黄仁勋在Computex 2026上掏出Nemotron 3 Ultra的时候,很多人只记住了"5500亿参数"这个数字。但如果你真想知道这模型为什么能在推理吞吐量上碾压同类,光看参数量是远远不够的。今天我们把它拆开,一层一层看。
⚙️ 第一层:参数规模的障眼法5500亿总参数,550亿激活参数——这两个数字的差距才是理解Nemotron 3 Ultra的关键。这是一个MoE(Mixture-of-Experts)架构,意味着每次推理时只有1/10的参数被激活。什么概念?你调用它的时候,实际消耗的计算量大约相当于一个550亿参数的稠密模型,但享受了5500亿参数的知识容量。
直接对标:GLM-5.1-754B激活40B参数,Kimi-K2.6-1T激活32B参数。Nemotron 3 Ultra激活55B参数,在MoE模型里算是"大激活"的设计,这让它单次推理的质量更高,但代价是对显存的要求也更大——量化后最低需要300GB+显存。这东西不是给个人玩家用的。
第二层:Mamba+Transformer混合——不是缝合,是化学反应这可能是Nemotron 3 Ultra最让我兴奋的技术选择。纯Transformer的问题是注意力机制的O(n²)复杂度,在长上下文场景下计算量爆炸。纯Mamba的问题是在需要精确回溯的场景中不如Transformer靠谱。
NVIDIA的方案是混合使用:在需要全局精确检索的层用Transformer注意力,在需要高效序列处理的层用Mamba的状态空间模型。这种设计让模型在100万token的超长上下文中既保持了检索精度(RULER基准94.2%),又没有让推理速度崩掉。
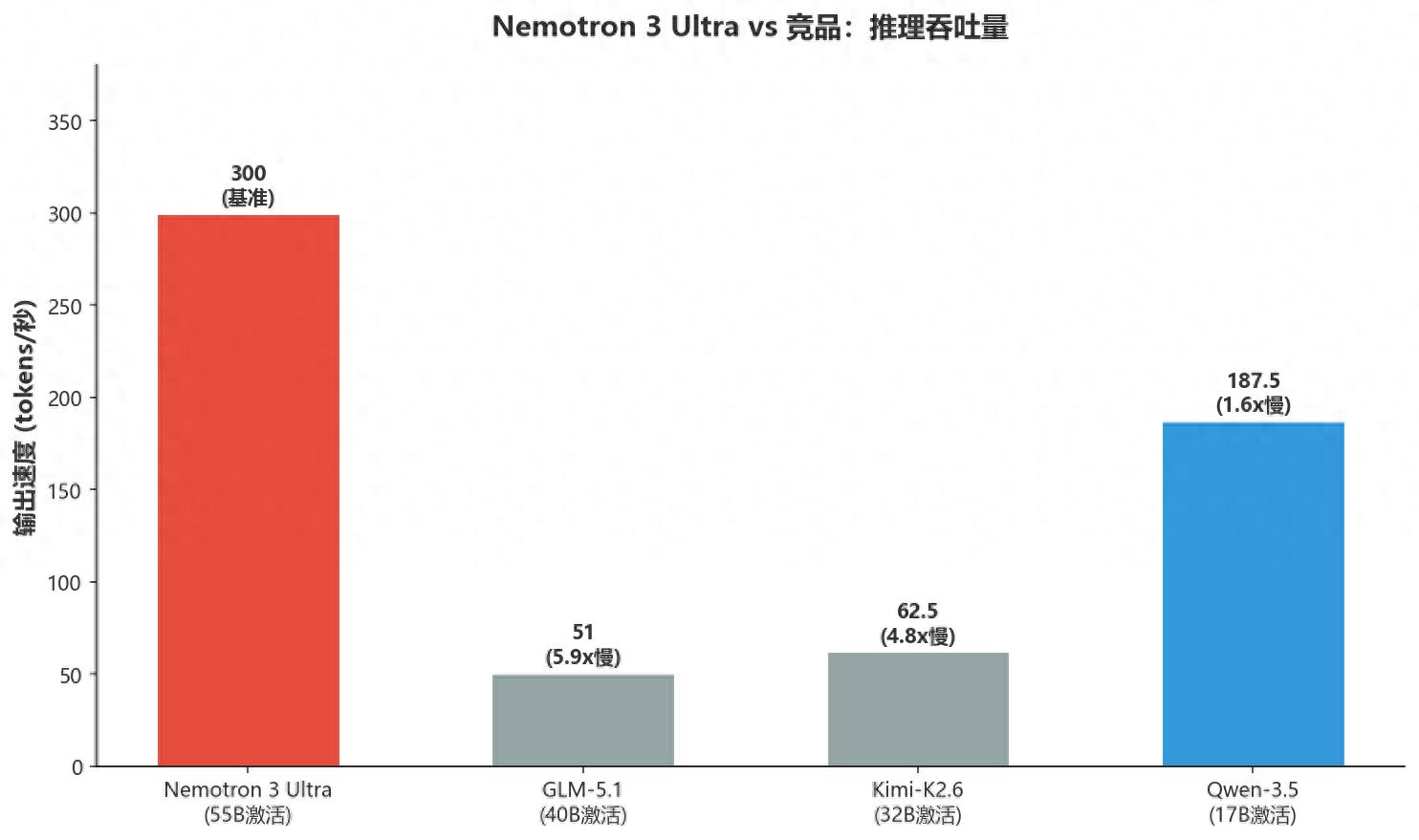
实测数据:Nemotron 3 Ultra输出速度300+ tokens/秒,而GLM-5.1只有51 tokens/秒(5.9倍差距),Qwen-3.5是187.5 tokens/秒(1.6倍差距)。这个速度优势很大程度上来自Mamba层的线性复杂度推理。
第三层:LatentMoE——在隐空间做专家路由传统MoE的专家路由是在token表征空间做的,Nemotron 3 Ultra的LatentMoE则是在隐空间做路由决策。好处是什么?路由决策更平滑、更少噪声,专家之间的协作更自然。这听起来是微小的架构变化,但在实际训练中能显著减少MoE常见的"路由崩溃"问题——即所有token都涌向同一个专家。
⚡ 第四层:MTP多token预测——推理加速的秘密武器大多数自回归模型每次只预测下一个token。Nemotron 3 Ultra的MTP(Multi-Token Prediction)层可以同时预测多个token,然后通过原生推测解码(speculative decoding)来加速推理。
