有更高适应度评分的种子,即选择适应度评分最高的前n个种子。在这些种子中,作者对其进行softmax操作以确定选择每个种子的概率。
除了种子选择之外,作者还决定将哪个变异操作符应用于种子(第6行)。由于在不同目标API中,能够帮助模型生成有效和独特变异的变异操作符可能不同,作者使用“多臂老虎机”算法动态学习操作符的优先级策略。每个变异操作符将用特殊标记遮蔽当前种子程序的一个或多个片段(第7行)。然后将遮蔽的输入喂入InCoder模型以生成填充遮蔽区域的代码片段(第8行)并采样。对于生成的每个样本,作者运行并静态分析代码片段(第9行)。具体来说,作者确定可以编译的代码片段(Valid Samples)。然后,作者根据变异操作符产生的有效和无效样本数量更新其后验分布(第10行)。对于每个有效样本,作者根据定义的适应度函数(Fitness Function)计算适应度分数,该函数旨在优先考虑具有不同API之间交互的多样化种子,从而能够发现更多潜在的缺陷。使用适应度分数,作者将这些样本添加到种子库中,用于下一轮的种子选择(第12行)。最后,当时间预算耗尽时,则会终止生成并返回种子库,包含使用目标API的多个独特的代码片段。
2.3 测试预言
在生成循环之后,作者利用差分测试通过在两个独立的后端上运行生成的代码片段来检测错误。差分测试(Differential Testing),也称为比较测试或差分分析,是一种软件测试方法,用于发现软件在处理不同输入时行为不一致的问题。这种方法通过比较同一软件的两个或多个版本(例如,不同版本、不同编译器编译的版本或者不同实现)在处理相同或相似输入时的输出差异来检测软件中的错误或异常。简而言之,作者在CPU和GPU上执行生成的代码片段,记录所有变量,包括中间变量,并检测潜在的错误。作者主要关注以下几种错误类型:
计算错误。比较两个执行后端上所有中间变量的值,并能够在值存在显著不同时发现计算错误。由于某些计算的非确定性性质导致在CPU或GPU上的结果略有不同,作者遵循先前的研究,并使用一个容差阈值来检查值是否显著不同。计算值之间的差异可能表明在库API的不同后端实现之间或不同API之间的潜在语义错误。
崩溃。在程序执行过程中,作者还检测到意外的崩溃,例如段错误、终止、INTERNAL_ASSERT_FAILED错误等。此类崩溃表明未能检查或处理无效输入或边缘情况,可能导致安全风险。
3 实验评估
3.1 实验设置
研究问题。在本文中,作者研究以下研究问题:
RQ1:TitanFuzz与现有深度学习库模糊测试工具的性能对比如何?
RQ2:TitanFuzz的关键组件对其效能有何贡献?
RQ3:TitanFuzz是否能够检测到真实环境中的错误?
目标深度学习库。作者将PyTorch(版本1.12)和TensorFlow(版本2.10)作为目标深度学习库,因为它们是两个最受欢迎的深度学习库,并且在之前的深度学习库测试工作中得到了广泛的研究。
模糊预算。默认情况下,作者为两个库的所有可能API设置了每API一分钟的模糊预算。对于RQ2,作者在每个库中随机抽取了100个公开API,并进行了五次消融研究实验,报告了平均值。对于RQ3,作者将模糊预算扩展到了每API四分钟,以最大化错误发现。
环境。作者使用了一个具有256GB RAM的64核工作站,运行Ubuntu 20.04.5 LTS系统,并配备了4个NVIDIA RTX A6000 GPU。另外作者使用coverage.py来测量Python代码的覆盖率。
3.2 度量指标
检测到的错误数量。遵循先前关于模糊测试深度学习库的研究,作者报告了检测到的错误数量。
代码覆盖率。代码覆盖率在软件测试中被广泛采用,最近在深度学习库/编译器测试中也得到了应用。作者遵循最近的深度学习库模糊测试工作(如Muffin和FreeFuzz)并使用行覆盖率。
覆盖的API数量。遵循先前的工作,作者报告了覆盖的API数量,作为深度学习库测试充分性的另一个重要指标,因为深度学习库通常包含成千上万的API。
生成的唯一有效程序数量。生成的程序被认为是有效的,如果该程序在没有异常的情况下成功执行,并且至少调用了一次目标API。作者移除了已经生成的代码片段,只考虑唯一的程序。
执行时间。由于TitanFuzz使用大语言模型作为生成引擎,它可能需要比现有模糊测试工具更长的时间。因此,作者也记录了执行时间。
RQ1 对比现有深度学习库模糊测试工具

