
2026 年上下文工程已成为 AI 大模型应用的核心战场,行业一边竞相扩容百万级长上下文窗口,一边普遍深陷 Token 消耗失控、多轮 Agent 对话上下文污染与溢出的现实困境;当大家还在讨论长上下文到底该怎么省、RAG 到底该怎么加的时候,LinkMind 这次选择先解决一个更现实的问题:当前用户上下文体量较大,大模型单次处理无法充分理解全部信息。是否可以完整提取上下文中用户的实际问题,再精简保留关键有效内容,以便模型更清晰地理解与处理。
这正是本次版本更新的核心目标。我们聚焦两大核心原则:简单易用(插件)、高效实用(反向RAG),让 Token 节省能力再攀新阶:
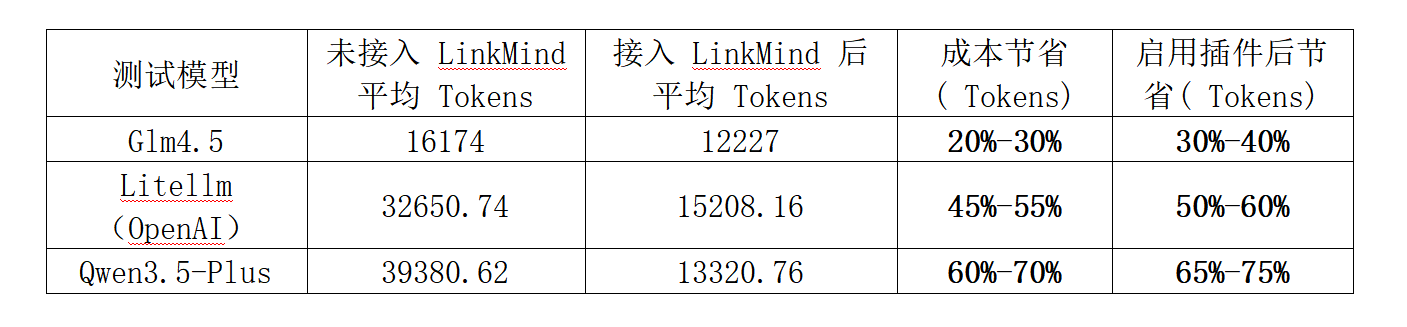
很多产品做“上下文优化”,停留在一个按钮、一段脚本,或者一次性的摘要能力。但 LinkMind 这次不是把压缩做成一个临时动作,而是把它正式做进了 OpenClaw 的上下文引擎里,让它从“偶尔可用”,变成“默认在线”。
先说结论:这不是一个普通插件这次的linkmind-context,并不是一个只负责展示信息的轻插件,也不是一个简单的搬运工。
它本质上是一个原生的 OpenClaw Context Engine 插件。
它可以自动嵌入到 OpenClaw 的上下文引擎槽位里,在会话运行过程中增强上下文压缩能力:
根据文本内容,自动判断是否压缩
将当前会话消息发送到 LinkMind 的压缩接口
拿回压缩后的结果后,直接回写到会话记录
尽量不打断用户当前工作流,不让用户手动做“整理上下文”
这背后价值非常直接:不是让用户学会怎么省 Token,而是让LinkMind 全自动去省。
对于长对话、连续任务、多轮代理调用来说,这一点尤其关键。因为真实使用里最贵的,往往不是某一次提问,而是越聊越长、越跑越重的上下文。
(一)什么是“反向 RAG”?反向 RAG 的方向,是向内整理信息。它回收、提炼、重写已经存在于会话里的内容,把低密度上下文压成高密度上下文。
但在很多真实场景里,成本暴涨不一定来自 “外部知识不够”,反而来自另一个问题:会话内部已经产生了太多信息,但这些信息没有被重新整理。
这就是 LinkMind 这次强调 “反向 RAG” 的原因。
传统 RAG 的方向,是向外找信息。
它从知识库、文档库、向量库里把相关内容拉回来,补给模型,让模型 “知道得更多”。这当然重要,LinkMind 本身也已经具备 RAG 能力。
一句话概括就是:
反向 RAG 负责向内收上下文,传统 RAG 负责向外取知识。
而这两件事并不冲突,反而应该是下一代长上下文产品里的两条腿。
(二)反向 RAG 的真正意义,不只是省 Token1)反向 RAG 更大的意义在于,它在重新定义长上下文产品的工作方式:
过去的思路是:
上下文不够,就继续加;
上下文太长,就人工删;
删完不够,再补一个摘要。
LinkMind 这次的思路是:
上下文一旦变长,就让系统自动判断;
一旦超过阈值,就自动压缩;
压缩不是简单删,而是保留结构、重写内容、回写会话;
最后把 Token 预算,留给真正值得保留的信息。以此带来非常现实的结果:
长对话更能持续:不容易越聊越臃肿
代理任务更能连续:上下文不会很快把窗口吃满
Token 利用率更高:预算更集中在关键内容,而不是冗余表达
2)反向RAG不是替代传统 RAG,是补上它缺的那一块
今天很多人谈 RAG,更多还是在谈“怎么把外部知识接进来”,但真正长期使用系统的人,很快会发现另一个问题同样棘手:上下文不是只会变多,它还会变旧、变散、变重。传统 RAG 解决的是“知识从哪里来”,反向 RAG 解决的是“会话怎么继续活下去”。
所以,LinkMind 这次强调插件和反向 RAG,本质上不是在做两个孤立功能,而是在补齐一个完整系统的两端:
对外,能接知识、接模型、接生态
对内,能整理上下文、压缩历史、提升密度
这才是一个长对话系统真正走向可持续的基础。
(三)那LinkMind 怎么做的?很多人一提到压缩上下文,第一反应就是删消息、截断消息、粗暴裁剪。
但 LinkMind 当前这版实现,明显不是这个思路。
它更像是在做一件事:保留对后续推理真正有价值的结构,把冗长表达压缩掉。
从当前实现来看,这套机制有几个非常关键的特点:
1.最近对话优先保留,历史对话优先压缩
服务端压缩接口不会把整段历史一刀切,而是优先保留最近消息,把更早的消息作为压缩重点。对连续任务来说,这意味着模型仍然能保留对“当前上下文状态”的敏感度,而不是每次压缩后都像重新开了一次新会话。