打个比方:普通模型像一个字一个字地写文章,MTP像是一次写半句话然后回头验证。验证通过的部分直接采纳,验证不通过的部分重新生成。在实践中的效果就是——你在速度上看到了300+ tokens/秒的惊人数字,同时精度不打折。
第五层:NVFP4预训练——4位浮点直接训这是Blackwell架构带来的红利。传统做法是FP16或BF16训练,训完再量化到8bit或4bit部署。Nemotron 3 Ultra直接在NVFP4精度下预训练,跳过了训后量化带来的精度损失。
这是个大胆的选择。4位精度训练意味着每个参数只占半个字节,梯度信息的表示范围极窄。但NVIDIA显然在Blackwell的FP4硬件支持上做了深度优化,最终结果是在多项基准上与最先进开源模型精度持平。
第六层:后训练三件套——SFT+RL+MOPD预训练只是打底,后训练才是拉开差距的关键。Nemotron 3 Ultra的后训练管线分三步:
SFT(监督微调):用高质量指令数据让模型学会"听话"。训练数据包括173B token的代码数据集(Nemotron-Pretraining-Code-v3,截至2025年9月30日的GitHub最新代码),以及法律、道德场景等专用合成数据集。
RL(强化学习):提升推理和决策质量。NVIDIA还发布了专门的GenRM(生成式奖励模型),用于RLHF中对齐人类偏好。
MOPD(多教师在策略蒸馏):这是NVIDIA自创的蒸馏方法。多个"教师"模型指导一个"学生"模型,但在策略空间(on-policy)做蒸馏而非简单的输出匹配。这比传统的知识蒸馏更高效,能保留更多教师模型的推理能力。
第七层:性价比才是杀手锏所有这些技术选择的最终指向只有一个:推理成本。NVIDIA宣称Nemotron 3 Ultra的推理成本比头部竞品低30%,而输出速度快2-5倍。在企业级部署场景中,这意味着同样的预算可以服务3-5倍的请求量。
而且,这模型是完全开源的——权重、训练数据集、训练配方全放出来了。Apache 2.0许可,商用无限制。这种"我比你强还比你便宜还开源"的打法,对闭源模型厂商来说简直是降维打击。
我个人觉得,Nemotron 3 Ultra的真正意义不在于它比谁强多少,而在于它展示了一种新的AI模型设计范式:不追求单纯堆参数,而是通过架构创新(Mamba+Transformer混合)、训练创新(NVFP4预训练)、推理创新(MTP加速)三条线同时突破,实现"又快又好又便宜"。这才是2026年大模型竞争的核心逻辑。
数据来源:NVIDIA Research官方页面 research.nvidia.com/labs/nemotron/(2026年6月4日);explainx.ai Computex 2026完整回顾(2026年6月1日)