表1:API覆盖率对比
作者将TitanFuzz与测试深度学习库的尖端模糊测试工具进行了比较,包含API级别的模糊测试工具和模型级别的模糊测试工具。表1展示了所有研究技术在TensorFlow和PyTorch上覆盖的库API数量。可以观察到TitanFuzz能够在TensorFlow和PyTorch中覆盖2215和1329个API,与最先进的技术的API覆盖数量相比达到最高。与表现最佳的基线DeepREL相比,TitanFuzz将覆盖的API数量增加了91.11%和24.09%。与模型级别的模糊测试技术(LEMON和Muffin)相比,TitanFuzz在覆盖的API数量方面能够大大超过它们。
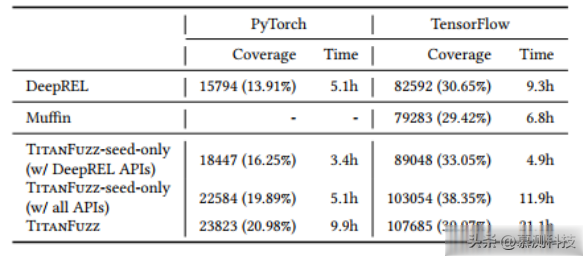
表2:行覆盖率对比
表2展示了整体的代码覆盖率。作者根据API覆盖率选择了表现最佳的API级别和模型级别的基线DeepREL和Muffin两个模糊测试工具,并按照它们的默认设置运行。作者观察到TitanFuzz在PyTorch和TensorFlow上显著优于DeepREL和Muffin,达到了20.98%和39.97%的行覆盖率。与DeepREL相比,TitanFuzz在PyTorch和TensorFlow上分别提高了50.84%和30.38%的覆盖率。但是TitanFuzz的时间成本较高,因为它测试的API数量较多且使用了大语言模型。
RQ2 关键组件效能分析
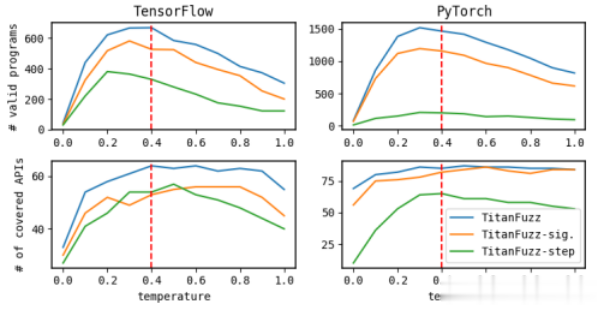
图4:种子生成趋势
种子生成。图8展示了不同temperature和提示词下API覆盖率和独特有效程序的数量。TitanFuzz使用之前提出的默认策略,其中提示词包含有三个步骤:首先导入深度学习库,生成输入,然后调用目标API。作者还将完整的API签名包含在提示中,以提供语法指导。TitanFuzz-step删除了前两个步骤(导入库和生成输入数据)并只要求Codex从指定的库版本调用目标API。首先,作者发现使用默认采样温度值0.4(红色虚线)在生成更多有效程序的同时也覆盖了PyTorch和TensorFlow上更多独特的API。其次,通过在提示中添加分步指令(首先导入库并生成输入数据),可以显著提高Codex在生成独特有效程序数量和API覆盖率方面的性能,这是首次展示了提示工程在模糊测试中的实力。此外,通过在提示中添加API签名,向Codex提供了有关输入参数空间的宝贵信息,帮助Codex生成更多有效的程序。

表3:操作符选择算法评估
操作符选择算法。作者对比了默认的汤普森采样(TS)操作符选择算法与一个均匀随机选择基线(Random)。表3总结了结果。TS算法有助于生成更多独特的有效程序并在两个库中实现更高的代码覆盖率,与随机策略相比。具体来说,TS策略可以为TensorFlow生成大约2倍的独特有效程序;在PyTorch中,尽管TS可以生成的独特程序总数较少,但它仍然可以产生12.5%的有效程序,展示了基于MAB的操作符优先排序的有效性。

表4:codex与incoder生成效率对比
Codex vs InCoder。最后,作者在表4中也仔细研究了Codex和InCoder在生成独特测试程序和每个独特程序的时间成本方面的贡献。作者观察到,尽管Codex可以提供高质量的种子程序,但与较小的InCoder模型相比,它相对较慢,这展示了利用填充式大语言模型和进化变异来进一步补充强大但成本较高的生成式大语言模型在模糊测试方面的优势。
RQ3 错误检测能力分析

表5:检测到的缺陷
表5总结了TitanFuzz检测到的错误统计。总计,TitanFuzz检测到65个错误,其中53个被确认(包括19个崩溃和34个计算错误),包括41个之前未知的错误(其中8个已被修复)。在53个被确认的错误中,只有9个也可以被之前的API级别模糊测试工具找到,而模型级别模糊测试工具一个都找不到。值得注意的是,有10个被确认的错误是通过直接使用Codex生成的种子而没有进行任何变异发现的。
转述:杨鼎