2.系统消息尽量不动,避免把规则压坏
当前实现里,系统角色消息不会进入压缩重点区域。这一点很关键,因为系统消息往往承载的是规则、身份、边界与执行约束。把这些内容压坏,省下来的 Token 可能马上会在行为漂移上加倍还回去。
3.压缩后不是另起一份摘要,而是原位重写会话记录
这才是插件真正有分量的地方。
插件拿到压缩结果之后,不是简单地把摘要放到旁边,而是通过 OpenClaw 的 transcript rewrite 能力,把可映射的历史消息按条回写。这样做的好处是:
会话结构还在
上下文链路还在
用户工作流还在
但上下文体积已经降下来了
这就是“反向 RAG”最值得强调的一点:
它不是另开一个记忆层,而是直接回到会话内部,对已有上下文做回收式增强。
(四)这么做的作用何在?更轻、更顺、更稳当如果“反向 RAG”只是一个概念,它很容易停留在 PPT 里。但这次 LinkMind 选择先把它放进插件里,意义就显现出来了。插件形态至少带来了三层现实价值:
第一层,是接入更轻
linkmind-context作为独立插件项目存在,本身就具备清晰的配置结构、上下文引擎声明和可分发能力。对于已经在 OpenClaw 生态里工作的用户来说,这不是重新学习一套系统,而是把 LinkMind 直接挂进现有工作流。
第二层,是运行更自然
插件不是在外面围观会话,而是在会话生命周期里工作:消息进入、对话结束、阈值触发、压缩执行、结果回写,整个流程是连贯的。
这意味着压缩不是一个“事后补救动作”,而是会话运行机制的一部分。
第三层,是生态位置更稳
单独做一个“伴侣工具”,用户会问:为什么一定要用你?
但如果把能力放进 OpenClaw 的原生上下文引擎层,价值就会变成:
你不是在旁边做辅助,而是在关键链路上提供能力。
这会让 LinkMind 的位置更靠前,也更难被替代。
还有一个容易被忽视的点:效果开始变得“可度量”很多上下文优化产品都有一个老问题:你感觉它在优化,但你很难知道它到底优化了多少。
LinkMind 这版已经把 Token 统计链路补了上来,可视化Token统计面板让消耗的节省趋势更直观。也就是说,压缩不再只是“体感更快”“似乎更省”,而是开始具备进一步量化和追踪的基础。
当一个能力可以被持续统计、持续观察,它才更有机会从“功能点”变成“产品能力”。
这对于后续做版本迭代、做宣发验证、都是非常重要的一步。
LinkMind 一站式“接入”,让你直接使用这次还有一个很值得注意的信号:LinkMind 不是只做了压缩接口,还在做OpenClaw 配置同步与注入。
简单说,就是在合适条件下,LinkMind 可以把自己的 provider/model 信息写入 OpenClaw 配置,同时也能把 OpenClaw 的主模型配置同步回 LinkMind 的配置侧。
先把环境准备好:
· 已启用插件功能的 OpenClaw 环境
· 可正常访问的 LinkMind 服务端点
从已发布包安装:
包发布后,用户可通过以下命令安装:

OpenClaw 会优先从 ClawHub 查找插件,若未找到则自动回退到 npm 源。
openclaw.json配置如下:

安装完成后,重启 OpenClaw 网关,即可。
于用户来说,简单、不用费心折腾,也是最直白的高价值。
结语当下行业都在追逐更大的上下文窗口、更强的模型能力与更多外部知识接入,而 LinkMind 本次更新之所以格外值得关注,正是因为它没有堆砌表面热闹的新功能,而是补齐了长上下文产品最底层、最现实的一块地基:插件能力决定了它能无缝融入真实生态,解决能不能用的问题;反向 RAG 则让长对话得以轻量化持续运行,解决能不能持续用的问题。一个负责打通接入链路,一个负责优化上下文减重,二者结合,让 LinkMind 成为能嵌进工作流、智能整理上下文、持续提升 Token 使用效率的长上下文基础能力层。
真正决定长上下文体验上限的,从来不是 “你能塞进去多少内容”,而是你能不能把已经产生的内容,整理得足够轻、足够稳、足够值钱。LinkMind 这次将插件与反向 RAG 深度融合,正是给出了最优解:不一味盲目扩容,而是先学会高效回收;不只会外部接入,而是开始内化优化;不让上下文越滚越臃肿,而是让它越跑越精简。这,就是长上下文产品该走的下一步,我们也将持续升级迭代,让你的 OpenClaw(龙虾)越用越强!
中间件项目已开源,欢迎大家交流体验
地址:
https://github.com/landingbj/LinkMind.git
